







❤️ 单链表实现
文章目录
💘1、链表介绍
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
即在物理上不一定连续,逻辑上连续就是链表的特点之一
💙 2、链表的分类
- 单向或者双向
单向链表即上一个节点存储下一个节点的地址,但是无法通过下一个节点找到上一个节点
双向链表中同时会存储上一个节点和下一个节点的地址,可以通过此节点找到前后的节点
- 带头或者不带头
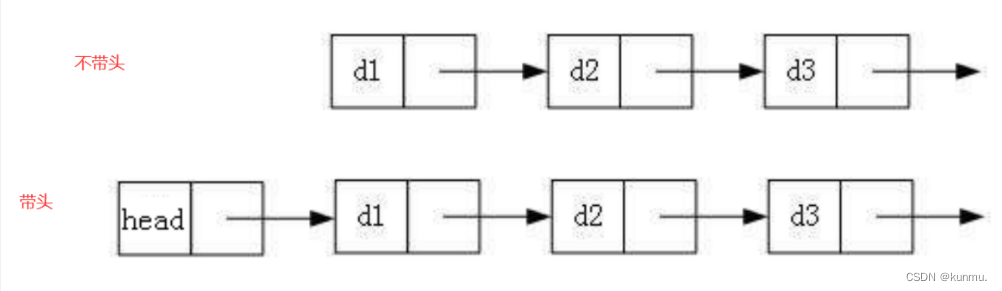
头节点中的data本身不存储任何数据,也不表示任何意义。带头节点的链表可以避免链表在增删查改过程中的换头问题,有自己独特的好处!
- 循环或者非循环
循环链表中最后一个节点中存储的地址指向第一个节点
非循环链表中最后一个节点中存储的地址为NULL
- 常用结构
无头单向非循环链表
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KMjTuNLS-1664708966401)(C:\Users\25584\AppData\Roaming\Typora\typora-user-images\image-20221001192331211.png)]](https://img-blog.csdnimg.cn/c59cdeddcd0d4c0a85e683c145ca11b6.png)
带头双向循环链表
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-73rIDq6J-1664708966403)(C:\Users\25584\AppData\Roaming\Typora\typora-user-images\image-20221001192346732.png)]](https://img-blog.csdnimg.cn/b9de429bfac6477ba61830822835ab9c.png)
本次主要讲无头单向非循环链表(单链表)的实现!
💜 3、单链表源码查看
- 单链表实现源文件查看移步到Gitee ------------> 单链表源文件
- 单链表实现头文件查看移步到Gitee ------------> 单链表头文件
- 单链表实现主文件查看移步到Gitee ------------> 单链表主文件
💟 4、相关接口
//打印函数 void SLPrint(SL* phead); //头插函数 void SLPushFront(SL** pphead, SLDataType x); //增加节点函数 SL* SLAddNewNode(SLDataType x); //尾插函数 void SLPushBack(SL** pphead, SLDataType x); //头删函数 void SLPopFront(SL** pphead); //尾删函数 void SLPopBack(SL** pphead); //查找函数 SL* SLFind(SL* phead, SLDataType x); //销毁函数 void SLDestory(SL** pphead); //在pos之前插入函数 void SLInsert(SL** pphead, SL* pos, SLDataType x); //在pos之后插入函数 void SLInsertAfter(SL* pos, SLDataType x); //删除pos位置函数 void SLErase(SL** pphead, SL* pos); //删除pos后面的位置函数 void SLEraseAfter(SL* phead, SL* pos);
💛 5、单链表书写心得(注意事项)
🚗 1、注意事项
- 单链表不需要初始化
typedef int SListDataType;
typedef struct SingleList
{
struct SingleList* next;
SListDataType data;
}SL;
//创建空链表
SL* slist = NULL;
因为链表的物理结构是一种非连续的,所以每一个节点的创建都需要去malloc,当链表为空时,其实就不存在节点。因此对于链表无需进行初始化,空链表就为NULL。
- 删除节点时,应及时释放该节点的空间
同样的道理,链表的每一个节点都是一块由malloc开辟出来的独立空间,当我们进行删除数据时,也就是相当于删除该节点,所以应该要及时对齐释放,避免造成内存泄漏。
- 单链表适合头插和头删,但并不适合尾插尾删,时间复杂度为O(N)
因为单链表的物理结构是非连续的,所以进行尾插尾删时,必须先得通过循环找到尾节点。
同时单链表中的节点并没有存储前一个节点的地址,因此单链表也不适合中间插入中间删除等操作
- 单链表各个接口函数实现过程中,应当注意传一级指针和二级指针问题
//头删函数
void SLPopFront(SL** pphead);
//当链表中的节点为1个时,进行头删后,需要更换头节点,那么就需要对链表做更改,这时候就要传二级指针
//查找函数
SL* SLFind(SL* phead, SLDataType x);
//查找相应的值无需对链表做出更改,只需要传一级指针
- 注意代码的健壮性,对各个函数可能出现的异常情况分析处理
异常情况:
-
malloc申请内存空间失败
-
头删尾删时链表为空
-
查找时未查找到相关数据
-
在pos节点前后插入删除时该节点不在链表内
🚓 2、重点接口理解
增加节点函数
//因为只要是插入就得增加节点,所以将其写成函数,提高函数的高内聚、低耦合
SL* SLAddNewNode(SLDataType x)
{
SL* newnode = (SL*)malloc(sizeof(SL));
if (newnode == NULL) //对申请失败进行判断
{
perror("malloc fail");
exit(-1);
}
else
{
newnode->next = NULL; //对于新申请的节点,next直接初始化为NULL,再传回newnode至调用函数进行插入
newnode->data = x;
}
return newnode;
}
尾插函数
void SLPushBack(SL** pphead, SLDataType x)
{
assert(pphead);
SL* newnode = SLAddNewNode(x); //接收新增加的节点
if (*pphead == NULL) //判断单链表是否为空。当单链表为空时,则需要更换头节点
