








做实验离不开写代码,快速写出代码的能力是提升实验效率的关键,本篇博客将具体介绍实验所依赖的代码的结构,实验过程中可以提升效率与质量的一些基本习惯。
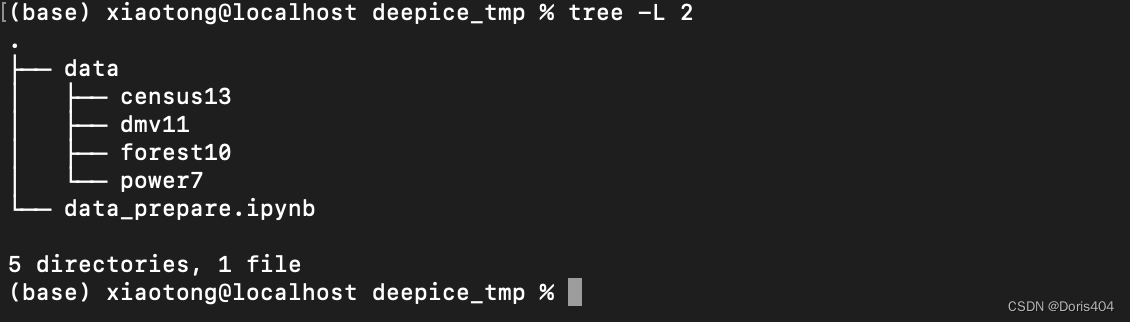
项目框架初始状态
实验代码主要由:数据模块, 数据处理模块,模型搭建模块,模型训练模块,实验结果导出模块,日志模块,以及自定义模块组成。
项目开始前实验者应该通过阅读大量文献了解了领域内其他工作的细节(方法,数据,实验等),这部分内容可以写入README.md文档中。一个比较好的形式是,总结阅读过的论文所提到的方法,代码,以及数据,形成一个表格。

除此之外,在确认了方向后,可以在README.md中写下自己的目标,在实验进行中也可以把更新记载到README.md中方便自己不偏离原来的目标。
数据模块:data文件夹
在项目开始阶段,可以确认的是原始数据模块。因而在创立自己的项目文件时,应该已经对实验所需要的数据有清楚的了解,并且将所有的数据都整理好放在一个文件夹下。这里推荐一个项目文件夹的结构是,项目根目录下创建data文件夹,在data文件夹中按照数据的简称建立多个文件夹用于放置不同数据的相关名称。
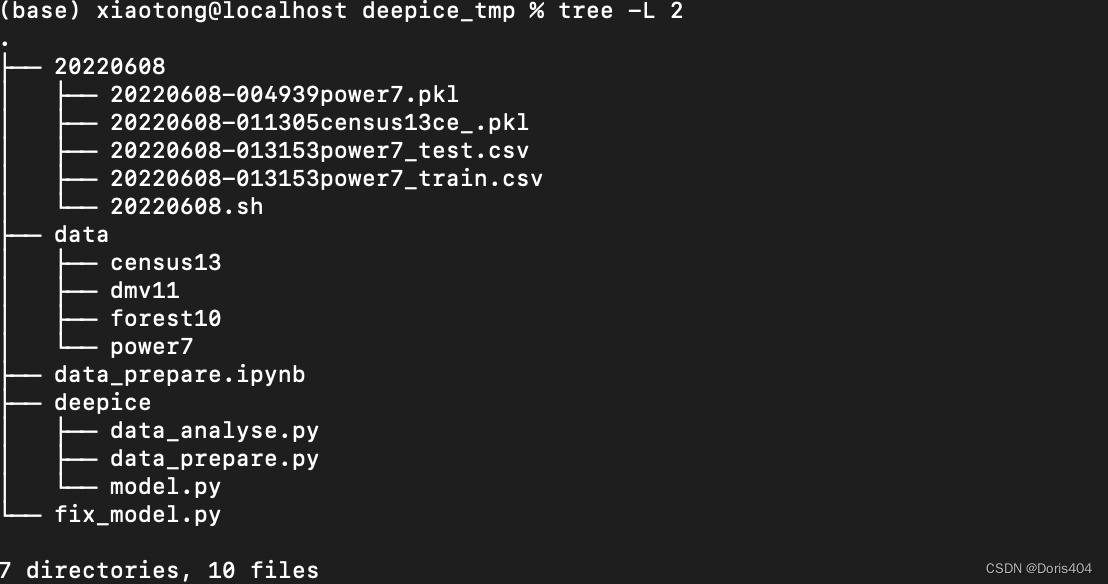
举例:基数估计常用的4个数据是census13, power7, forest10和dmv11,在这种情况下,data文件夹下的结构是:
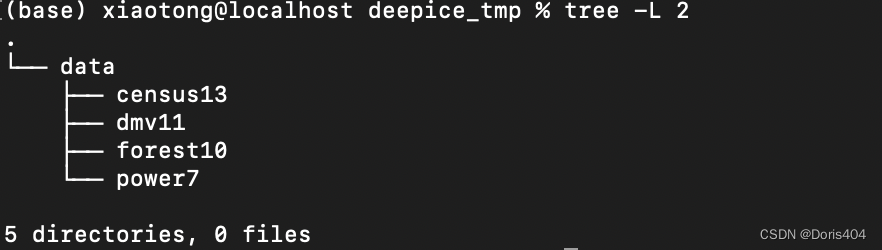
接下来,下载的原始数据(通常是csv格式,当然也存在其他格式)放在各自名称命名的文件夹中。项目最开始,data文件夹下的每个数据文件夹只有一个原始的文件,后续进行数据处理将扩充数据文件夹的内容。原始文件建议命名为original.csv,便于后续进行做实验。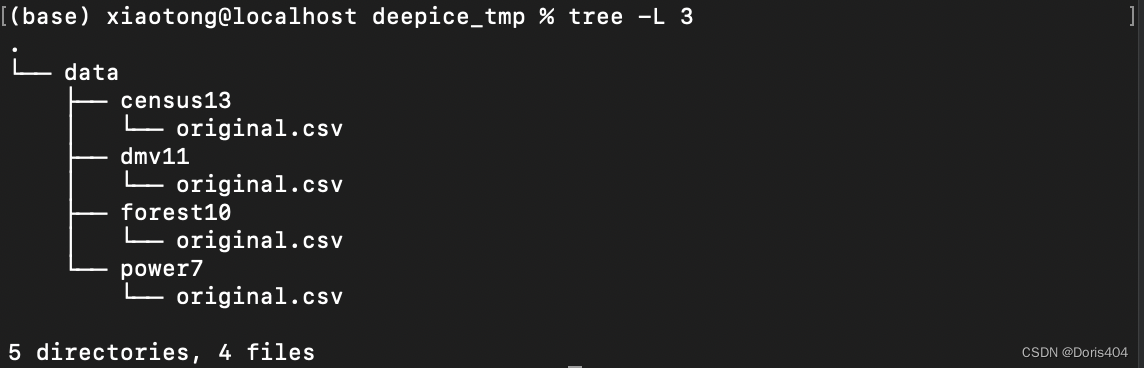
这种安排文件夹结构的方法,可以简化后续代码的工作量,同时也能恰到好处的区分每个数据究竟属于的是census13, 还是power7。实验往往要在多份数据上进行重复,这个时候只需要改变代码中的文件路径中的一个部分即可。
上面就是基本的数据文件夹的结构安排,为了后续方便介绍,现进行以下区分
- data文件夹:命名为data的文件夹,其下有多个子数据文件夹用于重复多次实验。
