






ICLR(International Conference on Learning Representations)是人工智能领域顶级学术会议之一,主要聚焦于深度学习及其在表示学习(representation learning)方面的最新研究进展,是学术界和工业界展示最前沿机器学习成果的重要平台。ICLR 2025将于4月24日至28日在新加坡博览中心举行,本届论文录用结果揭晓,本次大会共收到11672篇有效投稿,最终有3706篇论文中稿,录取率为31.75%。
快手凭借其在深度学习算法研发领域的持续深耕与技术创新,共有11篇高质量学术论文成功入选。这些研究成果涵盖大规模视觉-语言模型、可控视频生成、3D人脸动画生成模型等前沿研究方向,不仅体现了研发团队在跨模态理解、生成式AI等核心领域的关键技术突破,更彰显了企业在人工智能研究方面的国际竞争力。

论文01:SVBench: A Benchmark with Temporal Multi-Turn Dialogues for Streaming Video Understanding
| 项目地址:https://github.com/yzy-bupt/SVBench
| 论文简介:
尽管大型视觉语言模型(LVLMs)在现有基准测试中取得了显著进展,但在新兴的长上下文流媒体视频理解领域,其适用性仍缺乏合适的评估体系。当前的视频理解基准通常侧重于孤立的单实例文本输入,而未能评估模型在视频流全时长内持续进行时序推理的能力。
为弥补这些缺陷,我们提出了一个具有时序多轮问答链的开拓性基准SVBench,专门用于全面评估当前LVLMs在流媒体视频理解中的能力。我们设计了半自动化标注流程,从1,353个流媒体视频中构建了49,979个问答对,包括生成代表视频片段连续多轮对话的问答链,以及在连续问答链间建立时序关联。通过对14个模型进行对话式评估和流式评估的实验结果表明,虽然闭源的GPT-4o模型表现最优,但大多数开源LVLMs在长上下文流媒体视频理解方面仍面临挑战。我们还构建了StreamingChat模型,该模型在SVBench上显著超越开源LVLMs,并在多样化视觉语言基准测试中达到可比性能。我们期望SVBench能够通过提供对当前LVLMs的全面深入分析,推动流媒体视频理解领域的研究进展。
论文02:3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
| 项目地址:https://github.com/KwaiVGI/3DTrajMaster
