







一、数据库概述。
1,什么是数据库?
数据库:DataBase。它是按照数据结构来组织、存储、和管理数据的仓库。
诞生于六十年前。
2,数据库按结构分类:
a. 层次结构型数据库:
层次结构模型实质上是一种有根结点的定向有序树(在数学中"树"被定义为一个无回的连通图)。下图是一个高等学校的组织结构图。
这个组织结构图像一棵树,校部就是树根(称为根结点),各系、专业、教师、学生等为枝点(称为结点),树根与枝点之间的联系称为边,
树根与边之比为1:N,即树根只有一个,树枝有N个。
按照层次模型建立的数据库系统称为层次模型数据库系统。IMS(Information Management System)是其典型代表。
b. 网状结构型数据库:
按照网状数据结构建立的数据库系统称为网状数据库系统,其典型代表是DBTG(Database Task Group)。
用数学方法可将网状数据结构转化为层次数据结构。
c.关系结构型数据库:(本篇主要介绍的是它)
关系式数据结构把一些复杂的数据结构归结为简单的二元关系(即二维表格形式)。例如某单位的职工关系就是一个二元关系。
由关系数据结构组成的数据库系统被称为关系数据库系统。
在关系数据库中,对数据的操作几乎全部建立在一个或多个关系表格上,通过对这些关系表格的分类、合并、连接或选取等运算来实现数据的管理。
dBASEⅡ就是这类数据库管理系统的典型代表。对于一个实际的应用问题(如人事管理问题),有时需要多个关系才能实现。
用dBASEⅡ建立起来的一个关系称为一个数据库(或称数据库文件),而把对应多个关系建立起来的多个数据库称为数据库系统。
dBASEⅡ的另一个重要功能是通过建立命令文件来实现对数据库的使用和管理,对于一个数据库系统相应的命令序列文件,称为该数据库的应用系统。
因此,可以概括地说,一个关系称为一个数据库,若干个数据库可以构成一个数据库系统。
数据库系统可以派生出各种不同类型的辅助文件和建立它的应用系统。
3,常用关系型数据库:
Oracle(在企业中用的较多)
DB2
Informix
Sybase
SQL Server
ProstgreSQL面向对象数据库
MySQL(在企业中用的较多)
Access
SQLite等
二、SQL简介。
1,SQL是什么?
结构化查询语言 Structured Query Language。
它是一种定义和操作关系型数据库的语法,绝大多数数据库都支持。
2,SQL的作用:
跟数据库建立联系,进行沟通。
3,SQL的标准:
它是由ANSI管理和维护的。(ANSI:美国国家标准学会,是ISO成员之一)
工业标准:目前最新的是SQL-2003(之前有1992年的SQL92和1999年的SQL99)
方言:各个数据库厂商在工业标准上进行的扩展
4,SQL的组成:
DDL:数据定义语言 Data Define language (创建/删除/修改数据库、数据表结构)
DML:数据操作语言。Data Manipulation Language (数据表中数据的添加,修改,删除)
DQL:数据查询语言。Data Query Language (查询数据表中的数据)
DCL:数据控制语言。Data Control Language (权限控制相关)
TPL:事务处理语言。Transaction Processing Language (事务处理相关)
CCL:指针控制语言。 Cursor Control Language (游标,多用于存储过程)
三、MySQL入门。
1,安装和配置。
详见,可以下载文档查看:
链接: http://pan.baidu.com/s/1o6oYW6A 密码: gdhm
2,数据库服务器,数据库和表的关系:
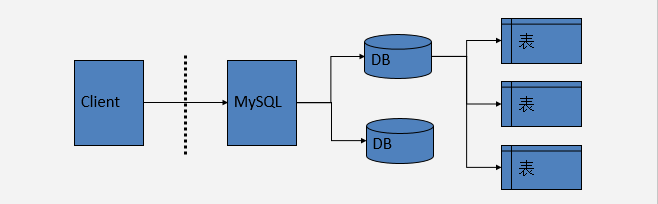
明确:
1、mysql是一个关系型数据库的厂商。当我们安装并且配置完成后,mysql就可以为我们提供服务了。我们可以通过客户端来连接mysql,从而进行操作。
2、先有MySQL——>再在MySQL下创建数据库——>再在数据库中创建表。