{
*pphead = newnode;
}
else
{
SL* prev = *pphead;
while (prev->next != NULL) //若单链表不为空,尾插时则需要找到尾节点后再进行插入
{
prev = prev->next;
}
prev->next = newnode;
}
}
在pos前插入函数
void SLInsert(SL** pphead, SL* pos, SLDataType x)
{
assert(pphead);
assert(pos); //排除pos为NULL的情况
SL* newnode = SLAddNewNode(x); //增加一个新节点
//考虑链表中只有一个节点的情况,需要更换头节点
if (*pphead == pos)
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
SL* prev = *pphead; // prev代表pos位置前的节点
while (prev->next != pos)
{
prev = prev->next;
assert(prev); //如果prev为NULL时还找不到,就报一个警告!
}
newnode->next = prev->next;
prev->next = newnode;
}
}
PS:其他的接口函数可以到Gitee查看
💚 6、单链表的优点和缺陷
无头单向非循环链表对于头插和头删操作来说是十分方便的,同时单链表实现了对内存空间的合理运用,不会浪费空间。
但单链表对于尾插尾删操作时间复杂度为O(N),主要是因为得先找到尾节点。
对于这个缺点,可以通过后面所学的双向循环链表解决!
💝 7、单链表相关OJ题
1、给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点
//*********************************************************
//思路:设置两个结构体指针,让两个指针走
//使用循环写,循环条件为cur是否为空
//首先应该判断cur->val是否和val相等
//否:让cur和prev往后走
//是:再判断是不是头指针,因为是头指针就存在换头问题,需要再写一个判断条件进行判断
//********************************************************
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* cur = head; //将其赋值为head
struct ListNode* prev = NULL;
while(cur)
{
if(cur->val == val) //首先先判断是否相等
{
//再判断是不是头删
if(head == cur)
{
head = head->next;
free(cur);
cur = head;
}
else
{
prev->next = cur->next;
free(cur);
cur = prev->next;
}
}
else
{
prev = cur;
cur = cur->next;
}
}
return head;
}
2、链表的合并:将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
//*******************************************************************************
//思路:
//设置两个指针指向两个链表
//同时创建一个带哨兵头的新链表(如果不带哨兵头,就得进行判断刚开始的链表是不是为空)
//然后让将val较小的移到新链表
//*******************************************************************************
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
struct ListNode* cur1 = list1;
struct ListNode* cur2 = list2;
struct ListNode* guard = (struct ListNode*)malloc(sizeof(struct ListNode));
guard->next = NULL; //为了防止当list1和list2都为空时,返回错误的指针
struct ListNode* tail = guard;
while(cur1 && cur2)
{
if(cur1->val <cur2->val)
{
tail->next = cur1;
cur1 = cur1->next;
}
else
{
tail->next = cur2;
cur2 = cur2->next;
}
tail = tail->next;
}
if(cur1)//因为必有一个链表先走完,所以得进行判断,同时将未走完的链表赋给新链表
{
tail->next = cur1;
}
if(cur2)
{
tail->next = cur2;
}
struct ListNode* head = guard->next;
free(guard); //将申请的空间释放
return head;
}
3、 给定一个头结点为 head 的非空单链表,返回链表的中间结点。 如果有两个中间结点,则返回第二个中间结点。
//思路:快慢指针
//慢指针一次走一步,快指针一次走两步,最后返回慢指针。
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* fast = head, *slow = head;
while(fast && fast->next)
//这里必须将fast写在前面,&&是按顺序执行,前面的为NULL后,就不会执行后面的。这样就避免了错误访问
{
fast = fast->next->next;
slow = slow->next;
}
}
return slow;
}
🖤 总结
单链表相比较与顺序表有优势也有缺陷,它并不是完美的。之所以要学习单链表,主要是因为有些OJ题是以单链表为结构的,同时单链表可以作为其他数据结构的子结构,如哈希表。
期待下一次的双向链表!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











