







一、引入
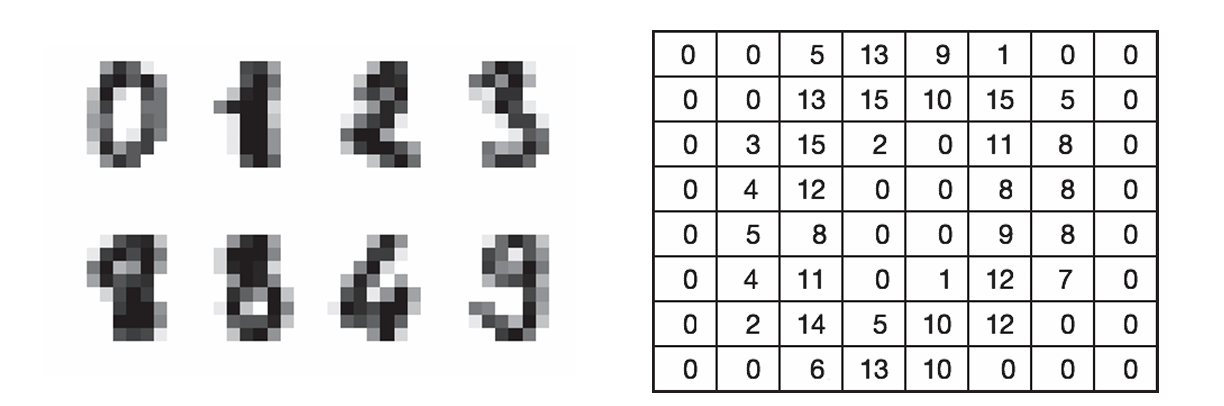
本文将介绍如何处理才能将图像数据作为机器学习的输入数据。这里以灰度图像数据为例进行说明(如下图)。灰度图像指的是图像中的每个像素只表示亮度的图像。大家可以思考一下,要想把这样的图像数据作为输入数据,需要进行什么处理呢?
图像数据和表格形式的数据
二、将像素信息作为数值使用
一种方法是直接将各像素的信息作为数值使用。下表是将图像数据转换为向量数据的例子。如果是简单的图像识别问题,就可以使用这种简单的转换建立一个具有一定精度的模型。

虽然通过这种转换,可以创建机器学习模型的输入数据,但由于具有二维关系的像素数据被转换为了一维向量,所以可以说重要的信息被丢弃了。有些模型会在保留图像的二维关系的前提下直接将其作为输入数据进行处理,比如在图像识别中常用的深度学习使用的就是像素的近邻像素的信息。
下面是将图像数据转换为向量数据的示例代码。代码中使用第三方Python包Pillow将图像(png)数据转换为了向量数据。
from PIL import Image
import numpy as np
img = Image.open('mlzukan-img.png').convert('L')
width, height = img.size
img_pixels = []
for y in range(height):
for x in range(width):
# 通过getpixel获取指定位置的像素值
img_pixels.append(img.getpixel((x,y)))
print(img_pixels)
三、输入机器学习模型
前面介绍了如何将图像数据转换为向量数据,接下来我们尝试实际使用转换后的数据来创建机器学习模型。这里我们使用灰度手写数字数据建立一个模型,用于预测从0到9的10个数字。由于scikit-learn 的 datasets模块能够获取转换后的向量数据,所以我们使用它来获取输入数据。
从预测结果来看,使用了向量数据的模型成功地进行了高精度的预测。
from sklearn import datasets
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
digits = datasets.load_digits()
n_samples = len(digits.images)
# 将8x8的二维图像数据展平为64维向量(-1表示自动计算维度)
data = digits.images.reshape((n_samples, -1))
model = RandomForestClassifier()
model.fit(data[:n_samples // 2], digits.target[:n_samples // 2])
expected = digits.target[n_samples // 2:]
predicted = model.predict(data[n_samples // 2:])
print(metrics.classification_report(expected, predicted))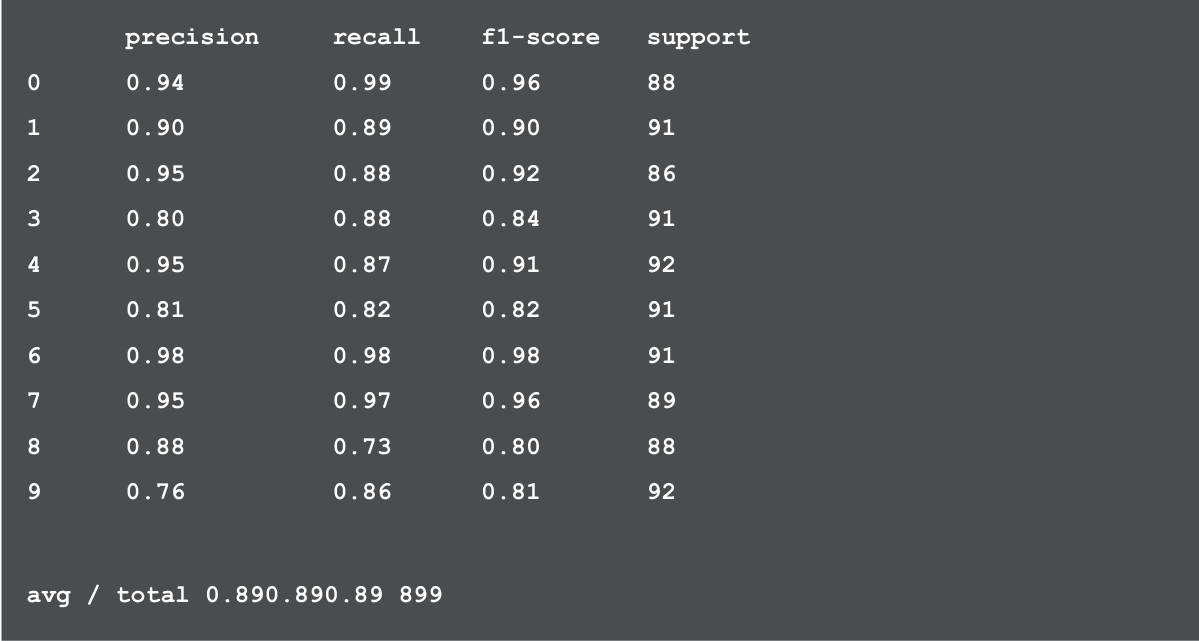



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











