







 本文详细介绍了如何使用SQLAlchemy在Python中实现关系型数据库的模型映射,包括一对多、多对一、一对一及多对多关系的定义与操作,通过具体示例讲解了外键创建、关系属性定义及双向关系建立的方法。
本文详细介绍了如何使用SQLAlchemy在Python中实现关系型数据库的模型映射,包括一对多、多对一、一对一及多对多关系的定义与操作,通过具体示例讲解了外键创建、关系属性定义及双向关系建立的方法。
定义关系
在关系型数据库中,我们可以通过关系让不同表之间的字段建立联系。一般来说,
定义关系需要两步,分别是创建外键和定义关系属性。在更复杂的多对多关系中,我们还需要定义关联表来管理关系。下面我们学习用SQLAlchemy在模型之间建立各种基础的关系模式。
配置python shell上下文
在之前的操作中,每次使用flask shell命令启动python shell后都要从app模块导入db对象和相应的模型类,为什么不能把他们字自动集成到python shell的上下文里呢?就像flask内置的app对象一样。这样当然可以实现,我们可以使用app.shell_context_processor装饰器注册一个shell上下文处理函数。它和模板上下文处理函数一样,也需要返回包含变量和变量值的字典。
app.py:注册shell上下文处理函数
@app.shell_context_processor
def make_shell_context():
return dict(db=db, Note=Note)当使用flask shell命令启动python shell时,所有使用app.shell_context_processor装饰器注册的shell上下文处理函数都会被自动执行,这会将db和Note对象推送到python shell上下文中:
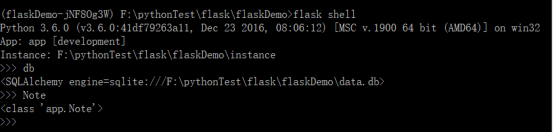
在下面演示各种数据库关系时,将编写更多的模型类,在示例程序中,都使用shell上下文处理函数添加到shell上下文中,因此可以直接在python shell中使用,不用手动导入。
一对多
我们将以作者和文章为例来演示一对多关系:一个作者可以写多篇文章,一对多关系如下:
在示例程序中,Author类用来表示作者,Article类用来表示文章。
app.py:一对多关系示例
# -*- coding: utf-8 -*-#
import os
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.secret_key = os.getenv('SECRET_KEY', 'secret string')
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
app.config["SQLALCHEMY_DATABASE_URI"] = os.getenv("DATABASE_URL",
'sqlite:///'+os.path.join(app.root_path, "data.db"))
db = SQLAlchemy(app)
class Author(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
articles = db.relationship('Article')
def __repr__(self):
return '<Author id:%r, name:%r>' % (self.id, self.name)
class Article(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(50), index=True)
body = db.Column(db.Text)
author_id = db.Column(db.Integer, db.ForeignKey('author.id'))
def __repr__(self):
return "<Article id:%r, title:%r, body:%r, author_id:%r>" % \
(self.id, self.title, self.body, self.author_id)
if __name__ == "__main__":
app.run(debug=True)我们将在这两个模型之间建立一个一对多关系,建立这个一对多关系的目的是在表示作者的Author类中添加一个关系属性articles,作为集合(collection)属性,当我们对特定的Author对象调用articles属性会返回所有的Article对象。下面来介绍如何一步步定义这个一对多关系。
定义外键
定义关系的第一步是创建外键。外键(foreign key)用来在A表存储B表的主键值,以便和B表建立联系的关联字段。因为外键只能存储单一数据(标量),所以外键总是在“多”这一侧定义,多篇文章属于同一个作者,所以我们需要为每篇文章添加外键存储作者的主键值以指向对应的作者。在Article模型中,我们定义一个author_id字段作为外键:
author_id = db.Column(db.Integer, db.ForeignKey('author.id'))这个字段使用db.ForeignKey类定义外键,传入关系另一侧的表和主键字段名,即author.id。实际的效果是将article表的author_id的值限制为author表的id列的值。它将用来存储author表中记录的主键值,如下图:
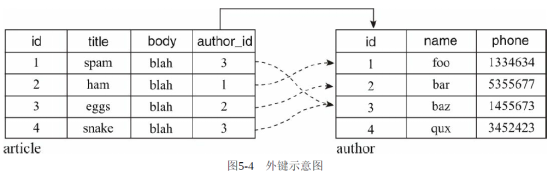
外键字段的命名没有限制,因为要连接的目标字段是author表的id列,所以为了便于区别而将这个外键字段的名称命名为author_id。