3、每一张表都属于一个数据库(DB),每一个DB都是在Mysql下创建的。3,数据和数据库中表的关系:
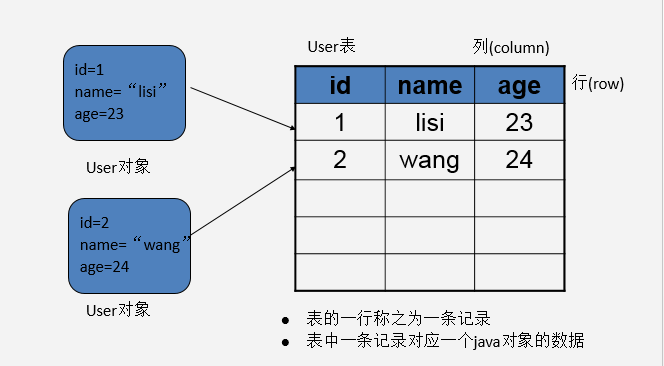
明确:
java中的每一个对象反映到数据库中就是一条记录。
四、DDL数据定义语言。
DDL的作用:用于描述数据库中要存储现实世界实体的语言。简单说就是创建数据库和表。
明确:DDL是针对谁的定义。是针对数据库和数据库中表的结构的定义。
DDL中常用的关键字:
Create:创建
Alter: 改变
Drop: 删除
Truncate:截断/摧毁1、库操作:
创建数据库语法:详见mysql-5.1参考手册第13.1.3节
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification [, create_specification] ...] //创建细节规范
create_specification:
[DEFAULT] CHARACTER SET charset_name //细节规范之一:指定数据库所使用的字符集,如果不指定,使用的就是安装时的字符集。
| [DEFAULT] COLLATE collation_name】 //细节规范之二:指定数据库的校对规则(可以理解字符的排序规则)
数据库删除语法:
DROP DATABASE [IF EXISTS] db_name
数据库修改语法:
ALTER DATABASE [IF NOT EXISTS] db_name
[alter_specification [, alter_specification] ...]
alter_specification:
[DEFAULT] CHARACTER SET charset_name
| [DEFAULT] COLLATE collation_name
语法说明:
默认情况下,语句以分号为分界符。
在windows系统下,不区分大小写。其他系统严格区分大小写。
关于规范:(建议使用,但是不是强制规定)
•关键字小写
•用户自定义的东西全部大写
•多个单词组成的,用下划线分隔练习:
创建一个名称为mydb1的数据库。
create databse MYDB1;/create database if not exists MYDB1;
查看有多少数据库:
show databases;
查看数据库创建细节:
show create database MYDB1;
创建一个使用gbk字符集的mydb2数据库。
create database MYDB2 character set gbk;
创建一个使用gbk字符集,并带校对规则的mydb3数据库
show collation like 'gbk%';
create database MYDB3 character set gbk collate gbk_chinese_ci;
删除前面创建的mydb3数据库
drop database MYDB3;
查看服务器中的数据库,并把mydb2的字符集修改为utf8;
alter database MYDB2 character set utf8;
2、表结构操作
前期准备:
查看当前数据库:select database();----------//该函数是mysql独有的
使用指定数据库:use database_name;----------//database_name指的是数据库的名字。例如MYDB1,MYDB2等等。
创建表语法:
CREATE TABLE table_name
(
field1 datatype,
field2 datatype,
field3 datatype
);character set 字符集 collate 校对规则
field:指定列名 datatype:指定列类型
修改表语法:
ALTER [IGNORE] TABLE tbl_name
alter_specification [, alter_specification] ...