| 论文简介:
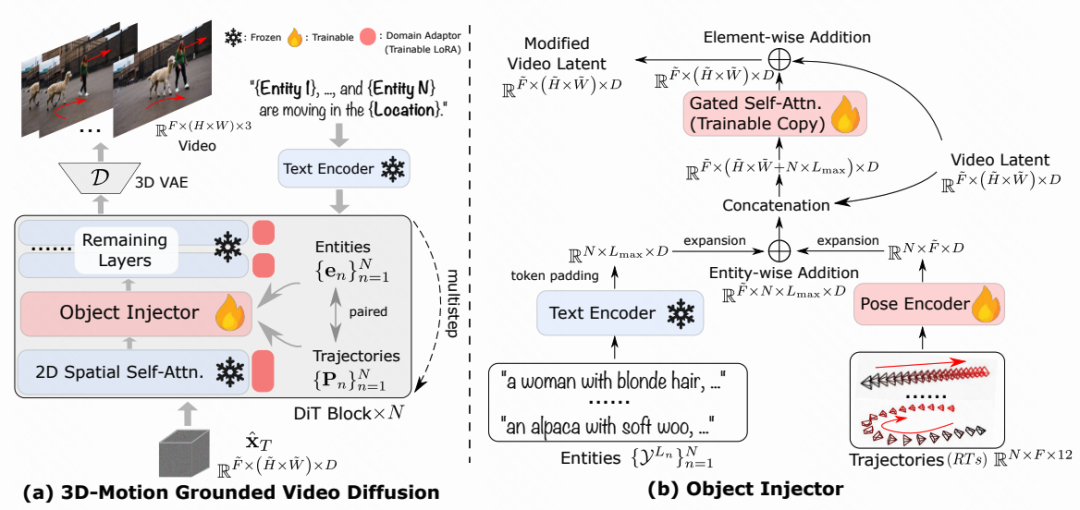
现有的可控视频生成方法主要利用二维控制信号来调控物体运动,虽已取得显著合成效果,但二维控制信号本质上难以充分表达物体运动的三维本质。
为解决这一难题,我们提出一个基于用户设定实体6自由度位姿(位置与旋转)序列的三维空间多实体动力学调控框架3DTrajMaster。该系统的核心在于创新的即插即用型三维运动基准化物体注入模块,该模块通过门控自注意力机制将多输入实体与其三维轨迹深度融合。此外,我们采用注入式架构以保持视频扩散模型先验,这对系统的泛化能力至关重要。为缓解视频质量衰减,我们在训练阶段引入领域适配器,并在推理阶段采用退火采样策略。针对训练数据匮乏问题,我们构建了360-Motion数据集:首先对齐采集的三维人体与动物资产与GPT生成的轨迹数据,随后在多样化三维虚幻引擎平台上使用12组均匀环绕摄像头捕获其运动。大量实验表明,3DTrajMaster在多实体三维运动控制的准确性与泛化性方面均达到当前最优水平。
论文03:Cafe-Talk: Generating 3D Talking Face Animation with Multimodal Coarse- and Fine-grained Control
| 项目地址:https://harryxd2018.github.io/cafe-talk/
| 论文简介:
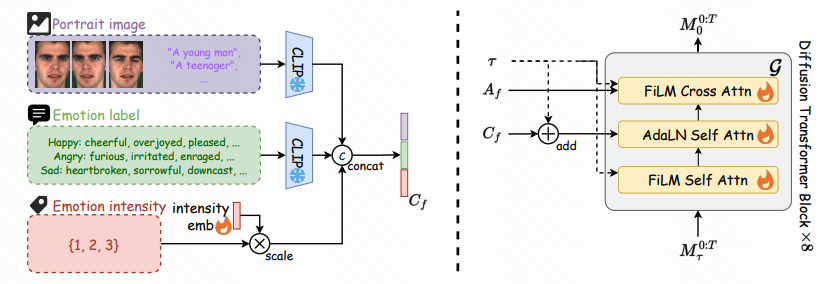
语音驱动的3D人脸动画方法需同时实现精准的唇形同步与可控的表情生成。现有方法仅采用离散情感标签对整段序列进行全局表情控制,限制了时空域内的灵活细粒度面部调控。
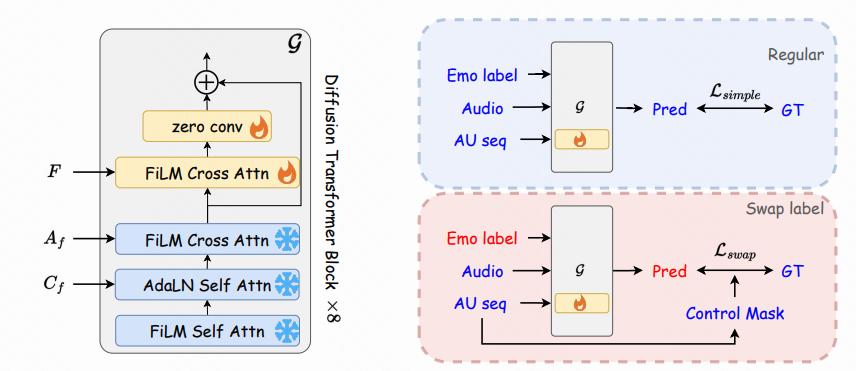
为此,我们提出一种基于扩散-Transformer架构的3D人脸动画生成模型Cafe-Talk,通过融合粗粒度与细粒度的多模态控制条件实现同步优化。然而,多重条件的耦合性对模型性能提出了挑战。为解耦语音与细粒度控制条件,我们采用两阶段训练策略:首先仅基于语音音频和粗粒度条件预训练模型,随后通过提出的细粒度控制适配器(Fine-grained Control Adapter)逐步引入以动作单元(Action Units, AUs)表征的细粒度指令,避免对唇音同步的干扰。