模型类中的表名是默认为类名称的小写形式
传入ForeignKey类的参数author.id,其中author指的是Author模型对应的表名称,而id指的是字段名,即“表名.字段名”。模型类对应的表名由flask-sqlalchemy生成,默认为类名称的小写形式,多个单词通过下划线分割,也可以显示地通过__tablename__属性自己指定。
定义关系属性
定义关系的第二步是使用关系函数定义关系属性。关系属性在关系的出发侧定义,即一对多关系的“一”这一侧。一个作者拥有多篇文章,在Author模型中,定义一个articles属性来表示对应的多篇文章:
class Author(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
articles = db.relationship('Article')
def __repr__(self):
return '<Author id:%r, name:%r>' % (self.id, self.name)关系属性的名称没有限制,可以自由修改。它相当于一个快捷查询,不会作为字段写入数据库中。这个属性并没有使用column类声明为列,而是使用了db.relationship()关系函数定义为关系属性,因为这个关系属性返回多个记录,我们称之为集合关系属性。relationship()函数的第一个参数为关系另一侧的模型名称,它会告诉SQLAlchemy将Author类和Article类建立关系。当这个关系属性被调用时,SQLAlchemy会找到关系的另一侧(即article表)的外键字段(author_id),然后反向查询article表中所有author_id值为当前表主键值(即author.id)的记录,返回包含这些记录的列表,也就是返回某个作者对应的多篇文章记录。
>>> from app import Author, Article
>>> from app import db
>>> foo = Author(name='Foo')
>>> spam = Article(title='Spam')
>>> ham = Article(title='Ham')
>>> db.session.add(foo)
>>> db.session.add(spam)
>>> db.session.add(ham)
>>> db.session.add_all([foo,spam,ham])除了依次调用add()方法添加多个记录,也可以使用add_all()一次添加包含所有记录对象的列表
如果没有创建表时,做了db.session.add()这样的操作,在查询的时候会提示找不到表,同时db.session会回滚,这个时候重新操作db.create_all()创建表后,提交会话时会提示db.session已经回滚,需要把db.session remove掉,重新建立session,即db.session.remove()后,再db.session.add()
建立关系
有两种方式建立关系
方式一:为外键字段赋值
>>> from app import Author, Article
>>> from app import db
>>> db.create_all()
>>> foo = Author(name='Foo')
>>> spam = Article(title='Spam')
>>> ham = Article(title='Ham')
>>> db.session.remove()
>>> db.session.add_all([foo,spam,ham])
>>> spam.author_id=1
>>> db.session.commit()将spam对象的author_id字段的值设为1,这会和id值为1的Author对象建立关系。提交数据库改动后,如果我们对id为1的foo对象调用articles关系属性性,会看到spam对象包含在返回的Article对象列表中:
>>> foo = Author.query.first()
>>> foo
<Author id:1, name:'Foo'>
>>> foo.articles
[<Article id:1, title:'Spam', body:None, author_id:1>]方式二:通过操作关系属性
将关系属性赋给数据的对象即可建立关系。集合关系属性可以像列表一样操作,调用append()方法来与一个Article对象建立关系:
>>> ham.author_id=1
>>> db.session.commit()
>>> h = Article.query.get(1)
>>> h
<Article id:1, title:'Spam', body:None, author_id:1>
>>> foo.articles
[<Article id:1, title:'Spam', body:None, author_id:1>, <Article id:2, title:'Ham', body:None, author_id:1>]
>>> A1 = Article(title='A1')
>>> foo.articles.append(A1)
>>> db.session.commit()
>>> foo.articles
[<Article id:1, title:'Spam', body:None, author_id:1>, <Article id:2, title:'Ham', body:None, author_id:1>, <Artic
A1', body:None, author_id:1>]
我们也可以直接将关系属性赋值为一个包含Article对象的列表。
>>> foo.articles