alter_specification:
ADD [COLUMN] column_definition [FIRST | AFTER col_name ] //添加一列
| ADD [COLUMN] (column_definition,...)
| CHANGE [COLUMN] old_col_name column_definition [FIRST|AFTER col_name] //修改列名
| MODIFY [COLUMN] column_definition [FIRST | AFTER col_name] //修改列规则(通常修改列的数据类型)
| DROP [COLUMN] col_name //删除一列
修改表名语法:rename table old_name to new_name;
上面创建表是最基本的,细节部分请参考mysql-5.1参考手册13.1.2节,13.1.5节,13.1.8节。
数据库中的列类型和所需存储空间:(重点)
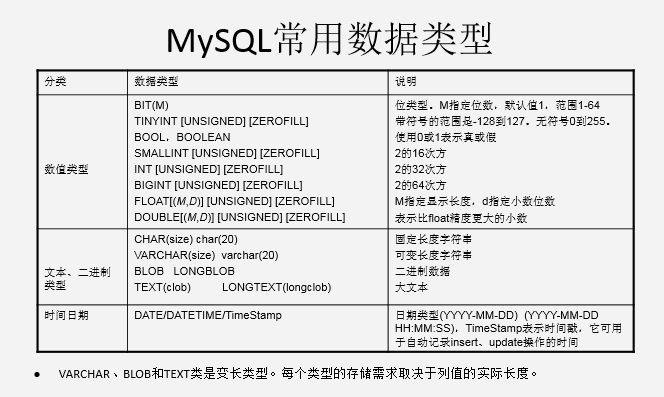
练习:
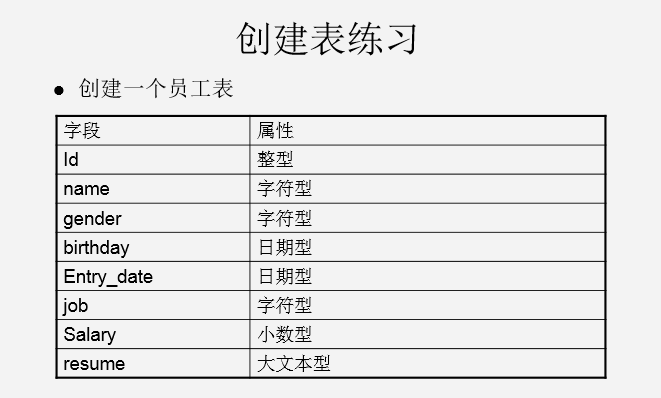
代码体现:
create table EMPLOYEE(
ID int,
NAME varchar(100),
GENDER varchar(10),
BIRTHDAY date,
ENTRY_DATE date,
JOB varchar(100),
SALARY float(8,2),
RESUME LONGTEXT
);查看表详情:desc table_name;-----//table_name指的是表的名称。
desc EMPLOYEE;
在上面员工表的基本上增加一个image列。
alter table EMPLOYEE add(IMAGE longblob);
修改job列,使其长度为60。
alter table EMPLOYEE modify JOB varchar(60);
删除image列。
alter table EMPLOYEE drop IMAGE;
表名改为user。
rename table EMPLOYEE to USER;
查看库中所有表。
show tables;
修改表的字符集为utf8。
alter table USER character set utf8;
列名name修改为username。
alter table USER change NAME USERNAME varchar(100);
删除表:
drop table USER;
五、DML数据操作语言(重要)。
DML作用:用于向数据库表中插入、删除、修改数据。
明确:DML是对谁的操作。是针对数据库中表的数据的操作。
DML常用关键字:INSERT(添加) UPDATE(修改) DELETE(删除) 。
1、INSERT:
插入数据语法:
INSERT INTO table_name[(column [, column...])] VALUES value [, value...]);说明:
插入的数据应与字段的数据类型相同。
数据的大小应在列的规定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中。
在values中列出的数据位置必须与被加入的列的排列位置相对应。
字符或字符串数据用单引号引起了。例如:'test','abc'等等。
日期或时间,用单引号引起来。日期的格式用yyyy-MM-dd。'2015-08-25'
插入空值用:null。分清null和''的区别。null表示空值,''表示空字符或空字符串。
练习:
使用insert语句向表中插入三个员工的信息。