针对粗-细粒度条件的解耦,我们设计了交换标签训练机制(Swap-label training mechanism),确保细粒度条件的主导性,并开发了基于掩码的分类器无关引导技术(Mask-based Classifier-Free Guidance)以调节细粒度控制的强度。此外,通过文本-AU对齐技术引入基于文本的检测器,支持自然语言用户输入,进一步扩展多模态控制能力。大量实验表明,Cafe-Talk在唇形同步精度与表情自然度上均达到最先进水平,并在用户研究中获得细粒度控制的高接受度。
论文04:Making Transformer Decoders Better Differentiable Indexers
| 项目地址:https://openreview.net/pdf?id=bePaRx0otZ
| 论文简介:
检索任务旨在从海量数据集中筛选出与查询/用户最相关的top-k项。传统检索模型通过将查询/用户与物品表征为嵌入向量,并采用近似最近邻(ANN)搜索实现检索。近期研究提出一种生成式检索方法,其核心创新在于:将物品表示为标记序列,并基于解码器模型进行自回归训练。相较传统方法,该方法采用更复杂的模型架构,并在训练过程中整合索引结构,从而获得更优性能。然而,现有方法仍存在两阶段流程的固有缺陷:索引构建与检索模型相互割裂,限制了模型整体能力。此外,现有索引构建方法通过在欧氏空间对预训练物品表征进行聚类实现,但现实场景的复杂性使得此类方法难以保证准确性。
为解决上述问题,本文提出检索与索引统一框架URI。该框架通过以下机制实现突破:
-
索引构建与检索模型(通常为Transformer解码器)的强一致性保障;
-
索引构建与解码器训练的同步优化,使索引直接由解码器内生构建;
-
摒弃基于欧氏空间的单侧物品表征,转而在查询-物品交互空间中构建索引。
通过在三个真实数据集上的实验对比,URI展现出显著优于现有方法的性能。
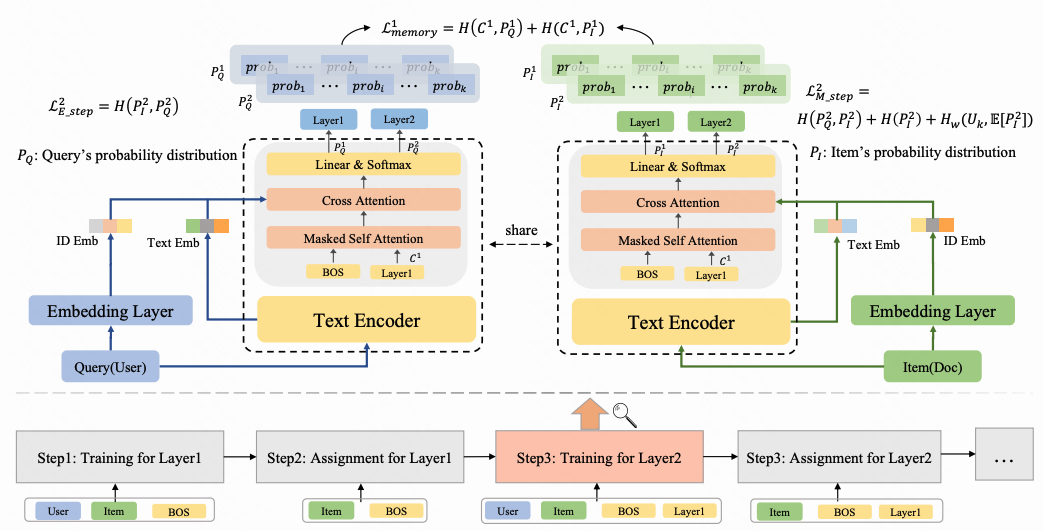
论文05:Pyramidal Flow Matching for Efficient Video Generative Modeling
| 项目地址:https://pyramid-flow.github.io/
| 论文简介:
视频生成需要对广袤的时空空间进行建模,这对计算资源和数据使用提出了极高要求。为降低复杂度,主流方法采用级联架构以避免直接训练全分辨率潜在空间。尽管降低了计算需求,但各子阶段的独立优化阻碍了知识共享并牺牲了灵活性。