[<Article id:1, title:'Spam', body:None, author_id:1>, <Article id:2, title:'Ham', body:None, author_id:1>, <A
A1', body:None, author_id:1>]
>>> foo.articles = foo.articles[1:2]
>>> foo.articles
[<Article id:2, title:'Ham', body:None, author_id:1>]和前面的第一种方式类似,为了让改动生效,我们需要调用db.session.commit()方法提交数据库会话。
建立关系后,存储外键的author_id字段会自动获取正确的值,而调用Author实例的关系属性articles时,会获得所有建立关系的Article对象:
>>> foo.id
1
>>> A1.author_id
1和主键类似,外键字段由SQLAlchemy管理,我们不需要手动设置。当通过关系属性建立关系后,外键字段会自动获得正确的值。
和append()相对,对关系属性调用remove()方法可以与对应的Article对象解除关系:
>>> foo.articles
[<Article id:2, title:'Ham', body:None, author_id:1>]
>>> foo.articles.remove(ham)
>>> foo.articles
[]
>>> db.session.commit()
>>> foo.articles
[]
>>>你也可以使用pop()方法操作关系属性,它会与关系属性对应的列表的最后一个Article对象解除关系并返回改对象。
如果想再commit之前,回退之前的操作,可以用db.session.rollback(),回退
不要忘记在操作结束后需要调用commit()方法提交数据库会话,这样才可以把数据写入数据库。
使用关系函数定义的属性不是数据库字段,而是类似于特定的查询函数。
当某个Article对象被删除时,在对应Author对象的articles属性调用时返回的列表也不会包含该对象。
>>> A1.articles
[<Aricle id: 1, title: 'Spam', body: None, author_id :1>, <Aricle id: 2, title: 'Ham', body: None, author_id :1>]
>>> db.session.delete(B2)
>>> A1.articles
[<Aricle id: 1, title: 'Spam', body: None, author_id :1>, <Aricle id: 2, title: 'Ham', body: None, author_id :1>]
>>> db.session.commit()
>>> A1.articles
[<Aricle id: 1, title: 'Spam', body: None, author_id :1>]
>>>在关系函数中,有很多参数可以用来设置调用关系属性进行查询时的具体行为。常用的SQLAlchemy关系函数参数如下所示:
| 参数名 | 说明 |
| back_populates | 定义反向引用,用于建立双向关系,在关系的另一侧也必须显示定义关系属性 |
| backref | 添加反向引用,自动在另一侧建立关系属性,是back_populates的简化版 |
| lazy | 指定如何加载相关记录,具体选项见下表 |
| uselist | 指定是否使用列表的形式加载记录,设为False则使用标量(scalar) |
| cascade | 设置级联操作 |
| order_by | 指定加载相关记录时的排序方式 |
| secondary | 在多对多关系中指定关联表 |
| primaryjoin | 指定多对多关系中的一级联结条件 |
| seconryjoin | 指定多对多关系中的二级联结条件 |
当关系属性被调用时,关系函数会加载相应的记录,下表列出了控制关系记录加载方式的lazy参数的常用选项。
常用的SQLAlchemy关系记录加载方式(lazy参数可选值):
| 关系加载方式 | 说明 |
| select | 在必要时一次性加载记录,返回包含记录的列表(默认值),等同于lazy=True |
| joined | 和父查询一样加载记录,但使用联结,等同于lazy=False |
| immediate | 一旦父查询加载就加载 |
| subquery | 类似于joined,不过将使用子查询 |
| dynamic | 不直接加载记录,而是返回一个包含相关记录的query对象,以便再继续附加查询函数对结果进行过滤 |
dynamic选项仅用于集合关系属性,不可用于多对一、一对一或是在关系函数中将uselist参数设为False的情况。
要避免使用dynamic来动态加载所有集合关系属性对应的记录,使用dynamic加载方式以为这每次操作关系都会执行一次SQL查询,这会造成潜在的性能问题。大多数情况下我们只需要使用默认值(select),只有在调用关系属性会返回大量记录,并且总是需要对关系属性返回的结果附加额外的查询时才需要动态加载(lazy=’dynamic’)。
建立双向关系
我们在Author类中定义了集合关系属性articles,用来获取某个作者拥有的多篇文章记录。在某些情况下,可能希望能在Articles类中定义一个类似的author关系属性,当被调用时返回对应的作者记录,这类返回单个值的关系属性被称为标量关系属性。而这种两侧都添加关系属性获取对方记录的关系我们称之为双向关系。双向关系并不是必须的,但在某些情况下会非常方便,双向关系的建立很简单,通过在关系的另一侧也创建一个relationship()函数,就可以在两个表之间建立双向关系。我们使用作者(Writer)和书(Booker)的一对多关系来进行演示,建立双向关系后的Writer和Book类如下:
app.py:基于一对多关系的双向关系
class Writer(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
# back_populates定义双向关系
# back_populates参数的值需要设为关系另一侧的关系属性名
books = db.relationship("Book", back_populates='writer')
def __repr__(self):
return "<Writer id:%r, name:%r>" % (self.id, self.name)
class Book(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(50), index=True)
writer_id = db.Column(db.Integer, db.ForeignKey("writer.id"))
writer = db.relationship('Writer', back_populates='books')
def __repr__(self):
return "<Book id:%r, title:%r, writer_id:%r>" % \
(self.id, self.title, self.writer_id)
@app.shell_context_processor
def make_shell_context():
return dict(db=db, Author=Author, Article=Article, Writer=Writer, Book=Book)
在app.shell_context_processor装饰的函数中加上两个类的返回,在flask shell中会自动加载Writer和Book两个类。‘
在多的这一侧Book类中,我们新创建了一个writer关系属性,这是一个标量关系属性,调用它会获取对应的Writer记录;而在Writer类中的books属性则用来获取对应的多个book记录,这关系函数中,我们使用back_populates参数来连接对方,back_populates参数的值需要设置为关系另一侧的关系属性名。
先运行db.create_all()创建这两个表到数据库中
>>> Writer
<class 'app.Writer'>
>>> db
<SQLAlchemy engine=sqlite:///F:\pythonTest\flask\flaskDemo\data.db>
>>> db.create_all()
>>> w1 = Writer(name='zhangsan')
>>> b1 = Book(title='python')
>>> b2 = Book(title='flask')
>>> db.session.add_all([w1,b1,b2])
>>> db.session.commit()
设置双向关系后,除了通过集合属性books来操作关系,也可以使用标量属性writer来进行关系操作。比如,将一个writer对象赋值为某个book对象的writer属性,就会和这个book对象建立关系:
>>> w1
<Writer id:1, name:'zhangsan'>
>>> b1
<Book id:1, title:'python', writer_id:None>
>>> b2
<Book id:2, title:'flask', writer_id:None>
>>> b1.writer=w1
>>> b1.writer
<Writer id:1, name:'zhangsan'>
>>> w1.books
[<Book id:1, title:'python', writer_id:1>]
>>> b2.writer=w1
>>> b2.writer
<Writer id:1, name:'zhangsan'>
>>> w1.books
[<Book id:1, title:'python', writer_id:1>, <Book id:2, title:'flask', writer_id:None>]
相对地,将某个book的writer属性设为None,就会解除与对应的Writer对象的关系:
>>> w1.books
[<Book id:1, title:'python', writer_id:1>, <Book id:2, title:'flask', writer_id:None>]
>>> b1.writer
<Writer id:1, name:'zhangsan'>
>>> b1.writer = None
>>> w1.books
[<Book id:2, title:'flask', writer_id:None>]
>>>当一个book对象修改writer属性,对应的writer对象的books属性也会跟着修改,修改后的writer属性对应的writer对象的books属性会修改
>>> b1.writer = w1
>>> w1.books
[<Book id:2, title:'flask', writer_id:None>, <Book id:1, title:'python', writer_i
>>> w2 = Writer(name='ksh')
>>> db.session.add(w2)
>>> w2
<Writer id:None, name:'ksh'>
>>> b1.writer = w2
>>> w1.books
[<Book id:2, title:'flask', writer_id:None>]
>>> w2.books
