






对对联的起源可以追溯到中国古代,它与中国文化有着密切的关系。
1. 最早的对对联出现在汉朝,当时称为“对句”。它起源于民间,后来逐渐成为文人雅士的精神寄托。
2. 唐代时,对对联的格式更加规范,并被称为“春联”。它成为春节张贴的主要内容,寓意吉祥。
3. 宋代以后,对对联被文人学士广泛使用,吟诵对对联也成为一个文人雅事。
4. 对对联的盛行反映了中国文化重视语言的节奏之美、意境的创造。它融合诗、书、画于一体。
5. 对对联的格式有对仗、平仄、字数等语言规律。它展现了中国文化里儒家思想中蕴含的理性思维。
6. 它还融合了道家的意境之美,富有哲理和涵养,成为中国文化的重要代表。
7. 今天,对对联仍广泛流传,成为中华传统文化的一个标志性符号。每逢春节,张贴春联成为最重要的仪式之一。
综上所述,对对联承载了中华文化的哲学观念和美学意蕴,它的产生和发展脱胎于中国古代文化传统,是中华文化的一个独特代表。
随着AI技术的进步,对对联这种传统技艺正在变为一种艺术创作的范畴,借助AI我们可以实现任意文字的对联绝唱,下面是我制作的一个在线对对联的小工具,有需要的可以拿走,
先看一下界面,先睹为快
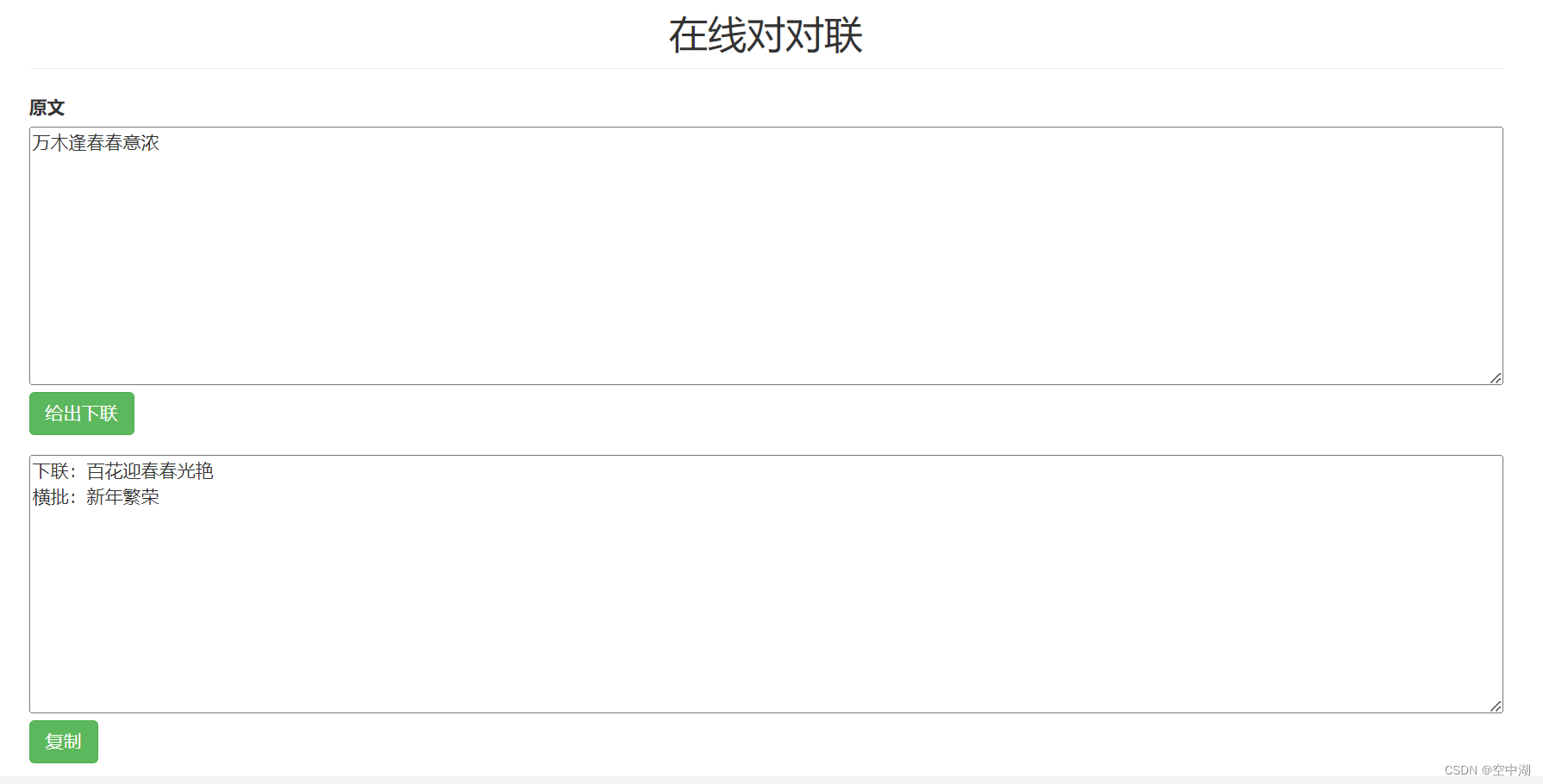
在线使用地址
在线对对联 https://zuowen.toolxq.com/front/ai/duilian/duilian
https://zuowen.toolxq.com/front/ai/duilian/duilian
上面只是一个小例子,AI还有无限的可能性值得我们去挖掘,喜欢对对联的小伙伴可以行动起来了,祝你好运。
下面是相关代码分享:
<div class="row">
<div class="col-xs-12">
</div>
<div class="col-md-12 col-xs-12">
<h2 class="text-center page-header">在线对对联</h2>
<form class="form-signin">
<div class="form-group">
<label>原文</label>
<textarea id="from" style="height: 200px;width: 100%;"></textarea>
<button class="btn btn-success" type="button" onclick="doTrans()">给出下联</button>
</div>
</form>
<div id="dataDiv">
<textarea id="to" style="height: 200px;width: 100%;"></textarea>
</div>
<button type="button" class="copy btn btn-success" data-clipboard-target="#to">复制</button>
</div>
</div>另外分享几个千古绝对供大家赏析
南通州北通州南北通州通南北;东当铺西当铺东西当铺当东西
雾锁山头山锁雾;天连水尾水连天
一掌擎天五指三长两短;六合插地七层四面八方
重重叠叠山曲曲环环路;高高下下树叮叮咚咚泉
风竹绿竹,风翻绿竹竹翻风;雪里白梅,雪映白梅梅映雪
望江楼,望江流,望江楼下望江流,江楼千古,江流千古;印月井,印月影,印月井中印月影,月井万年,月影万年。
欲知千古事;须读五车书。
虽是毫发生意;却是顶上功夫。
君凭我广开视野;我助君明察秋毫。
事与人便人称便;货招客来客自来。
此是春华秋实事业;并非东涂西抹文章。
词源倒流三江水;笔阵独扫千人军。
玉露磨来浓雾起;银笺染处淡云生。
银流鹄白三都贵;墨染鸦青五色奇。
笔架山高虹气现;砚池水满墨花香。
好将妙手夸针巧;漫把春风细剪裁。
欢迎春夏秋冬客;款待东西南北人。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