insert into USER values(1,'zs','nan','1999-10-01','2011-10-10','ceo',10000,'hello');//这个不能选择性插入,必须所有字段都有值
insert into USER(ID,USERNAME,GENDER,BIRTHDAY,ENTRY_DATE,JOB,SALARY,RESUME)
values(1,'aaa','nan','1999-10-01','2011-10-10','ceo',10000,'hello');//可以选择性插入,不想插入就不在前面写列名。(建议)
insert into USER(ID,USERNAME,GENDER,BIRTHDAY,ENTRY_DATE,JOB,SALARY,RESUME)
values(1,'张三','nan','1999-10-01','2011-10-10','ceo',10000,'你好');//直接执行会有问题。

分析原因:字符集问题。
我们使用的cmd命令行是gbk的字符集(而且修改不了),而数据库中表的字符集是utf8,所以存储失败。
在MySQL中一共有6个地方使用了字符集。可以通过命令查看:show variables like 'character%';
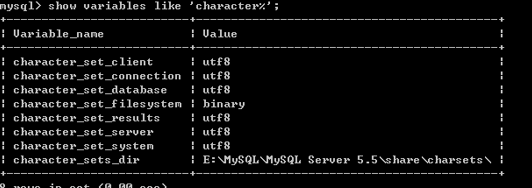
client:是客户端使用的字符集。
connection:是连接数据库的字符集设置类型,如果程序没有指明连接数据库使用的字符集类型就按照服务器端默认的字符集设置。
database:是数据库服务器中某个库使用的字符集设定,如果建库时没有指明,将使用服务器安装时指定的字符集设置。
results:是数据库给客户端返回时使用的字符集设定,如果没有指明,使用服务器默认的字符集。
server:是服务器安装时指定的默认字符集设定。
system:是数据库系统使用的字符集设定。
解决问题:
针对上述情况,我们需要修改客户端的字符集,告诉mysql,我们插入的中文是用gbk编码的。由mysql为我们转成utf8。
set character_set_client=gbk;
当我们查询数据时,发现还是乱码:
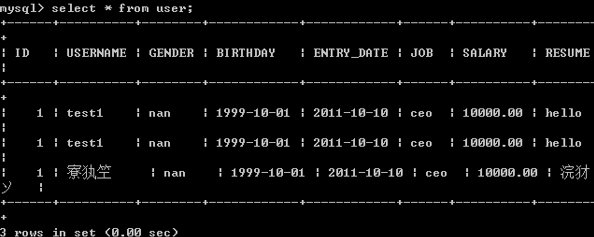
根据上面的经验:我们需要设置结果集用gbk编码。
set character_set_results=gbk;
2、UPDATE:
更新数据语法:
UPDATE tbl_name SET col_name1=expr1 [, col_name2=expr2 ...] [WHERE where_definition]
说明:
UPDATE语法可以用新值更新原有表行中的各列。
SET子句指示要修改哪些列和要给予哪些值。
WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行。
练习:
将所有员工薪水修改为5000元。
update user set salary = 5000;
将姓名为’zs’的员工薪水修改为3000元。
update user set salary = 3000 where username = 'zs';
将姓名为’aaa’的员工薪水修改为4000元,job改为ccc。
update user set salary=4000,job='ccc' where username = 'aaa';
将wu的薪水在原有基础上增加1000元。
update user set salary = salary+1000 where username = 'wu';
3、DELETE:
删除数据语法:
delete from table_name [WHERE where_definition]
摧毁表格语法:
truncate table table_name;
说明:
如果不使用where子句,将删除表中所有数据。
Delete语句不能删除某一列的值(可使用update),每次都是删除一行记录。
使用delete语句仅删除记录,不删除表本身。如要删除表,使用drop table语句。
同insert和update一样,从一个表中删除记录将引起其它表的参照完整性问题,在修改数据库数据时,头脑中应该始终不要忘记这个潜在的问题。
删除表中数据也可使用TRUNCATE TABLE 语句,它和delete不同,delete是逐条删除,Truncate是整个摧毁表格,然后再重建表结构,参看mysql文档。
练习:
删除表中名称为’zs’的记录。
delete from USER where username = 'zs';
删除表中所有记录。
delete form USER;
使用truncate删除表中记录。
truncate table USER;
六、DQL数据查询语言(重要)
作用:查询数据,返回结果集。
常用关键字:select(看似简单,其实最难。组织条件和执行效率)
**1、SELECT**
基本查询语法:SELECT [DISTINCT] *|{column1, column2, column3..} FROM table_name;
说明:
Select 指定查询哪些列的数据。
column指定列名。
*号代表查询所有列。
From指定查询哪张表。
DISTINCT可选,指显示结果时,是否剔除重复数据
练习:
查询表中所有学生的信息。
select * from STUDENT;
查询表中所有学生的姓名和对应的英语成绩。
select NAME,ENGLISH from STUDENT;
过滤表中重复数据。
select distinct* from STUDENT;
使用表达式和列(表)别名的语法:
在select语句中可使用表达式对查询的列进行运算:
SELECT *|{column1|expression, column2|expression,..} FROM table_name;
在select语句中可使用as语句指定别名:
SELECT column_name as 列的别名from table_name as 表的别名;
练习:
在所有学生数学分数上加10分特长分。
select NAME,MATH+10 from STUDENT;
统计每个学生的总分。
select NAME,CHINESE+ENGLISH+MATH from STUDENT;
使用别名表示学生分数。
select NAME as 姓名, CHINESE+ENGLISH+MATH '总分' from STUDENT as s;
注意:在使用别名时,as关键字可以省略。列别名可以用单引号引起来,也可以不引。表名的别名,不能用单引号引起来。
使用条件进行过滤查询:
where子句:
SELECT [DISTINCT] *|{column1, column2, column3..} FROM table_name WHERE condition;
在where子句中常使用的运算符:
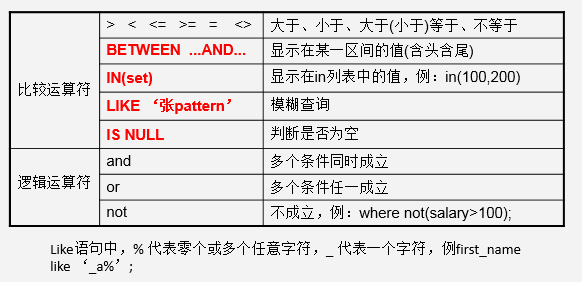
注意:not and or优先级依次降低,一元运算符比二元运算符优先级要高。
练习:
查询姓名为王五的学生成绩
select MATH,ENGLISH,CHINESE from STUDENT where username='王五';
查询英语成绩大于90分的同学
select NAME,ENGLISH form STUDENT where english>90;
查询总分大于200分的所有同学
select NAME, ENGLISH,MATH,CHINESE, ENGLISH+MATH+CHINESE from STUDENT where ENGLISH+MATH+CHINESE>200;