[<Book id:1, title:'python', writer_id:1>]
需要注意的是,我们只需要在关系的一侧操作关系,当为book对象的writer属性赋值后,对应writer对象的books属性会自动包含这个book对象。反之,当某个writer对象被删除后,对应的Book对象的writer属性被调用时的返回值也会被置位空(即NULL,会返回None)。其它关系模式建立双向关系的方式完全相同。
使用backref简化关系定义
在介绍关系函数的参数时,我们提到过,使用关系函数中backref参数可以简化双向关系的定义。以一对多关系为例,backref参数用来自动为关系另一侧添加关系属性,作为反向引用(back reference),赋予的值会作为关系另一侧的关系属性名称。比如,我们在Author一侧的关系函数中间backref参数设置为author,SQLAlchemy会自动为Article类添加一个author属性。为了避免和前面的实例命名冲突,我们使用歌手(Singer)和歌曲(Song)的一对多关系为例进行说明,分别创建Singer类和Song类,如下:
class Singer(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
def __repr__(self):
return "<Singer id: %r, name: %r>" % (self.id, self.name)
class Song(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50), index=True)
singer_id = db.Column(db.Integer, db.ForeignKey("singer.id"))
def __repr__(self):
return "<Song id:%r nem:%r>" % (self.id, self.name)在定义集合属性songs的关系函数中,我们将backref参数是为singer,这会同时在Song类中添加一个singe标量属性。我们只需要在定义这一个关系函数,虽然singer是一个“看不见的关系属性”,但是使用时和定义两个关系函数并使用back_populates参数的效果完全相同。
需要注意的是,使用backref允许我们仅在关系一侧定义另一侧的关系属性,但是在某些情况下,希望可以对在另一侧的关系属性进行设置,这时就需要使用backref()函数。backref()函数接收第一个参数作为在关系另一侧添加的关系属性名,其它关键字参数会作为关系另一侧关系函数的参数传入。比如,我们需要在关系另一侧“看不见的relationship()函数”中将uselist参数设为False,可以这样:
class Singer(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
# songs = db.relationship('Song', backref='singer')
songs = db.relationship('Song', backref=backref('singer', uselist=False))
def __repr__(self):
return "<Singer id: %r, name: %r>" % (self.id, self.name)
>>> from app import Singer
>>> from app import Song
>>> db.create_all()
>>> singer1 = Singer(name='eason')
>>> song1 = Song(name='十年')
>>> singer1
<Singer id: None, name: 'eason'>
>>> song1
<Song id:None nem:'十年'>
>>> song1.singer=singer1
>>> song1.singer
<Singer id: None, name: 'eason'>
>>> singer1.songs
[<Song id:None nem:'十年'>]
>>> song2 = Song(name='K歌之王')
>>> song2.singer=singer1
>>> song2
<Song id:None nem:'K歌之王'>
>>> singer1.songs
[<Song id:None nem:'十年'>, <Song id:None nem:'K歌之王'>]
# 提交数据库会话,落表
>>> db.session.add_all([singer1,song1,song2])
>>> singer1.id
>>> db.session.commit()
>>> singer1.id
1
>>> song1.id
1
>>> song2.id
2
尽管使用backref非常方便,但通常来说“显示好过隐式”,所以我们应该尽量使用back_populates定义双向关系
多对一
一对多关系反过来就是多对一关系,这两种关系模式分别从不同的视角出发,一个作者拥有多篇文章,反过来就是多篇文章属于同一个作者。为了便于区分,我们使用居民和城市来演示多对一关系:多个居民住在同一城市。多对一关系如下:
在例子中,Citizen类表示居民,City类表示城市。建立多对一关系后,我们将在Citizen类中创建一个标量关系属性city,调用它可以获取单个City对象。前面介绍过,关系属性在关系模式的出发侧定义。当出发点在“多”这一侧时,我们希望在Citizen类中添加一个关系属性对应的城市对象,因为这个关系属性返回单个值,我们称之为标量关系属性。在定义关系时,外键总是在“多”这一侧定义,所有在多对一关系中,外键和关系属性都在“多”这一侧定义,即City类中:
app.py:建立多对一关系
class Citizen(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
city_id = db.Column(db.Integer, db.ForeignKey("city.id"))
city = db.relationship("City")
class City(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)这时定义的city关系属性是一个标量关系(返回单一数据)。当Citizen.city被调用时,SQLAlchemy会根据外键字段city_id存储的值查找对应的City对象返回,即居民记录对应的城市记录。
>>> from app import Citizen, City
>>> city1 = City(name='beijiong')
>>> citizen1 = City(name='kong')
>>> citizen1.city=city1
>>> citizen1.city
<City (transient 1997173486368)>当建立双向关系时,如果不使用backref,那么一对多和多对一关系模式再定义上完全相同。我们通常会为一对多或多对一建立双向关系,这时将弱化这两种关系的区别,一律称为一对多关系。
一对一
我们将使用国家和首都来演示一对一关系,每个国家只有一个首都。反过来一个城市也只能作为一个国家的首都。一对一关系如下:

在示例程序中,Country类表示国家,Capital类表示首都。建立一对一关系后,我们将在Country类中创建一个标量关系capital,调用它会获取单个Capital对象,我们还在Capital类中创建一个标量关系属性country,调用它会获取单个的Country对象。
一对一的关系实际上是通过建立双向关系的一对多关系的基础上演化而来的。我们要确保关系两侧的关系属性都是标量属性,都只返回单个值,所以要在定义集合属性的关系函数中将uselist设置为False,这时一对多关系就转换为一对一关系。下面代码基于建立双向关系的一对多关系实现了一对一关系:
app.py:建立一对一关系
class Country(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(30), unique=True)
capital = db.relationship("Capital", uselist=False)
def __repr__(self):
return "<Country: %r>" % self.name
class Capital(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(30), unique=True)
country = db.relationship("Country")
country_id = db.Column(db.Integer, db.ForeignKey("country.id"))
def __repr__(self):
return "<Capital: %r>" % self.name“多”这一侧本身就是标量关系属性,不用做任何的改动(有外键的是“多”这一侧),而“一”这一侧的集合关系属性,通过将uselist参数设置为False后,将近返回对应的单个记录,而且无法再使用列表语义操作。
>>> from app import Country,Capital
>>> db.create_all()
>>> china = Country(name='china')
>>> beijing = Capital(name='beijing')
>>> db.session.add_all([china,beijing])
>>> china.capital
>>> china.capital=beijing
>>> china.capital
<Capital: 'beijing'>
>>> beijing.country
>>> beijing
<Capital: 'beijing'>
>>> db.session.commit()
>>> beijing.country
<Country: 'china'>
>>> china.capital
<Capital: 'beijing'>
>>> china.capital.append('tokyo')
Traceback (most recent call last):
File "<console>", line 1, in <module>
AttributeError: 'Capital' object has no attribute 'append'多对多
我们使用学生和老师来演示多对多关系:每个学生有多个老师,每个老师有多个学生。多对多关系示意图如下:
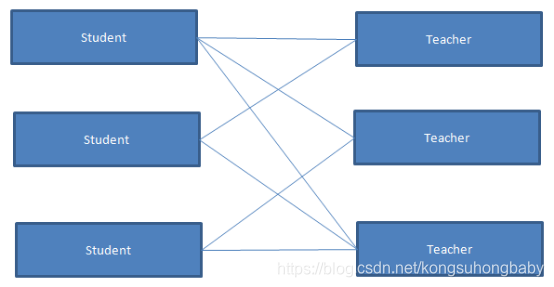
在实例程序中,Student类表示学生,Teacher类表示老师。在这两个模型之间建立多对多关系后,我们需要在Student类中添加一个集合关系属性teachers,调用它可以获取某个学生的多个老师,而不同的学生可以和同一个老师建立关系。
在一对一关系中,我们可以在“多”这一侧添加外键指向“一”这一侧,外键只能存储一个记录,但是在多个关系中,每一个记录都可以与关系另一侧的多个记录建立关系,关系两侧的模型都需要存储一组外键。在SQLAlchemy中,要想表示多对多关系,除了关系两侧的模型外,我们还需要创建一个关联表(association table)。关联表不存储数据,只用来存储关系两侧模型的外键对应关系。