本文提出统一的金字塔流匹配算法,将原始去噪轨迹重新诠释为多级金字塔阶段,其中仅最终阶段在全分辨率运行,从而实现更高效的视频生成建模。通过精心设计,不同金字塔阶段的流可相互链接以保持连续性;同时,我们构建了时域金字塔自回归视频生成框架以压缩全分辨率历史信息。整个系统可通过端到端方式联合优化,并仅需单一统一的扩散Transformer(Diffusion Transformer)。大量实验表明,该方法支持在20.7k A100 GPU训练小时内生成768p分辨率、24帧率的高质量5秒(最高达10秒)视频。
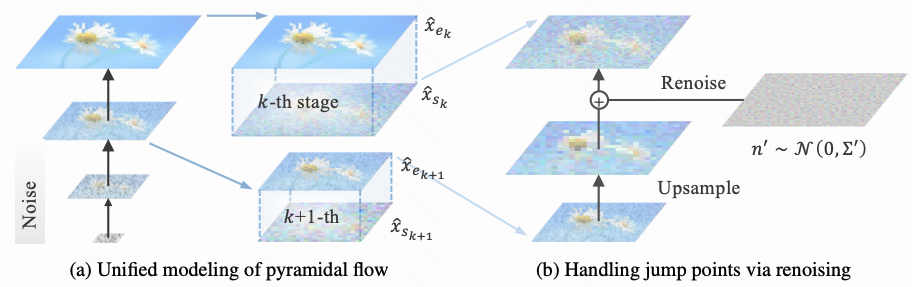
论文06:RecFlow: An Industrial Full Flow Recommendation Dataset
| 项目地址:https://github.com/RecFlow-ICLR/RecFlow
| 论文简介:
工业推荐系统采用多阶段流程,将海量内容库中的物品逐步筛选并推送给用户,以在效果与效率之间实现平衡。现有的推荐系统基准数据集主要聚焦于曝光空间,在此空间内进行新算法的训练与评估。然而,当这些算法迁移至真实工业推荐系统时,面临两大关键挑战:
-
忽视规模远超曝光空间的未曝光物品空间,而两者差异对推荐系统整体性能有深刻影响;
-
忽视工业推荐系统中多个阶段间复杂的相互作用,导致系统整体性能次优。
为弥合离线推荐基准与真实在线环境间的鸿沟,我们推出首个工业级全流程推荐数据集RecFlow。与现有数据集不同,RecFlow不仅包含曝光空间样本,还涵盖推荐漏斗中各阶段被过滤的未曝光样本。该数据集包含:基于42,000用户对近900万项目的3,800万次交互数据,以及通过930万次在线请求在37天内收集的横跨6个流程阶段的19亿阶段样本。基于RecFlow,我们开展探索实验验证其在推荐算法创新中的潜力:引入各阶段的未曝光样本可显著提升算法效果。部分算法已在快手平台上线并持续产生显著收益。我们发布RecFlow作为推荐领域首个完整的全流程基准数据集,支持以下研究方向:全流程算法设计(包括选择偏差研究、去偏算法、多阶段一致性与最优性)、多任务推荐及用户行为建模。
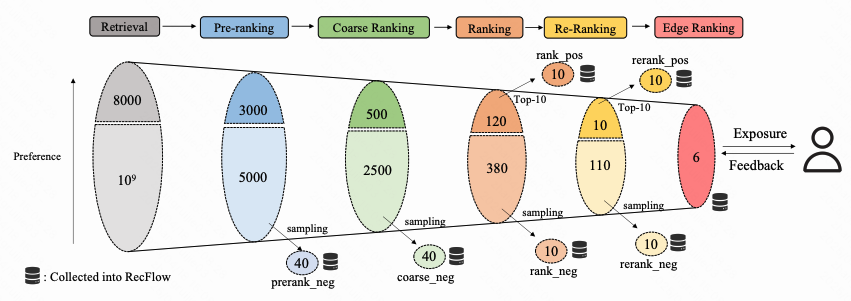
论文07:Solving Token Gradient Conflict in Mixture-of-Experts for Large Vision-Language Model
| 项目地址:https://github.com/longrongyang/STGC
