







一、全文内容介绍
-
简单介绍数据集
-
数据简单预处理
-
导入简单CNN模型
全文就是突出一个简单。。。๑乛◡乛๑
注:下文会备注一些相关的帖子,感谢很多人的分享,让我个菜鸡能摸索弄清楚。大家如果有问题,可以问在评论区提一下,如果我会肯定尽力解答;如有侵权我会迅速删除;内容可能会在后面的帖子中持续补充,正在入门ing。
二、简单介绍数据集
第一次看到数据集的时候很懵(..•˘_˘•..) 啥啥啥这都是啥
关于实验平台就那个经典绿图

关于故障,故障有很多种分法,比如内外圈、直径大小、3点钟或6点钟位置等等。。。大家可以看一下别人的详细帖子,这里不多介绍,不然偏题了。如图1所示,是我完全能理解的一个示意图,初次看到的时候简直整个人豁然开朗。
图1 数据分析图

注:图来源链接为【凯斯西储大学数据集介绍(CWRU)】-CSDN博客
看完这个图,第一眼记下来,过了几秒我又忘记了。。。所以我直接找了个10分类数据来做。
1、10分类数据下载
可以看一下在文件夹中的样子,我是直接下载的mat文件,下面是我改名字之后的文件,应该用的就是1797那个。。。可以不在意名字是什么,只要知道是个10分类就好了,等过一遍回头花时间琢磨就通了,来,继续往下走。

我给大家放一个百度云盘链接,大家需要可以下载,当然也是第一次在帖子里放链接,要是有啥问题或者过期了,评论发消息我看了就回复哈。为防意外,我把整理好的csv文件也放在网盘里,如果这一步暂时遇到问题,大家还可以往下继续(..•˘_˘•..)
百度云盘下载:
链接:https://pan.baidu.com/s/1VeBxKK8Rv1CawqNSx-9GSA
提取码:haha
2、10分类数据处理
来了来了,要上代码的时刻来了!这块代码主要参考如下链接:Python-凯斯西储大学(CWRU)轴承数据解读与分类处理-CSDN博客
- 查看mat文件
首先咱们查看一个mat文件,看看究竟是个啥样子
# 用Python读取第一个数据集IR007_0结果如下
from scipy import io as scio
mat_fileName = '105.mat'
data = scio.loadmat(mat_fileName ) # 读出来的数据是字典dict型
data
# 得出的结果如下(下面是结果展示!这是结果!)
'''
{'__header__': b'MATLAB 5.0 MAT-file, Platform: PCWIN, Created on: Mon Jan 31 13:49:59 2000',
'__version__': '1.0',
'__globals__': [],
'X105_DE_time': array([[-0.08300435],
[-0.19573433],
[ 0.23341928],
...,
[-0.31642363],
[-0.06367457],
[ 0.26736822]]),
'X105_FE_time': array([[-0.40207455],
[-0.00472545],
[-0.10663091],
...,
[ 0.31598909],
[ 0.35091636],
[ 0.03307818]]),
'X105_BA_time': array([[ 0.06466148],
[-0.02309626],
[-0.08852226],
...,
[ 0.09648926],
[ 0.08405591],
[-0.02015893]]),
'X105RPM': array([[1797]], dtype=uint16)}
'''如果看不懂,好,我们跳过去。我看array也晕,小问题,下面看数据量。
12w,是个很敏感的数字,记住它!
# 查看一下驱动端数据条数
data['X105_DE_time'].shape
# 将近12万条,也就是采集了近10秒的数据(这也是结果!)
# (121265, 1)- 加载10类数据
下面就是转为CSV文件的代码辣!