- 子数据文件夹:以数据的名称命名,其下最开始只有一个原始文件,后续会进行扩充。
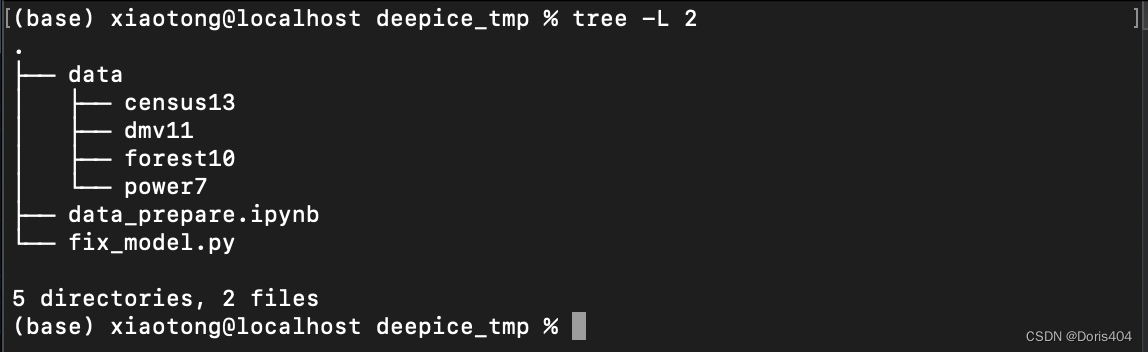
对data文件夹进行扩充
有时候(大部分时候)并不能直接用original.csv进行训练,需要对original.csv进行一些处理,比如在基数估计领域,我们用到的直接训练数据并不是original.csv,而是workload,label以及original.csv经过data-driven的基数估计模型得到的中间表示。我们需要根据original.csv进行数据处理,得到这些直接使用的数据,并存储成合适格式。
举例:在deepice项目中,我使用的训练数据分2种,一种是只有query的,一种是query+data的。那么我就会生成两大类数据:train_q.csv和train_qd.csv。这里下划线之后的代表具体哪类训练数据。这一步最终生成的文件包括:
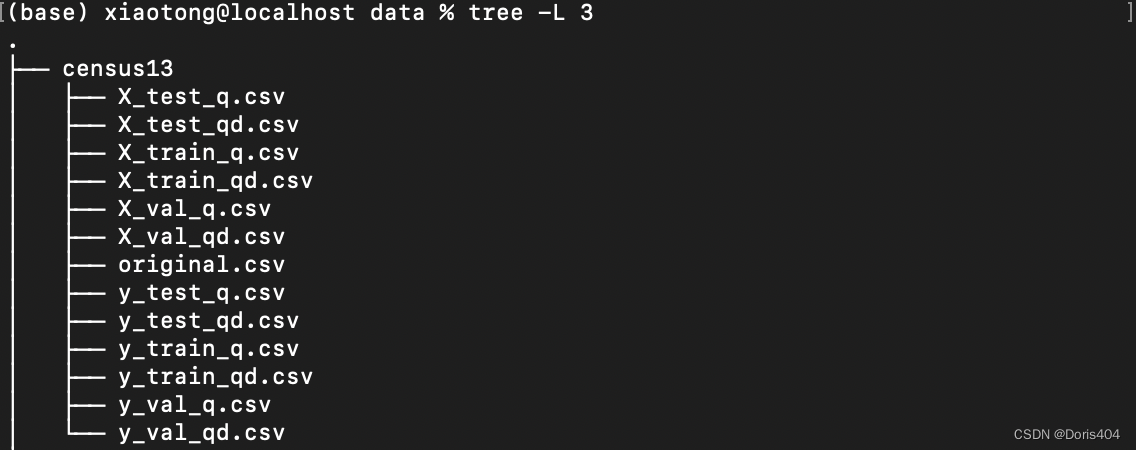
至此,data文件夹的创建结束。
数据处理模块
前面提到的数据模块经过数据处理模块得到扩充,这部分建议使用jupyter notebook进行操作,可以实时看到操作后的结果。同时可以使用markdown划分代码结果,标注出来每一个模块具体是做什么操作,从而让数据处理更加明了。
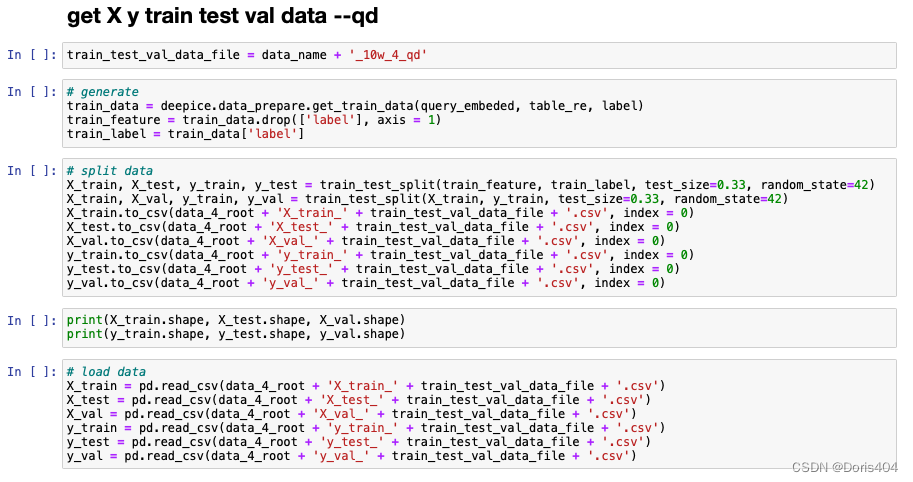
举例:在deepice项目中涉及的数据操作包括,去除非法值,合并操作,取和操作等。无论做了什么,最后结果一定要记得存下来。(ps:存储数据并不一定总能成功,当数据量超大时,很有可能存不下来)
这一步骤中定义的新函数可以加入自定义包中,后续每一步骤中经常使用的代码都可以加入到包中。包的实现将在自定义模块中具体介绍。
模型搭建模块
常用的模型搭建框架是tensorflow和pytorch,二者均可以使用,具体模型搭建方法可以查看之前的博客,这里不赘述。
代码写作套路【1】使用tensorflow构建模型的2种方法
代码写作套路【3】使用pytorch构建模型的2种方法
这里主要是想从实践层面来介绍模型搭建时所需要注意的具体细节。