查询英语分数在 80-90之间的同学。
select NAME,ENGLISH from STUDENT where ENGLISH between 80 and 90;
查询数学分数为89,90,91的同学。
select NAME,MATH from STUDENT where MATH in(89,90,91);
查询所有姓李的学生成绩。
select NAME,ENGLISH,MATH,CHINESE from STUDENT where NAME like '李%';
查询数学分>80,语文分>80的同学。
select NAME,MATH,CHINESE from STUDENT where MATH>80 and CHINESE > 80;
将查询结果排序:
使用order by子句:
SELECT column1, column2. column3.. FROM table_name order by column asc|desc
说明:
Order by 指定排序的列,排序的列即可是表中的列名,也可以是select 语句后指定的列名。
asc 升序——默认的(ascending)、desc 降序(Descending)
ORDER BY 子句应位于SELECT语句的结尾。
练习:
对数学成绩排序后输出。
select NAME,MATH from STUDENT order by MATH;
对总分排序后输出,然后再按从高到低的顺序输出。
select NAME,MATH+ENGLISH+CHINESE as TOTAL from STUDENT order by MATH+ENGLISH+CHINESE desc;
对姓李的学生成绩排序输出。
select NAME, MATH+ENGLISH+CHINESE as TOTAL from STUDENT where name like '李%' order by MATH+ENGLISH+CHINESE ;
注意:
尽量避免使用关键字命名表名或列名。例如:password,order等。
解决办法:
1.使用反引号将表名或字段名引起来。`(英文状态下,ESC下面的那个键)
2.使用良好的命名规范:例如 ORDER——>ORDERS PASSWORD——>PASSWD等等。
七、数据完整性和多表设计。(重要)
1、数据完整性概述:
数据完整性是为了保证插入到数据中的数据是正确的,它防止了用户可能的输入错误。
2、数据完整性主要分类:
a.实体完整性(记录):
规定表的一行(即每一条记录)在表中是唯一的实体(Entity)。实体完整性通过表的主键来实现。
主键:
唯一确定一条记录(一个实体)的字段。主键都有以下特点:
不能为null,必须唯一。
声明一个主键的语法:
第一种:(只能指定一个字段作为主键)
create table T1(
ID int primary key,
NAME varchar(100)
);
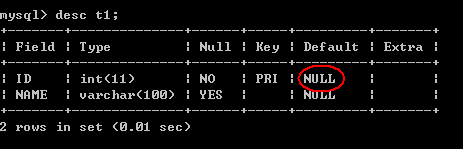
第二种:(可以使用联合主键)
create table T2(
ID int,
NAME varchar(100),
primary key(ID)
);
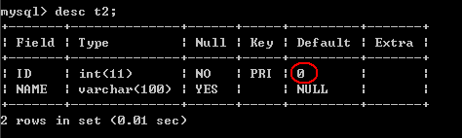
第三种:(创建没有任何约束的表格,使用alter添加/修改约束)建议使用。
create table T3(
ID int,
NAME varchar(100)
);
alter table T3 add primary key(ID);
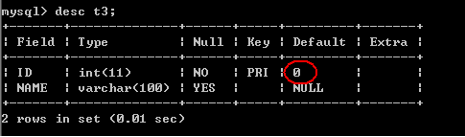
问题:当使用第二种和第三种创建的方式,最后执行的结果是更新还是保存?