敲黑板!你要做的就是修改一个文件的位置,大家努力一下,比如我的文件位置是这样D:\\work\\Anaconda\\10class\\{file_names[index]}.mat,你的就不一定是了,如果巧了那就好巧,记得改哦๑乛◡乛๑
import numpy as np
import pandas as pd
from scipy.io import loadmat
# Assuming your filenames are as follows:
file_names = ['097','105', '118', '130', '169', '185', '197', '209', '222', '234']
data_columns = [f'X{filename}_DE_time' for filename in file_names]
# columns_name = [f'de_{filename}' for filename in file_names]
columns_name = ['de_normal','de_7_inner','de_7_ball','de_7_outer','de_14_inner','de_14_ball','de_14_outer','de_21_inner','de_21_ball','de_21_outer']
data_12k_1797_10c = pd.DataFrame() # 名称表示10类
for index in range(10):
data = loadmat(f'D:\\work\\Anaconda\\10class\\{file_names[index]}.mat')
dataList = data[data_columns[index]].reshape(-1)
data_12k_1797_10c[columns_name[index]] = dataList[:119808] # 121048 min: 121265
print(data_12k_1797_10c.shape)
data_12k_1797_10c好了,文件已经出来了,下面咱们绘制一下时序图。
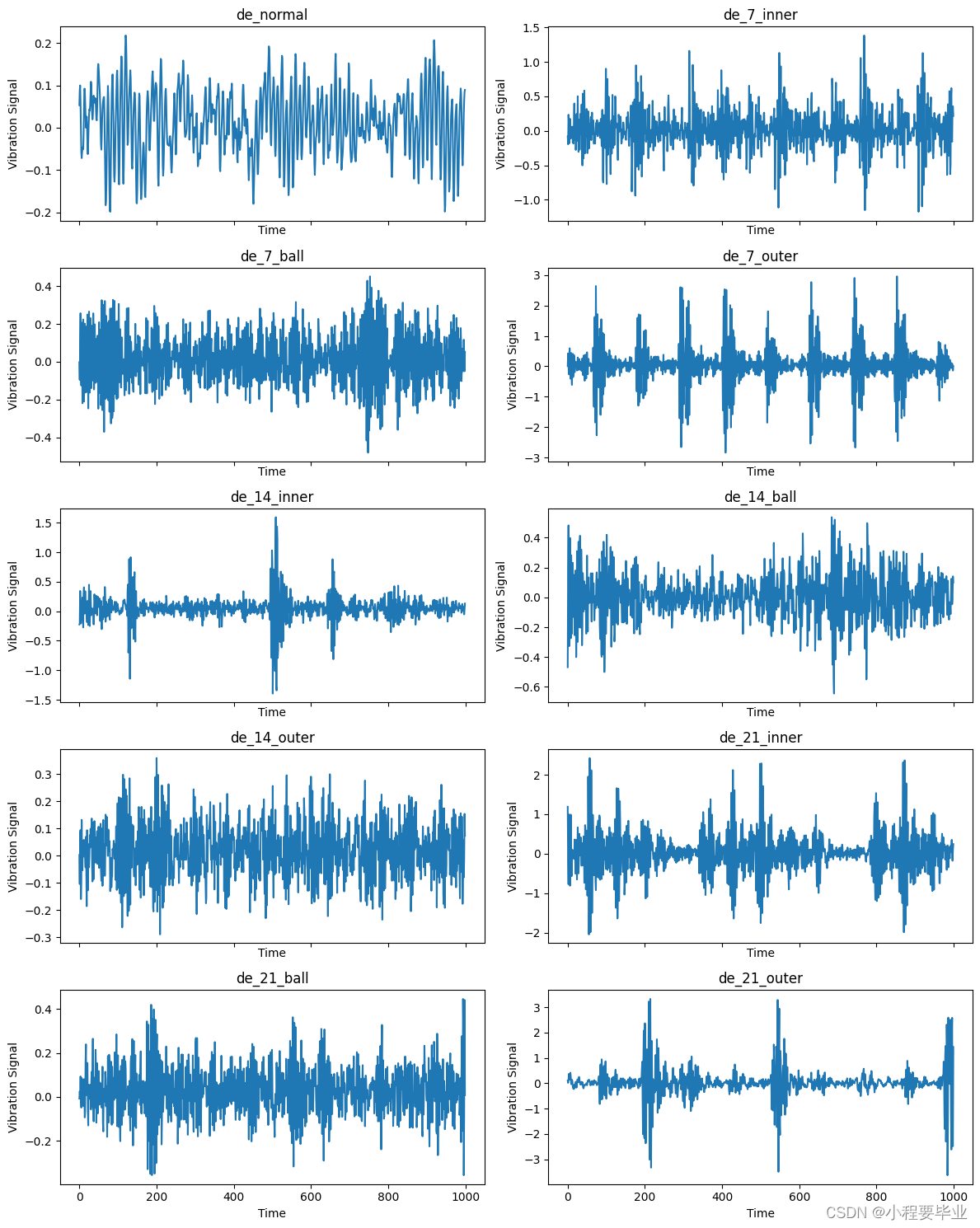
3、10分类数据时序图
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 读取CSV文件的前1000行
df = pd.read_csv('data_12k_1797_10c.csv', nrows=1000)
# 获取列名
columns = df.columns
# 设置子图布局
fig, axs = plt.subplots(5, 2, figsize=(12, 15), sharex=True)
# 将列名按顺序分配给子图
for i in range(5):
for j in range(2):
index = i * 2 + j
if index < len(columns):
axs[i, j].plot(df[columns[index]])
axs[i, j].set_title(columns[index])
axs[i, j].set_xlabel('Time')
axs[i, j].set_ylabel('Vibration Signal')
plt.savefig('sequence_chart/my_sequence_plot.png')
# 调整布局
plt.tight_layout()当当当,好了,得到十张图,大家好好欣赏一下啦!我的长这样,大家应该都一样哈哈哈
 三、1D-CNN简单实验
三、1D-CNN简单实验
先上代码,代码来源是知乎大佬的帖子(膜拜大佬),帖子如下:基于1D-CNN、2D-CNN,LSTM和SVM的一维信号分类 - 知乎 (zhihu.com)
