







KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是实现一个next()函数,函数本身包含了模式串的局部匹配信息。时间复杂度O(m+n)。
关于字符串匹配算法基本用这些算法解决问题:
- 字典树:只查询某个串在字典中是否匹配。
- KMP:在主串中线性遍历查询匹配单个模式串
- AC自动机:在一个主串中线性遍历查询匹配多个子串。
- 后缀数组:不可/可重叠最长重复子串查询。
当遇到以下问题时可以用KMP算法解决:
主 串 :a b a c a a b a c a b a c a b
模式串:a b a c a b
找出主串中有多少个子串与模式串相同?
若是尝试最朴素的暴力匹配方式,我们可能会使用N^2的时间复杂度解决该类问题

可以看到,在暴力匹配的过程中我们做了很多的无用功,当第一轮匹配前六个字符出现失配时,我们就该知道前六个字符不会出现正确的匹配结果了,并且已经遍历过一次的字符串重复遍历判断多次就会感觉这种方法非常愚蠢。
优雅的做法是,我们应该尽量利用失配信息,用上一次遍历时获取的信息。使得我们的遍历不会再做无用功,进行重复多次的遍历。
于是我们尝试用以下性质来优化:
假设主串为’s[1],s[2]…s[n]’,模式串为’p[1],p[2]…p[m]’。当匹配过程中产生 “失配”(即s[i]≠p[j]) 时,模式串“向右滑动”可行的距离多远。换句话说,当主串中第i个字符与模式中第j个字符“失配”(即比较不等)时,主串中第i个字符(i指针不回溯)应与模式中哪个字符再比较?
假设此时应与模式中第k(k<j)个字符继续比较,则模式中前k-1个字符的子串必须满足下列关系式①且不可能存在k’< k满足下列关系式①。
① ‘p[1]p[2]…p[k-1]’=‘s[i-k+1]s[i-k+2]…s[i-1]’
而已经得到的“部分匹配”的结果是
② ‘p[j-k+1]p[j-k+2]…p[j-1]’=‘s[i-k+1]s[i-k+2]…s[i-1]’
由式①和式②推得下列等式
③ ‘p[1]p[2]…p[k-1]’= ‘p[j-k+1]p[j-k+2]…p[j-1]’
反之,若模式串中存在满足式③的两个子串,则当匹配过程中,主串中第i个字符与模式中第j个字符比较不等时,仅需将模式向右滑动至模式中第k个字符和主串中第i个字符对齐,此时,模式中头k-1个字符的子串‘ p[1]p[2]…p[k-1]’必定与主串中第i个字符之前长度为k-1的子串‘ s[i-k+1]s[i-k+2]…s[i-1]’相等,由此,匹配仅需从模式中第k个字符与主串中第i个字符比较起继续进行。
上面过程叙述了我们应该如何利用好遍历过一次的字符串的失配信息优化匹配过程。
以上文字来源于 严蔚敏版《数据结构》 虽然其看起来比较晦涩,但是以文字的形式确实将KMP所依靠的精髓原理说明清楚了。这也是我第一次看到用文字叙述来严谨的说明 KMP算法利用模式串前缀后缀重复的性质 来优化匹配的详细过程。
如果没有弄明白上面叙述的过程,这很正常,我们可以通过画图来叙述一边。
