






本想安装TensorFlowTTS的,费了老大劲还是不行。
参考:(【语音合成】TensorFlowTTS 中文文本转语音_王小希ww的博客-CSDN博客,
一篇文章教你语音合成入门,训练一个中文语音tts - 知乎)
后来找了coquiTTS,这个可以了:
)
一、安装conda,并配置国内镜像
二、创建tts的conda环境
1,环境名称:coquiTTS,指定python版本=3.8
conda create -n coquiTTS python=3.8
2,查看所有conda环境
conda info --envs
3,删除某个conda环境
conda env remove -n xxxname
三、安装coquiTTS
conda activate coquiTTS 切换进虚拟空间
pip install tts 安装tts,需要很久,有时候会报错内存不足。
四、如果内存不够,分配swap空间
如何查询swap大小,
free -m
因此,一般来说可以按照如下规则设置swap大小:
● 4G以内的物理内存,SWAP 设置为内存的2倍,不超过4G。
● 4-8G的物理内存,SWAP 等于内存大小。
● 8-64G 的物理内存,SWAP 设置为8G。
● 64-256G物理内存,SWAP 设置为16G。
https://blog.csdn.net/qq_32907195/article/details/129061992
bs=1M,count=4098,表示设置为4GB的swap
dd if=/dev/zero of=/swapfile bs=1M count=4098
chown root:root /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
mount -a
使系统开机时自启用,在文件/etc/fstab中添加一行:
/swapfile swap swap defaults 0 0
再free -m
就可以看到swap分区了。
五、安装好后,测试英文转英语:
tts --text "text for TTS" --out_path ~/workspace/pyworkspace/tts/genmp3/test_speech.wav
tts --list_models 查看已经装的model
六、测试中文转汉语:
语音合成工具Coqui TTS安装及体验_皮尔斯巴巴罗的博客-CSDN博客
下载语音包地址:
下载后,解压缩到某个目录,会有如下三个文件,后续命令需要用到:
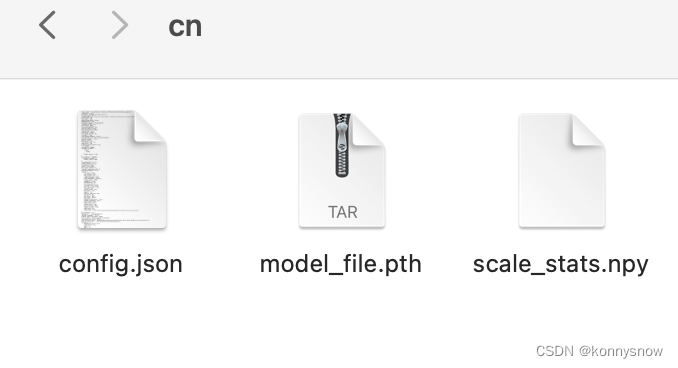
指定model的命令如下:
tts --model_path "/Users/xxx/tts/model/cn/model_file.pth.tar" --config_path "/Users/xxx/tts/model/cn/config.json" --out_path "/Users/xxx/tts/output/sound6.wav" --text "项目里增删改查的代码,目前都是代码工具自动生成的啊,很少手写。"
--model_path,指定为上面的pth文件,一般是tar后缀
--config_path,指定为上面的config.json文件
--out_path,要输出音频的路径文件名
--text,要转换的文本
以上参数都是用空格分开,最好引号包裹。

















 4120
4120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