关于CNN的介绍大家去看其他帖子。利用CNN做故障的分类预测,主要有两种方法,①是做信号切割后直接输入CNN模型,②是做时频分析,将时频谱图输入CNN。1D-CNN是属于前一种。
1、数据处理部分
import pandas as pd
import numpy as np
# 读取 CSV 文件
df = pd.read_csv('data_12k_1797_10c.csv')
# 定义信号间隔长度和每块样本点数
interval_length = 1024
samples_per_block = 1024
# 数据前处理函数
def Sampling(signal, interval_length, samples_per_block):
num_samples = len(signal)
num_blocks = num_samples // samples_per_block
samples = []
for i in range(num_blocks):
start = i * samples_per_block
end = start + interval_length
samples.append(signal[start:end])
return np.array(samples)
def DataPreparation(df, interval_length, samples_per_block):
X, LabelPositional, Label = None, None, None
for count, column in enumerate(df.columns):
SplitData = Sampling(df[column].values, interval_length, samples_per_block)
y = np.zeros([len(SplitData), 10])
y[:, count] = 1
y1 = np.zeros([len(SplitData), 1])
y1[:, 0] = count
# 堆叠并标记数据
if X is None:
X = SplitData
LabelPositional = y
Label = y1
else:
X = np.append(X, SplitData, axis=0)
LabelPositional = np.append(LabelPositional, y, axis=0)
Label = np.append(Label, y1, axis=0)
return X, LabelPositional, Label
# 数据前处理
X, Y_CNN, Y = DataPreparation(df, interval_length, samples_per_block)
print('Shape of Input Data =', X.shape)
print('Shape of Label Y_CNN =', Y_CNN.shape)
print('Shape of Label Y =', Y.shape)
# 结果如下
'''
Shape of Input Data = (1170, 1024) # 1170是样本量,即1198080/1024,样本量除以一个样本的大小等于样本个数
Shape of Label Y_CNN = (1170, 10)
Shape of Label Y = (1170, 1)
'''
# k折交叉验证
from sklearn.model_selection import train_test_split, KFold
kSplits = 5
kfold = KFold(n_splits=kSplits, random_state=32, shuffle=True)
# 大家可以分别输出查看一下 X, Y_CNN, Y 长什么样,下面我展示一下
# X太长了就不放了;
# Y_CNN = array([[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 1.],
[0., 0., 0., ..., 0., 0., 1.],