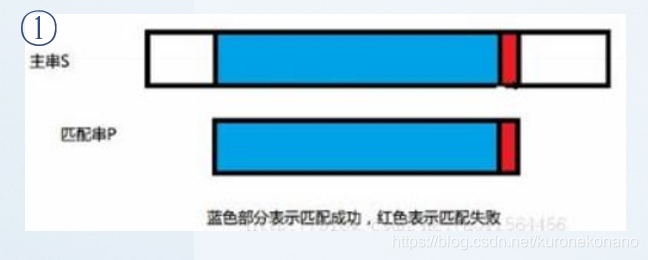
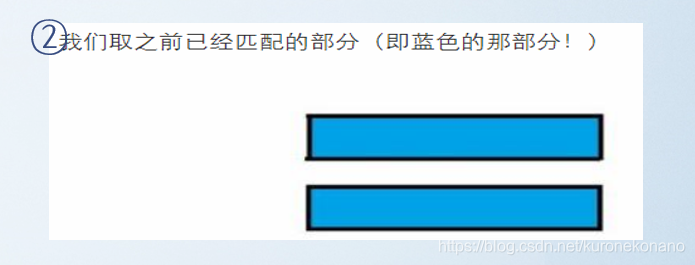
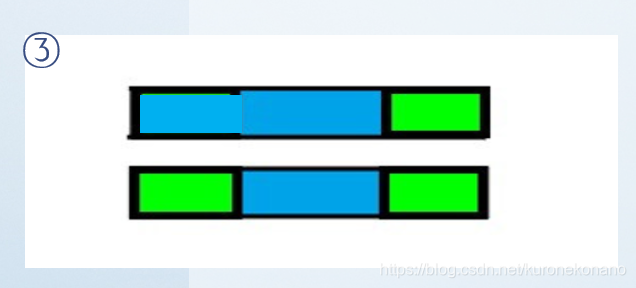
以上是我们在一次普通匹配过程中遇到的失配情况。其中下方模式串的左边绿色部分也是上面文字叙述中的关系式①:
① ‘p[1]p[2]…p[k-1]’=‘s[i-k+1]s[i-k+2]…s[i-1]’
而下方模式串P的右边绿色部分则是关系式②
② ‘p[j-k+1]p[j-k+2]…p[j-1]’=‘s[i-k+1]s[i-k+2]…s[i-1]’

由此我们可以得到,式①和式②中的等号右边是一样的即主串中的绿色部分,最后得到结论,我们需要的信息是,模式串中两段绿色部分相等,当我们知道模式串匹配过程中失配部分之前一段子串是与模式串开头一段子串是完全相等的,那么我们就可以继续从主串失配位置往后匹配,而不用回退主串的匹配指针,因为我们可以将模式串的匹配指针向前移动,并认为该指针之前的字符是完全匹配正确的。
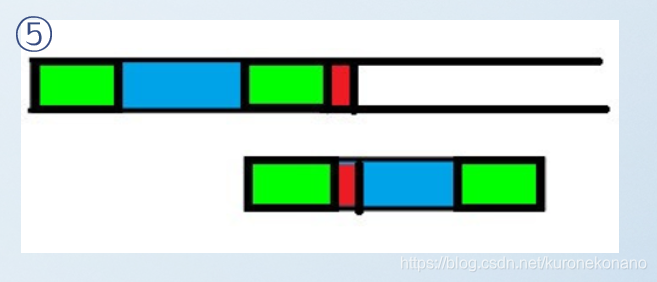
这样就不会出现朴素暴力匹配时无脑回退主串和模式串指针的行为,而是跳跃着匹配,保证这样匹配过程正确的依据即是利用了失配信息,前缀后缀重复的特性。保证了某段子串是一定匹配的。
明确了优化原理,那么我们就该探究如何预处理出模式串的前缀后缀重复信息,并使其能在匹配时被利用上。
以下介绍Next数组 的构造:
Next数组:
next[i](i从1开始算)代表着,除去第i个数,在一个字符串里面从第一个数到第(i-1)字符串前缀与后缀最长重复的个数。
构造next数组使用的基本方法是递推,要计算当前第i位字符的next值即计算从字符串开始至第i位前(不包括第i位)的字符串的最长前缀与后缀重复数量。
规定第0位(第一个字符)的next值是0或-1(有不同构造next函数的方法)。
第i+1位的next值分两种情况讨论:
①当p[i]=p[j]时,前缀和后缀相等,最大长度可以延续因此next[++i]=next[++j]
②当p[i]≠p[j]时,前缀和后缀匹配到此不等,那么可以利用已计算好的next值,将j回溯,直至找到可匹配的重复前缀后缀。也就是j=next[j]
代码实现如下所示:
void getNext(char *T , int len)
{
int i = 0;
int j =next[0] = -1;
while(i < len)
if(j == -1 || T[i] == T[j])
next[++i] = ++j;
else
j = next[j];
}
由上面代码我们即可处理出next数组来表示模式串中第i位于前缀重复的长度
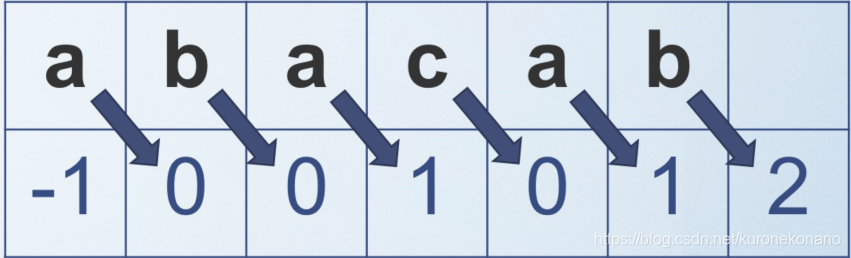
以abacab举例,我们将构造出如上数组,可以注意到,数字所代表的每一位是其前一位字符的最长前缀后缀匹配。为什么会错位呢?