- 模型搭建出来不一定(大概率不会)取得很好结果:这时需要首先查看损失函数的值,如果损失函数为nan,查看预测结果是否为nan,如果预测结果为nan,说明数据中有inf值或其他非法值,对数据进行进一步处理。如果预测结果不为nan,查看模型参数具体取值,可以通过初始化模型参数调整最开始的损失函数。若进行调整无果,可以尝试改变损失函数。对原来的损失函数取个对数,减小损失函数等。
- 损失函数不下降:问题可能在于优化器和模型结构,建议先调整优化器,后调整模型结构。
- 损失函数下降但没有降到我预期那么小:训练时常可能不够,这时可以对这个模型继续进行训练,训练足够长时间直至损失函数不再下降。
模型训练模块&实验结果导出模块
模型训练的代码写法有2大类,一类是先建个模型,然后训练,最终存储模型;另一类是先加载一个已经训练过的模型,然后基于这个模型继续进行训练。(这应对模型搭建模块中处理损失函数不够小的情况进行的调整)。
值得注意的是无论怎样,训练的模型都必须及时存下来
,否则训练就是白训。为了实时查看模型训练的结果,你可以每训练一些epoch就将模型存储下来。存下来的模型文件的命名可以参考时间戳+对应数据的格式。这些模型文档可以直接存储在以当日日期为命名的文件夹下,这样方便第二日直接将这日获得的新数据进行备份。
举例:20220608-004939power7.pkl代表20220608-004939时刻开始在power7上进行训练的模型。
举例:20220608-011305census13ce_.pkl代表20220608-011305时刻在census13上训练的ce模型。
def exe_model(epochs, X_train, X_test, X_val, y_train, y_test, y_val, train_size, test_size, val_size,
model, optimizer, loss_func,
id_, timestamp, model_save_file,
must_cpu):
# determine device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if must_cpu == 1:
device = 'cpu'
model = model.to(device)
loss_func = loss_func.to(device)
X_train = X_train.to(device)
y_train = y_train.to(device)