注意:
逻辑主键:除了唯一标识一条记录外,没有别的意义。一般取名表明加ID或_ID。例如:studentid或student_id(建议)
业务主键:除了具备逻辑主键的特性,还具有一定的业务意义。
MYSQL独有的自增长主键:
create table t4(
ID int primary key auto_increment, ---------------------//不建议使用,不是所有数据库中都支持自增长,例如oracle。在数据库迁移时,容易出问题。
NAME varchar(100)
);
b.域完整性(字段):
指数据库表的列(即字段)必须符合某种特定的数据类型或约束。比如NOT NULL。
常用字段约束:
a. 数据类型约束:强类型
b. 非空约束: NOT NULL
c. 唯一约束: unique
create table T5(
ID int primary key auto_increment,
USERNAME varchar(100) not null unique,
GENDER char(1) not null,
PHONE varchar(11) unique
);
c.参照完整性(多表):
保证一个表的外键和另一个表的主键对应。
注意:类和表结构的关系;对象和记录的关系(学习ORM有帮助。例如:hibernate,MyBatis)。
第一:一对多(非常多,非常常用)
create table CUSTOMERS(
C_ID int primary key,
C_NAME varchar(100),
C_ADDRESS varchar(200)
);
create table ORDERS(
O_ID int primary key,
O_NUM varchar(100),
O_AMOUNT varchar(100),
O_CUSTOMERID int,
constraint FK_CUSTOMER_ID foreign key (O_CUSTOMERID) references CUSTOMERS(c_id)
);
对应的java类设计:
注意区分:
表结构:对应java类的定义
表中的记录:对应java对象
表间的关系:对应java对象间的关系
第二:多对多(比较常见)
create table TEACHERS(
T_ID int primary key,
T_NAME varchar(100),
T_SALARY float(8,2)
);
create table STUDENTS(
S_ID int primary key,
S_NAME varchar(100),
S_GRADE varchar(10)
);
create table TEACHER_STUDENT_REF(
TEACHER_ID int,
STUDENT_ID int,
primary key(TEACHER_ID,STUDENT_ID),
constraint T_ID_FK foreign key (TEACHER_ID) references TEACHERS(T_ID),
constraint S_ID_FK foreign key (STUDENT_ID) references STUDENTS(S_ID)
);
java类设计:
第三种:一对一(比较少见,实际开发根本不用)
java类设计:
数据建模:PowerDesigner
八、DQL的复杂查询
1、连接查询
a、交叉连接:cross join
返回多表记录的笛卡尔积。简单说就是返回每张表记录数相乘的积。
select * from CUSTOMER c,ORDERS o;
select c.ID,c.NAME,o.ORDER_NUMBER,o.PRICE from CUSTOMER c cross join ORDERS o;
一般情况下我们就不写关键字,直接用,分隔。
b、内连接:inner join
返回连接表中符合连接条件及查询条件的数据行。
隐式内连接:select * from CUSTOMER c,ORDERS o where c.id = o.customer_id;
显式内连接:select * from CUSTOMER c inner join ORDERS o on c.id = o.customer_id;
c、外连接:
分为左外连接(left outer join)、右外连接(right outer join)。
与内连接不同的是,外连接不仅返回连接表中符合连接条件及查询条件的数据行,
也返回左表(左外连接时)或右表(右外连接时)中仅符合查询条件但不符合连接条件的数据行。
左外连接:除了返回符合条件的记录外,还返回左表其他记录。
select * from CUSTOMER c left outer join ORDERS o on c.ID=o.CUSTOMER_ID;
右外连接:除了返回符合条件的记录外,还返回右表其他记录。
select * from CUSTOMER c right outer join ORDERS o on c.ID=o.CUSTOMER_ID;
2、子查询
子查询也叫嵌套查询,是指在select子句或者where子句中又嵌入select查询语句,子查询的语句放在小括号之内。
执行顺序:先执行子查询(内查询),再执行外查询。
子查询:必须放在小括号之内。
练习:
查询“陈冠希”的所有订单信息
形式一:多条查询语句
select ID from CUSTOMER where NAME=’陈冠希’;
select * from ORDERS where CUSTOMER_ID=1;
形式二:subselect(子查询)
select * from ORDERS where CUSTOMER_ID=(select ID from CUSTOMER where NAME=’陈冠希’);
查询订单价格大于100的有哪些客户
select * from CUSTOMER where ID in (select CUSTOMER_ID from ORDERS where PRICE>100);
3、MySQL常用函数(聚合函数)
SUM():求和
select sum(列名){,sum(列名)…} from tablename [WHERE where_definition]
COUNT():计数
select count(*)|count(列名) from tablename [WHERE where_definition]
AVG():求平均
select avg(列名){,avg (列名)…} from tablename [WHERE where_definition]
MAX():求最大
MIN():求最小
select max/min(列名) from tablename [WHERE where_definition]
练习:
统计一个班级共有多少学生?
select count(*) from STUDENT;
统计数学成绩大于90的学生有多少个?