可以看出,当第4位字符是a时,其最长前缀后缀匹配长度是1,而这个1在第5位,这样表示的意义时,当第5位字符b出现失配时,我们已经知道了b字符之前的a是与模式串第一位字符a是匹配的,因此无需再匹配a,而是需要匹配a的下一位字符,也就是下标是1的字符b,这就造成了结果与字符错位的现象,实际上只是为了方便失配时快速找到应该继续匹配的位置。
PS:next数组的值仅取决于模式串本身,而与匹配的主串无关
我们用该next数组模拟一下匹配过程:
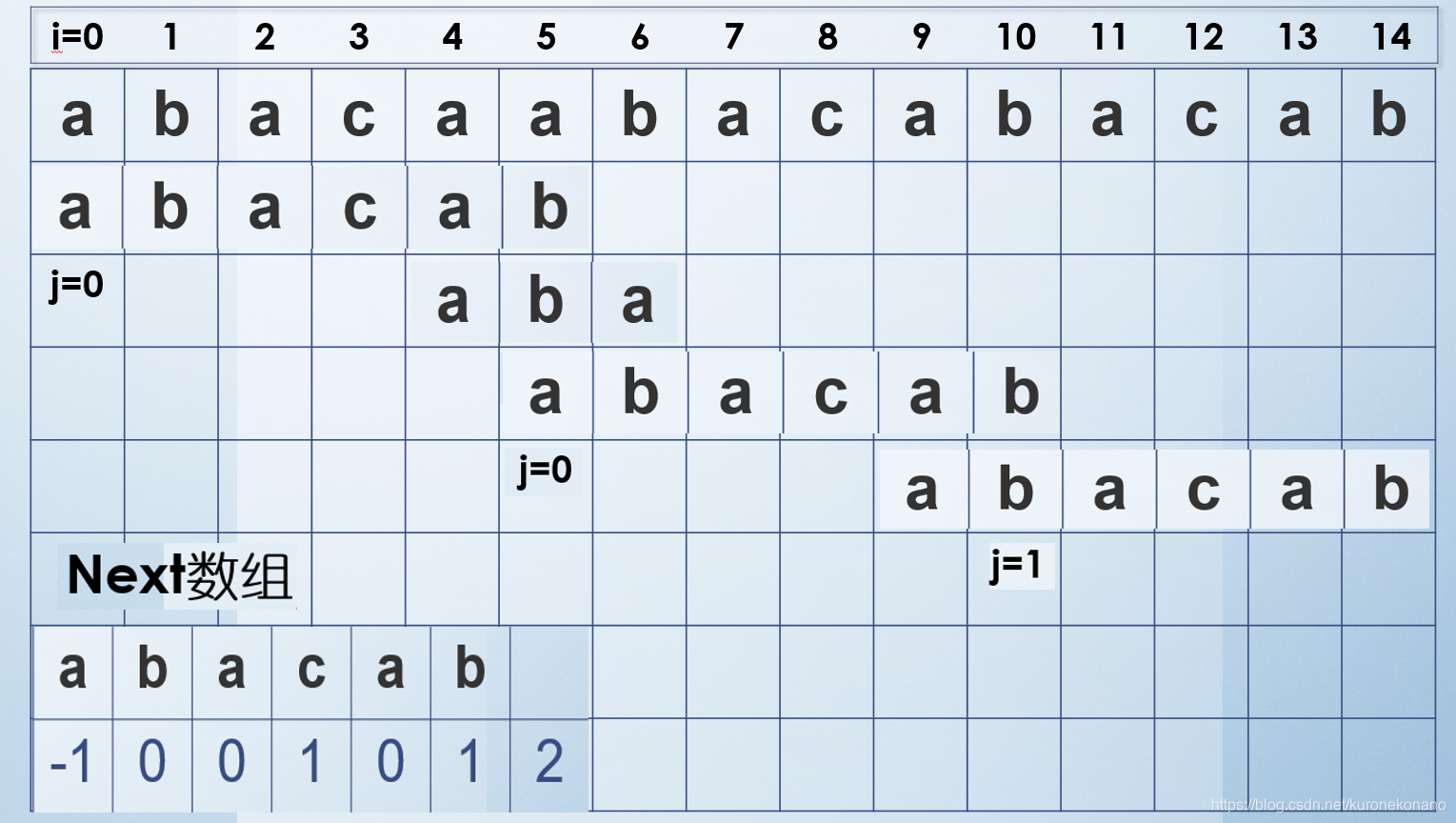
可以发现,在失配时,不再像原来那样无脑直接从头匹配,而是在明确哪些可能有匹配价值的情况下跳跃指针的匹配,并且主串指针从未回退,一直是模式串在回退。
以下是KMP朴素模板:
#include <iostream>
#include<stdio.h>
#include <cstring>
using namespace std;
const int N = 1000002;
int next[N];
char S[N], T[N];
int slen, tlen;
void getNext()
{
int j, k;
j = 0;
k = -1;
next[0] = -1;
while(j < tlen)
{
if(k == -1 || T[j] == T[k])
{
next[++j] = ++k;
}
else
{
k = next[k];
}
}
for(int i=0;i<=tlen;i++)printf("%d%c",next[i],i==tlen?'\n':' ');
}
/*
返回模式串T在主串S中首次出现的位置
返回的位置是从0开始的。
*/
int KMP_Index()
{
int i = 0, j = 0;
getNext();
while(i < slen && j < tlen)
{
if(j == -1 || S[i] == T[j])
{
i++;
j++;
}
else
{
j = next[j];
}
}
if(j == tlen)
{
return i - tlen;
}
else
{
return -1;
}
}
/*
返回模式串在主串S中出现的次数
*/
int KMP_Count()
{
int ans = 0;
int i, j = 0;
if(slen == 1 && tlen == 1)
