







【题目7-动态链表体验】
下面是一个建立动态链表的程序。阅读程序,在草稿纸上画出链表建立的过程,借此学会如何建立链表。然后改造程序,完成题目7的要求
<span style="font-size:14px;">#include <iostream>
using namespace std;
struct Node
{
int data; //结点的数据
struct Node *next; //指向下一结点
};
Node *head=NULL; //将链表头定义为全局变量,以便于后面操作
void make_list(); //建立链表
void out_list(); //输出链表
int main( )
{
make_list();
out_list();
return 0;
}
void make_list()
{
int n;
Node *p;
cout<<"输入若干正数(以0或一个负数结束)建立链表:"
cin>>n;
while(n>0) //输入若干正数建立链表,输入非正数时,建立过程结束
{
p=new Node; //新建结点
p->data=n;
p->next=head; //新建的结点指向原先的链表头
head=p; //链表头赋值为新建的节点,这样,新结点总是链表头
cin>>n; //输入下一个数,准备建立下一个结点
}
return;
}
void out_list()
{
Node *p=head;
cout<<"链表中的数据为:"<<endl;
while(p!=NULL)
{
cout<<p->data<<" ";
p=p->next;
}
cout<<endl;
return;
}</span>
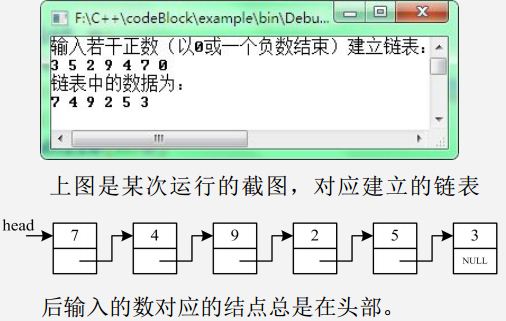
在上面的程序基础上定义下面的函数,实现相应的功能。为简便起见,每编写一个函数,立刻在main函数中调用进行测试。
(1)编写make_list2()函数建立链表,使建立链表时,后输入的数据,将新输入的数字对应的结点放在链表末尾。若输入为3 5 2 9 4 7 0,建立的链表为:

(2)编写函数void search(int x),输出链表中是否有值为x的结点。
(3)编写函数delete_first_node(),删除链表中的第一个结点。
(4)编写函数delete_node(int x),删除结点值为x的结点。
(5)编写make_list3()函数建立有序链表,使建立链表时,结点中的数据呈现升序。若输入为3 5 2 9 4 7 0,建立的链表为:
(6)编写函数void insert(int x),将值为x的结点插入到由make_list3建立起来的有序链表中。

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