select count(*) from STUDENT where MATH>=90;
统计总分大于250的人数有多少?where可以使用表达式
select count(*) from STUDENT where (ENGLISH+CHINESE+MATH)>250;
统计一个班级数学总成绩?
select sum(MATH) from STUDENT;
统计一个班级语文、英语、数学各科的总成绩
select sum(CHINESE),sum(ENGLISH),sum(MATH) from STUDENT;
统计一个班级语文、英语、数学的成绩总和
select sum(ENGLISH+CHINESE+MATH) from STUDENT;
统计一个班级语文成绩平均分
select sum(CHINESE)/count(*) from STUDENT;
select avg(CHINESE) from STUDENT; #如果字段为null,不参与平均的计算。
4、分组(报表)查询:group by
使用group by分组查询:
SELECT column1, column2. column3.. FROM table_name group by column_name;
使用group by 和 having子句分组查询:
SELECT column1, column2. column3.. FROM table_name group by column having ...
注意:
Having和where均可实现过滤,但在having可以使用聚合函数,having通常跟在group by后,它作用于组。
练习:
对订单表中商品归类后,显示每一类商品的总价
select PRODUCT,sum(PRICE) from PRODUCTS group by PRODUCT;
查询购买了几类商品,并且每类总价大于100的商品
select PRODUCT,sum(PRICE) from PRODUCTS group by PRODUCT having sum(PRICE)>100;
5、其他函数简介
时间日期相关:
ADDTIME (date2 ,time_interval ) 将time_interval加到date2
CURRENT_DATE ( ) 当前日期
CURRENT_TIME ( ) 当前时间
CURRENT_TIMESTAMP ( ) 当前时间戳
DATE (datetime ) 返回datetime的日期部分
DATE_ADD (date2 , INTERVAL d_value d_type ) 在date2中加上日期或时间
DATE_SUB (date2 , INTERVAL d_value d_type ) 在date2上减去一个时间
DATEDIFF (date1 ,date2 ) 两个日期差
NOW ( ) 当前时间
YEAR|Month|DATE (datetime ) 年月日
字符串相关:
CHARSET(str) 返回字串字符集
CONCAT (string2 [,… ]) 连接字串
INSTR (string ,substring ) 返回substring在string中出现的位置,没有返回0
UCASE (string2 ) 转换成大写
LCASE (string2 ) 转换成小写
LEFT (string2 ,length ) 从string2中的左边起取length个字符
LENGTH (string ) string长度
REPLACE (str ,search_str ,replace_str ) 在str中用replace_str替换search_str
STRCMP (string1 ,string2 ) 逐字符比较两字串大小,
SUBSTRING (str , position [,length ]) 从str的position开始,取length个字符
LTRIM (string2 ) RTRIM (string2 ) trim 去除前端空格或后端空格
数学相关:
ABS (number2 ) 绝对值
BIN (decimal_number ) 十进制转二进制
CEILING (number2 ) 向上取整
CONV(number2,from_base,to_base) 进制转换
FLOOR (number2 ) 向下取整
FORMAT (number,decimal_places ) 保留小数位数
HEX (DecimalNumber ) 转十六进制
LEAST (number , number2 [,..]) 求最小值
MOD (numerator ,denominator ) 求余
RAND([seed]) RAND([seed])
九、数据库的备份与恢复
1、备份数据(表结构和数据)
c:\MySQL\bin\mysqldump -h localhost -p3306 -u root -p day14>d:/day14.sql
mysqldump是备份的命令
-h 是连接的主机
-p 端口号
-u 用户名
-p 密码
day14:指定是备份哪个数据库 mydb1
备份用>备份的地址
2、恢复数据库中的数据
前提:必须先创建数据库名
方式一:
mysql>user day14;
mysql>source d:/day14.sql;
方式二:
c:\MySQL\bin\mysql -u root -p day14

















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