| 论文简介:
混合专家模型(MoE)在大型视觉语言模型(LVLMs)研究中受到广泛关注。该方法通过稀疏模型替代稠密模型,在保持可比性能的同时,仅激活少量参数进行推理,从而显著降低计算成本。现有LVLM中的MoE方法促使不同专家专注于不同token,通常通过路由模块预测每个token的路径。然而,路由模块并未针对专家内token产生的不同参数优化方向进行优化,这可能导致同一专家内token间的严重干扰。
为解决该问题,本文提出基于token级梯度分析的token梯度冲突消解方法STGC。具体而言,我们首先通过token级梯度识别专家内的冲突token,随后设计定制化正则损失,促使冲突token从当前专家路由至其他专家,从而降低专家内token间的干扰。该方法可作为即插即用模块适配多种LVLM方法,大量实验结果验证了其有效性。
论文08:Stable Segment Anything Model
| 项目地址:https://github.com/fanq15/Stable-SAM?tab=readme-ov-file
| 论文简介:
尽管Segment Anything模型(SAM)在高质量提示下能够实现卓越的可提示分割效果,但这些提示通常需要较高的标注技巧才能生成。
为了使SAM对随意提示更具鲁棒性,本文首次全面分析了SAM在不同提示质量(尤其是边界框不精确和点数不足)下的分割稳定性。我们的关键发现表明,当输入此类低质量提示时,SAM的掩码解码器倾向于激活偏向背景或局限于特定物体局部的图像特征。为缓解此问题,我们的核心思路是通过调整图像特征的采样位置和幅度,仅对SAM的掩码注意力进行校准,同时保持原始SAM模型架构和权重不变。由此提出的可变形采样插件(Deformable Sampling Plugin)使SAM能够以数据驱动的方式自适应地将注意力转移到提示目标区域。在推理阶段,我们进一步提出动态路由插件(Dynamic Routing Plugin),根据输入提示质量动态切换SAM的可变形采样模式与常规网格采样模式。因此,我们的解决方案(Stable-SAM)具备以下优势:
-
显著提升SAM在广泛提示质量下的分割稳定性;
-
完整保留SAM原有的高效可提示分割能力与通用性;
-
仅需极少可学习参数(0.08 M)且支持快速适配。
大量实验验证了该方法的有效性和优势,表明Stable-SAM为"分割万物"任务提供了一个更鲁棒的解决方案。
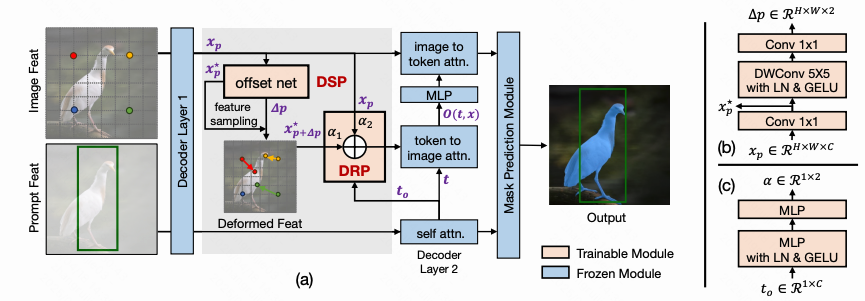