[0., 0., 0., ..., 0., 0., 1.]]) #独热编码,能看出是10分类
# Y = array([[0.],
[0.],
[0.],
...,
[9.],
[9.],
[9.]])这块数据基本转化为清晰的分类数据后,接下来导入CNN模型
2、一维卷积神经网络1D-CNN
# Reshape数据
Input_1D = X.reshape([-1,1024,1])
# 数据集划分
X_1D_train, X_1D_test, y_1D_train, y_1D_test = train_test_split(Input_1D, Y_CNN, train_size=0.75,test_size=0.25, random_state=101)
# 定义1D-CNN模型
class CNN_1D():
def __init__(self):
self.model = self.CreateModel()
def CreateModel(self):
model = models.Sequential([
layers.Conv1D(filters=16, kernel_size=3, strides=2, activation='relu'),
layers.MaxPool1D(pool_size=2),
layers.Conv1D(filters=32, kernel_size=3, strides=2, activation='relu'),
layers.MaxPool1D(pool_size=2),
layers.Conv1D(filters=64, kernel_size=3, strides=2, activation='relu'),
layers.MaxPool1D(pool_size=2),
layers.Conv1D(filters=128, kernel_size=3, strides=2, activation='relu'),
layers.MaxPool1D(pool_size=2),
layers.Flatten(),
layers.InputLayer(),
layers.Dense(100,activation='relu'),
layers.Dense(50,activation='relu'),
layers.Dense(10),
layers.Softmax()
])
model.compile(optimizer='adam',
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=['accuracy'])
return model
accuracy_1D = []
# 训练结果
for train, test in kfold.split(X_1D_train,y_1D_train):
Classification_1D = CNN_1D()
history = Classification_1D.model.fit(X_1D_train[train], y_1D_train[train], verbose=1, epochs=12)
kf_loss, kf_accuracy = Classification_1D.model.evaluate(X_1D_train[test], y_1D_train[test])
accuracy_1D.append(kf_accuracy)
CNN_1D_train_accuracy = np.average(accuracy_1D)*100
print('CNN 1D train accuracy =', CNN_1D_train_accuracy)