association_table = db.Table("association",
db.Column("student_id", db.Integer, db.ForeignKey("student.id")),
db.Column("teacher_id", db.Integer, db.ForeignKey("teacher.id")))
class Student(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
grade = db.Column(db.String(20))
teachers = db.relationship('Teacher', secondary=association_table,
back_populates='students')
def __repr__(self):
return "<Student: %r>" % self.name
class Teacher(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
office = db.Column(db.String(20))
# back_populates, 定义双向关系
# back_populates参数的值需要设为关系另一侧的关系属性名
students = db.relationship("Student", secondary=association_table,
back_populates='teachers')
def __repr__(self):
return "<Teacher: %r>" % self.name
关联表使用db.Table类定义,传入的第一个参数是关联表的名称。我们在关联表中定义了两个外键字段:teacher_id字段存储Teacher类的主键,student_id存储Student类的主键。借助关联表这个中间人存储的外键对,我们可以把对对多关系分化成两个一对多关系,如下所示:
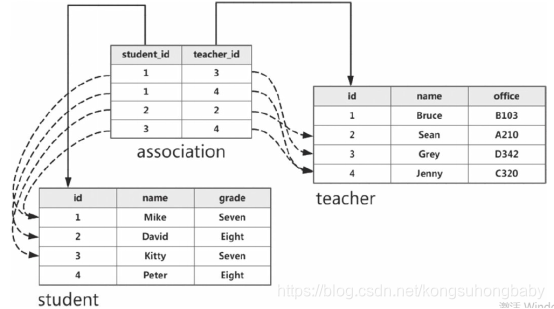
当我们需要查询某个学生记录的多个老师时,我们先通过学生和关联表的一对多关系查找多个包含该学生的关联表记录,然后后就可以从这些记录中再进一步获取每个关联表记录包含的老师记录。以上图的随机数据为例,假设学生记录的id为1,那么通过查找关联表中student_id字段为1的记录,就可以获取到对应的teacher_id值(分别为3和4),通过外键值就可以在teacher表里获取id为3和4的记录,最终,我们就获取到id为1的学生记录相关联的所有老师记录。
我们在Student类中定义一个teachers关系属性用来获取老师集合。在多对多关系中定义关系函数,除了第一个参数是关系另一侧的模型名称外,我们还需要添加一个secondary参数,把这个值设为关联的名称。
为了便于实现真正的多对多关系,我们需要建立双向关系。建立双向关系后,多对多关系会变得更加直观。在Student类上的teachers集合属性会返回所有关联的老师记录,而在Teacher类上的students集合属性会返回所有相关的学生记录
除了在声明关系时有所不同个,多对多关系模式在操作关系时和其他关系模式基本相同。调用关系属性student.teachers时,SQLAlchemy会直接返回关系另一侧的Teacher对象,而不是关联表记录,反之亦同。和其他关系模式中的结合关系属性一样,我们可以将关系属性teachers和students像列表一样操作。比如,当你需要为某一个学生添加老师时,对关系属性使用append()方法即可。如果你想要接触关系,那么可以使用remove()方法。
关联表由SQLAlchemy接管,它会帮我们管理这个表:我们只需要像往常一样通过操作关系属性来建立或解除关系,SQLAlchemy会自动在关联表中创建或删除对应的关联表记录,而不用手动操作关联表。
同样的,在多对多关系中我们也只需要在关系的一侧操作关系。当为学生A的teachers添加老师B后,调用老师B的students属性时返回的学生记录也会包含学生A,反之亦同。
>>> from app import Student, Teacher
>>> db.create_all()
>>> s1 = Student(name='xiaoxiao')
>>> t1 = Teacher(name='zhang')
>>> s2 = Student(name='ksh')
>>> t2 = Teacher(name='li')
>>> s1
<Student: 'xiaoxiao'>
>>> s2
<Student: 'ksh'>
>>> t1
<Teacher: 'zhang'>
>>> t2
<Teacher: 'li'>
>>> db.session.add_all([s1,s2,t1,t2])
>>> db.session.commit()
>>> s1.teachers
[]
>>> s1.teacher_id=1
>>> s2.teacher_id=2
>>> t1.student_id=1
>>> t2.studetn_id=2
>>> s1.teachers
[]
>>> db.session.commit()
>>> s1.teachers.append(t1)
>>> s1.teachers.append(t2)
>>> s1.teachers
[<Teacher: 'zhang'>, <Teacher: 'li'>]
>>> t1.students
[<Student: 'xiaoxiao'>]
>>>

















 1259
1259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