论文09:SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints
| 项目地址:
https://jianhongbai.github.io/SynCamMaster/
| 论文简介:
近年来,视频扩散模型在模拟真实世界动态与3D一致性方面展现出卓越能力。这一进展促使我们探索此类模型在跨视角动态一致性保持方面的潜力,该特性在虚拟拍摄等应用中备受关注。与现有聚焦于单物体多视角生成以实现4D重建的方法不同,我们的研究旨在通过六自由度(6 DoF)相机位姿生成任意视角、多相机同步的开放世界视频。为此,我们提出了一种即插即用模块,通过微调预训练文本到视频模型实现多相机视频生成,确保跨视角内容一致性。具体而言,我们设计了多视角同步模块以促进视角间的内容与几何一致性。鉴于高质量训练数据的稀缺性,我们还提出了一种渐进式训练方案,通过融合多相机图像与单目视频作为Unreal Engine渲染多相机视频的补充。这种综合性策略显著提升了模型性能。实验结果表明,我们提出的方法在现有竞争方法与基线模型上均表现出优越性。此外、该工作提出了多视角同步视频数据集SynCamVideo-Dataset用于多视角视频生成的研究。
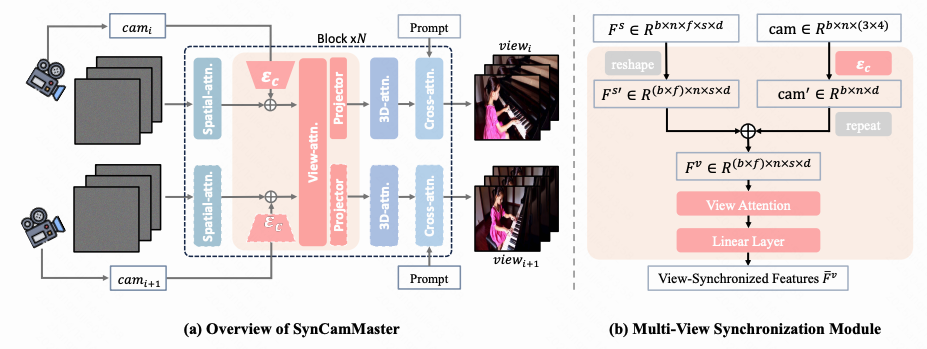
论文10:TaskGalaxy: Scaling Multi-modal Instruction Fine-tuning with Tens of Thousands Vision Task Types
| 项目地址:https://github.com/Kwai-YuanQi/TaskGalaxy
| 论文简介:
多模态视觉语言模型正凭借模型架构、训练技术及高质量数据的进步,在开放世界应用中崭露头角。然而,特定任务数据不足严重制约了其性能,导致泛化能力弱化与输出偏差。现有增强微调数据集任务多样性的方法受限于人工任务标注的高成本,通常仅能产生数百种任务类型。
为此,我们提出一个包含19,227种层次化任务类型(含413,648样本)的大规模多模态指令微调数据集TaskGalaxy。该数据集通过GPT-4o从少量人工定义任务出发进行任务扩展,利用CLIP与GPT-4o筛选与开源图像最匹配的任务,并生成相关问答对;通过多模型协同确保样本质量。这种自动化流程在提升任务多样性的同时保障了数据质量,显著减少人工干预。将TaskGalaxy应用于LLaVA-v1.5与InternVL-Chat-v1.0模型后,在16项基准测试中均取得显著性能提升,充分验证任务多样性的关键作用。