CNN_1D_test_loss, CNN_1D_test_accuracy = Classification_1D.model.evaluate(X_1D_test, y_1D_test)
CNN_1D_test_accuracy*=100
print('CNN 1D test accuracy =', CNN_1D_test_accuracy)3、绘制结果-可视化
# 定义混淆矩阵
from sklearn.metrics import confusion_matrix
def ConfusionMatrix(Model, X, y):
y_pred = np.argmax(Model.model.predict(X), axis=1)
ConfusionMat = confusion_matrix(np.argmax(y, axis=1), y_pred)
return ConfusionMat
# 画图
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(1)
plt.title('Confusion Matrix - CNN 1D Train')
sns.heatmap(ConfusionMatrix(Classification_1D, X_1D_train, y_1D_train) , annot=True, fmt='d',annot_kws={"fontsize":8},cmap="YlGnBu")
plt.show()
plt.figure(2)
plt.title('Confusion Matrix - CNN 1D Test')
sns.heatmap(ConfusionMatrix(Classification_1D, X_1D_test, y_1D_test) , annot=True, fmt='d',annot_kws={"fontsize":8},cmap="YlGnBu")
plt.show()
plt.figure(3)
plt.title('Train - Accuracy - CNN 1D')
plt.bar(np.arange(1,kSplits+1),[i*100 for i in accuracy_1D])
plt.ylabel('accuracy')
plt.xlabel('folds')
plt.ylim([0,100])
plt.show()
plt.figure(4)
plt.title('Train vs Test Accuracy - CNN 1D')
plt.bar([1,2],[CNN_1D_train_accuracy,CNN_1D_test_accuracy])
plt.ylabel('accuracy')
plt.xlabel('folds')
plt.xticks([1,2],['Train', 'Test'])
plt.ylim([0,100])
# plt.show()可视化结果如下:
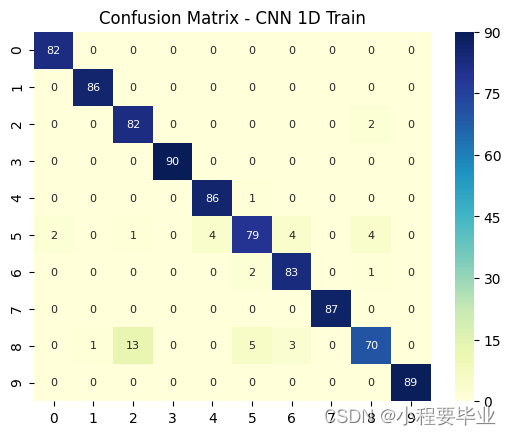

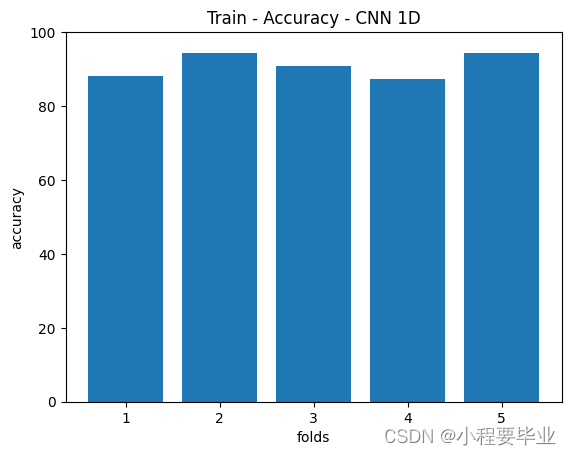
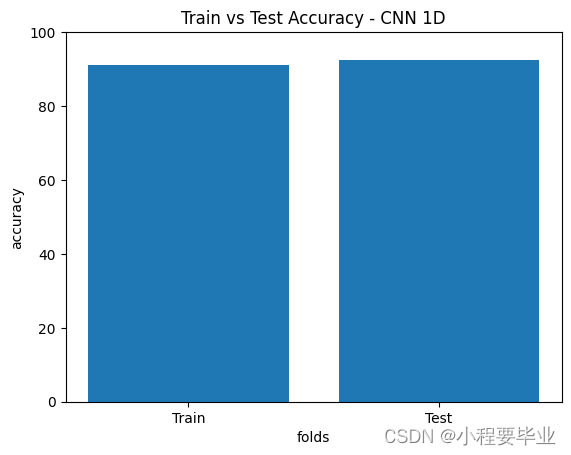
好,补充完毕,我继续打羽毛球去啦!
四、数据路径修改
大家如果不明白如何修改路径,可以参考一下操作,理解过程后就可以重新把数据放在需要的位置了!
1、在你的电脑某盘里放一个名为10calss的文件夹,当然名字可以随意改

2、双击进入文件夹,鼠标单击蓝色箭头所指位置
 3、复制数据所在路径,蓝色部分就要所要的路径啦!
3、复制数据所在路径,蓝色部分就要所要的路径啦!
 希望能对大家有所帮助 慢慢来就好啦 ^_^
希望能对大家有所帮助 慢慢来就好啦 ^_^















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