X_test = X_test.to(device)
y_test = y_test.to(device)
X_val = X_val.to(device)
y_val = y_val.to(device)
for t in range(epochs):
y_pre_train = model(X_train)
train_loss = loss_func(y_pre_train,y_train)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
y_val_pre = model(X_val)
val_loss = loss_func(y_val_pre, y_val)
if t % 5000 == 0:
print(str(t), datetime.datetime.now().strftime("%Y%m%d-%H%M%S"), '>>>train loss', torch.log(train_loss), '>>>val loss', torch.log(val_loss))
torch.save(model, model_save_file +'.pkl') # save model
# get result_train
y_pre = model(X_train)
y_pre = y_pre.cpu()
y_train = y_train.cpu()
result_train = pd.DataFrame({
'y_pre_train': y_pre.detach().numpy().reshape(train_size),
'y_train': np.array(y_train).reshape(train_size),
})
result_train['q_err'] = get_q_err(result_train['y_train'], result_train['y_pre_train'])
result_train.to_csv(model_save_file + '_train.csv', index = 0)
# get result_test
y_pre = model(X_test)
y_pre = y_pre.cpu()
y_test = y_test.cpu()
result_test = pd.DataFrame({
'y_pre_test': y_pre.detach().numpy().reshape(test_size),
'y_test': np.array(y_test).reshape(test_size),
})
result_test['q_err'] = get_q_err(result_test['y_test'], result_test['y_pre_test'])
result_test.to_csv(model_save_file + '_test.csv', index = 0)
print('train set mean q_err', result_train['q_err'].mean())
print('test set mean q_err', result_test['q_err'].mean())
print(id_)
print(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
在代码运行结束时,可以将预测结果存成csv文件。
这部分代码参数的导入可以参考我过去的博客
日志模块
日志模块指每日实验结果放在同一个以日期为命名的文件中方便管理与备份,同时也意味着每日运行的bash语句要汇总到一个文件中存入上述文件夹中。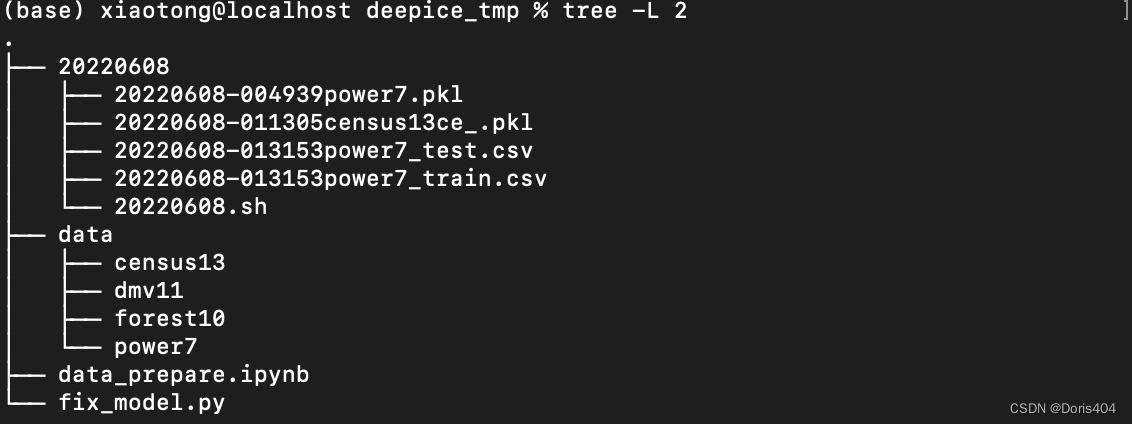
每日进行完实验可以于第二天将前一日的文件夹下载到本地进行备份。每日做实验的第一步也是创建以当日日期文明的文件夹用于存储每日的实验结果。
自定义模块
有一些自定义函数的使用频率极高,且经常跨文件使用,自定义包可以极大地提升代码书写的效率。但由于代码书写总是会有bug,一般写自定义包的步骤是,现在单个代码文件中进行测试,测试无误后,将这个代码放入自定义包中。自定义包可以与项目名称一样。
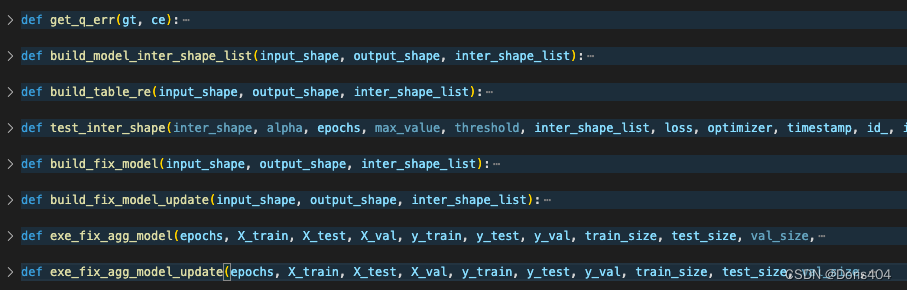
举例:deepice项目将自定义包按照功能划分成data_prepare.py, data_analyse.py和model.py。
后记
这部分主要记录做实验过程中遇到的新的问题以及其解决方案,后续会进行不定期更新。这部分内容比较冗杂,将按照Q&A的格式进行展开。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