论文11:ReDeEP: Detecting Hallucination in Retrieval-Augmented Generation via Mechanistic Interpretability
| 项目地址:https://github.com/Jeryi-Sun/ReDEeP-ICLR
| 论文简介:
Retrieval-Augmented Generation(RAG)模型通过结合外部知识以减少幻觉问题,但即使检索到准确的上下文,RAG模型仍可能在生成过程中产生与检索信息相冲突的“幻觉”输出。
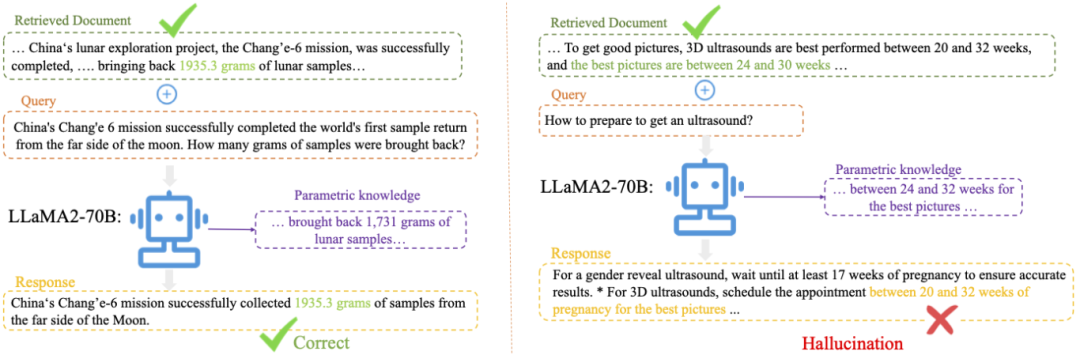
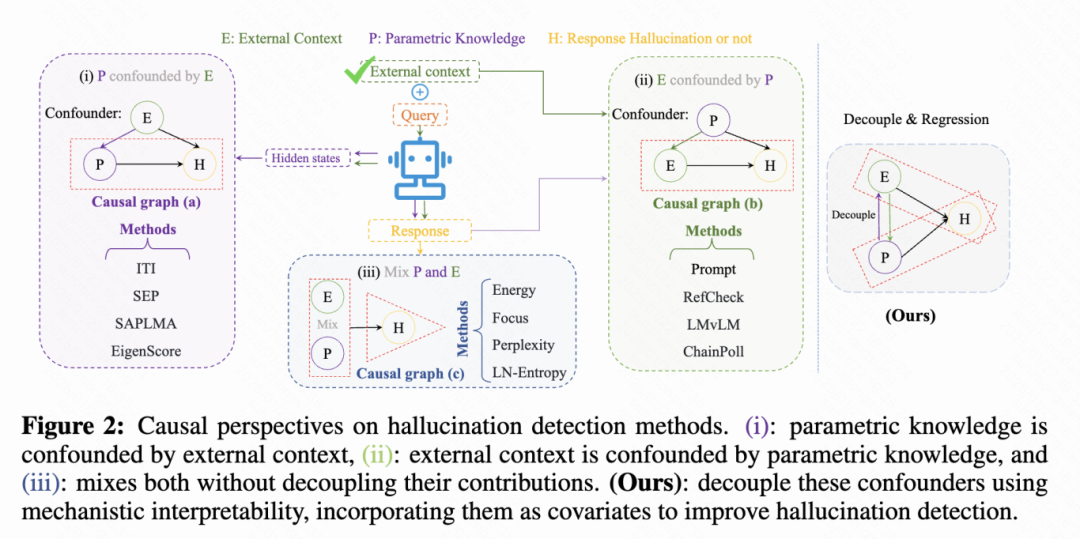
我们的研究聚焦于:
1. 幻觉来源
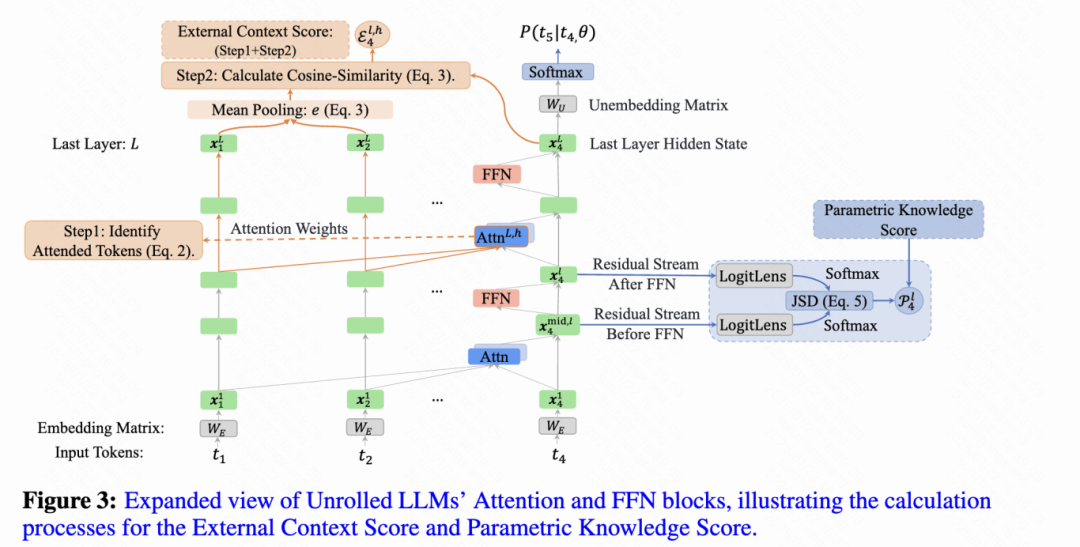
通过机制解释性 MechanisticInterpretability 分析 LLM 模型内部的注意力和前馈网络(Feed-Forward Network,FFN),我们发现:
- 某些注意力头(称为 Copying Heads)在获取外部上下文时,经常出现信息丢失或未能有效“拷贝”外部知识的现象。
- 部分深层 FFN(称为 Knowledge FFNs)过度向残差流中注入参数化知识 ParametricKnowledge,可能“淹没”外部上下文。
2. 提出方法:
ReDeEP RegressingDecoupledExternalcontextandParametricknowledge
-
将模型对外部上下文和参数化知识的利用进行显式解耦,并通过多元线性回归来检测幻觉倾向。
-
提供两种检测粒度:Token-level 和 Chunk-level,兼顾精细度与计算效率。
3. 改进模型生成:
AARF AddAttentionReduceFFN
-
在推理过程中,无需额外训练,依据实时“幻觉分数”对注意力和 FFN 的输出进行动态加权调控。
-
引导模型更多依赖外部知识,同时抑制过度依赖内部参数化知识,从而显著降低幻觉。


















 3982
3982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









