







前言
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成;接下来的几篇文章将重点分析ShardingSphere-JDBC,从数据分片,分布式主键,分布式事务,读写分离,弹性伸缩等几个方面来介绍。
简介
ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。整体架构图如下(来自官网):
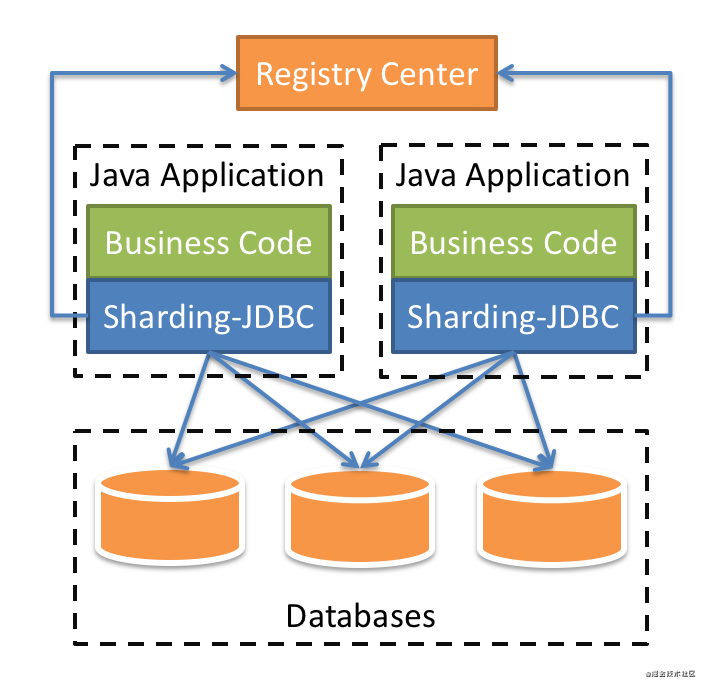
ShardingSphere-JDBC包含了众多的功能模块包括数据分片,分布式主键,分布式事务,读写分离,弹性伸缩等等;作为一个数据库中间件最核心的功能当属数据分片了,ShardingSphere-JDBC提供了很多分库分表的策略和算法,接下来看看具体是如何使用这些策略的;
数据分片
作为一个开发者我们希望中间件可以帮我们屏蔽底层的细节,让我们在面对分库分表的场景下,可以像使用单库单表一样简单;当然ShardingSphere-JDBC不会让大家失望,引入了分片数据源、逻辑表等概念;
分片数据源和逻辑表
- 逻辑表:逻辑表是相对物理表来说的,通常做分表处理,某一张表会被分成多张表,比如订单表被拆分成10张表,分别是t_order_0到t_order_9,而对应的逻辑表就是
t_order,对于开发者来说只需要使用逻辑表即可; - 分片数据源:对于分库来说,通常会有多个库,或者说是多个数据源,所以这些数据源需要被统一管理起来,引入了分片数据源的概念,常见的
ShardingDataSource
有了以上两个最基本的概念当然还不够,还需要分库分表策略算法帮助我们做路由处理;但是这两个概念可以让开发者有一种使用单库单表的感觉,就像下面这样一个简单的实例:
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig,
new Properties());
Connection conn = dataSource.getConnection();
String sql = "select id,user_id,order_id from t_order where order_id = 103";
PreparedStatement preparedStatement = conn.prepareStatement(sql);
ResultSet set = preparedStatement.executeQuery();
以上根据真实数据源列表,分库分表策略生成了一个抽象数据源,可以简单理解就是ShardingDataSource;接下来的操作和我们使用jdbc操作正常的单库单表没有任何区别;
分片策略算法
ShardingSphere-JDBC在分片策略上分别引入了分片算法、分片策略两个概念,当然在分片的过程中分片键也是一个核心的概念;在此可以简单的理解分片策略 = 分片算法 + 分片键;至于为什么要这么设计,应该是ShardingSphere-JDBC考虑更多的灵活性,把分片算法单独抽象出来,方便开发者扩展;
分片算法
提供了抽象分片算法类:ShardingAlgorithm,根据类型又分为:精确分片算法、区间分片算法、复合分片算法以及Hint分片算法;
- 精确分片算法:对应
PreciseShardingAlgorithm类,主要用于处理=和IN的分片; - 区间分片算法:对应
RangeShardingAlgorithm类,主要用于处理BETWEEN AND,>,<,>=,<=分片; - 复合分片算法:对应
ComplexKeysShardingAlgorithm类,用于处理使用多键作为分片键进行分片的场景; - Hint分片算法:对应
HintShardingAlgorithm类,用于处理使用Hint行分片的场景;
以上所有的算法类都是接口类,具体实现交给开发者自己;
分片策略
分片策略基本和上面的分片算法对应,包括:标准分片策略、复合分片策略、Hint分片策略、内联分片策略、不分片策略;
-
标准分片策略:对应
StandardShardingStrategy类,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法,PreciseShardingAlgorithm是必须的,RangeShardingAlgorithm可选的;public final class StandardShardingStrategy implements ShardingStrategy { private final String shardingColumn; private final PreciseShardingAlgorithm preciseShardingAlgorithm; private final RangeShardingAlgorithm rangeShardingAlgorithm; } -
复合分片策略:对应
ComplexShardingStrategy类,提供ComplexKeysShardingAlgorithm分片算法;public final class ComplexShardingStrategy implements ShardingStrategy { @Getter private final Collection<String> shardingColumns; private final ComplexKeysShardingAlgorithm shardingAlgorithm; }可以发现支持多个分片键;
-
Hint分片策略:对应
HintShardingStrategy类,通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略;提供HintShardingAlgorithm分片算法;public final class HintShardingStrategy implements ShardingStrategy { @Getter private final Collection<String> shardingColumns; private final HintShardingAlgorithm shardingAlgorithm; } -
内联分片策略:对应
InlineShardingStrategy类,没有提供分片算法,路由规则通过表达式来实现; -
不分片策略:对应
NoneShardingStrategy类,不分片策略;
分片策略配置类
在使用中我们并没有直接使用上面的分片策略类,ShardingSphere-JDBC分别提供了对应策略的配置类包括:
StandardShardingStrategyConfigurationComplexShardingStrategyConfigurationHintShardingStrategyConfigurationInlineShardingStrategyConfigurationNoneShardingStrategyConfiguration
实战
有了以上相关基础概念,接下来针对每种分片策略做一个简单的实战,在实战前首先准备好库和表;
准备
分别准备两个库:ds0、ds1;然后每个库分别包含两个表:t_order0,t_order1;
CREATE TABLE `t_order0` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) NOT NULL,
`order_id` bigint(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
准备真实数据源
我们这里有两个数据源,这里都使用java代码的方式来配置:
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
// 配置第一个数据源
BasicDataSource dataSource1 = new BasicDataSource();
dataSource1.setDriverClassName("com.mysql.jdbc.Driver");
dataSource1.setUrl("jdbc:mysql://localhost:3306/ds0");
dataSource1.setUsername("root");
dataSource1.setPassword("root");
dataSourceMap.put("ds0", dataSource1);
// 配置第二个数据源
BasicDataSource dataSource2 = new BasicDataSource();
dataSource2.setDriverClassName("com.mysql.jdbc.Driver");
dataSource2.setUrl("jdbc:mysql://localhost:3306/ds1");
dataSource2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









