






计算机存储数据时,需要将数据分解成若干个字节进行存储。大端和小端是两种不同的字节序,这两种字节序的区别体现在高字节和低字节的顺序上。在计算机中,字节序的选择对于数据的读取和存储都有很大的影响。本文将介绍大端和小端存储以及它们之间的区别。
一、什么是大端和小端存储
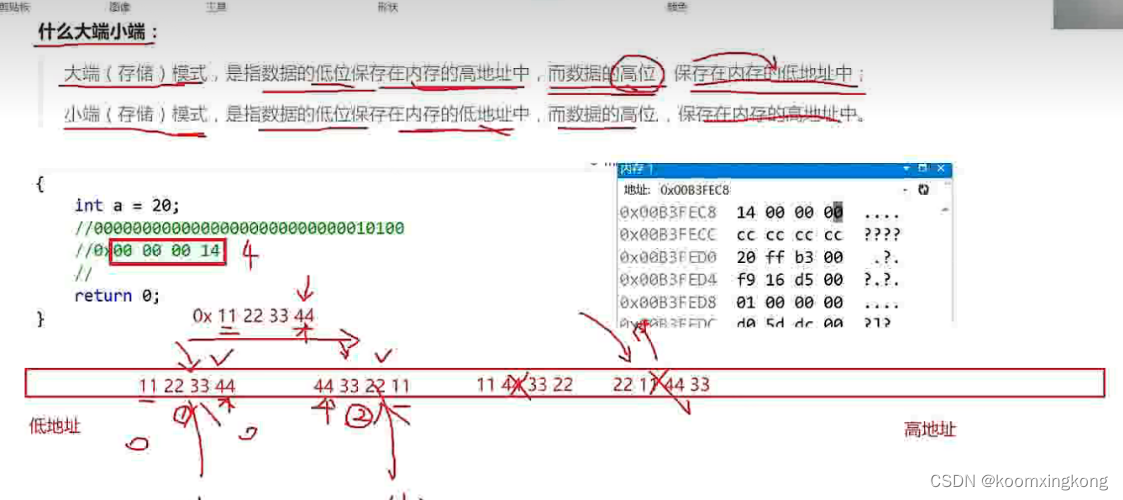
大端和小端存储指的是对于多字节数据的表示方式。在大端存储中,最高位字节排在最前面,最低位字节排在最后面;而在小端存储中,最低位字节排在最前面,最高位字节排在最后面。例如,对于十六进制数0x12345678,大端存储的表示方式是0x12 0x34 0x56 0x78,而小端存储的表示方式是0x78 0x56 0x34 0x12。
二、大端和小端存储的原理
大端存储和小端存储的区别在于存储时高位和低位的顺序不同。在计算机中,数据是以字节为单位进行存储的。在多字节数据中,比如一个4字节的整数,计算机会将它存储为4个字节的数据块。在大端存储中,数据块的高位字节存储在低地址,低位字节存储在高地址;而在小端存储中,数据块的低位字节存储在低地址,高位字节存储在高地址。这种存储方式的实现需要计算机硬件的支持。
三、大端和小端存储的应用
大端和小端存储的应用在于网络通信和文件格式。在网络通信中,不同的计算机之间需要进行数据交互,数据的字节序需要统一。因此,网络通信协议规定了数据传输的字节序。例如,在TCP/IP协议中,数据传输时采用的是大端存储。在文件格式中,也需要规定数据的字节序。例如,在JPEG文件格式中,采用的是小端存储。
四、如何确定一个系统的字节序
在确定一个系统的字节序时,可以通过以下两种方法来确定:
1.查看系统文档
可以查看系统的文档来确定系统的字节序。不同的操作系统可能采用不同的字节序,因此需要查看相应的文档。
2.编写测试程序
可以编写一个测试程序来确定系统的字节序。测试程序可以通过读取一个多字节整数的值,并将其转换成字节数组的形式来检测系统的字节序。该程序定义了一个32位无符号整数num,并将其赋值为0x12345678,然后通过将num的地址强制转换为char指针类型,获取num的内存中第一个字节的值,判断该值是0x78还是0x12,从而判断该系统使用的是小端存储还是大端存储。如果该值为0x78,则说明该系统使用小端存储;如果该值为0x12,则说明该系统使用大端存储。
#include <iostream>
#include <cstring>
int main() {
unsigned int num = 0x12345678;
char* ptr = reinterpret_cast<char*>(&num);
// 判断字节序
if (*ptr == 0x78) {
std::cout << "This system is using Little-Endian storage." << std::endl;
} else if (*ptr == 0x12) {
std::cout << "This system is using Big-Endian storage." << std::endl;
} else {
std::cout << "Unknown storage mode." << std::endl;
}
return 0;
}
我们可以看到,在vs2022下,运行结果告诉我们计算机采用的是小端存储,当然,大多情况下PC端都是采用小端存储。
五、总结
大端和小端存储是计算机存储数据时用到的两种不同的字节序。它们的区别在于高字节和低字节的顺序。在网络通信和文件格式中,需要规定数据的字节序。确定一个系统的字节序可以通过查看系统文档或编写测试程序来实现。在实际应用中,需要根据不同的需求选择适合的字节序。















 2665
2665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