{
if(S[0] == T[0])
return 1;
else
return 0;
}
getNext();
for(i = 0; i < slen; i++)
{
while(j > 0 && S[i] != T[j])
j = next[j];
if(S[i] == T[j])
j++;
if(j == tlen)
{
ans++;
j = next[j];
}
}
return ans;
}
int main()
{
int TT;
int i, cc;
cin>>TT;
while(TT--)
{
cin>>S>>T;
slen = strlen(S);
tlen = strlen(T);
cout<<"模式串T在主串S中首次出现的位置是: "<<KMP_Index()<<endl;
cout<<"模式串T在主串S中出现的次数为: "<<KMP_Count()<<endl;
for(int i=0; i<=tlen; i++)
cout<<next[i]<<" ";
cout<<endl;
}
return 0;
}
其实KMP本质用的是模式串的前缀后缀匹配特性,Next数组还有其他应用,并且在仅仅是加速匹配上next数组仍有优化的空间,具体请看:KMP优化
关于优化KMP
朴素的KMP按照这个操作写会超时,原因在与可能后台数据有大量的类似于aaaaaaaa的相同字符长串,此处我们用到KMP优化。
可以知道,朴素的KMP中NEXT数组构造,其意义在匹配过程中表示了,如果子串在该位置失配,那么子串匹配指针j应该回溯到的位置。这样就保证了只回溯子串指针,而主串指针一直是增加的。
引用网上的图表即朴素KMP对于模式串aaac的NEXT数组构造如下:

我们发现,这个看似优秀的,能够直接将子串指针飞跃回最大前缀的NEXT数组,实际上在连续相同字母中效果不佳,如果有连续1e5个字符’a’,那么根据NEXT的回溯,当匹配主串到aaaaaaa…aaaaab时【假设中间省略1e4个a】,这一个突如其来的b,将使子串根据NEXT数组以龟速,一个一个回溯迭代O(n)的速度,回退到第0位。我们明知道子串第i个字符和第i+1个字符已经相等了,那么如果在第i+1位不匹配,第i位也不可能匹配的,因此为什么还要回退到i,直接回退到next【i】才是飞速跳跃式的回退。
如上,这个不匹配字符b要判断多次才能回到最初位置。
多次冗余比较导致了KMP的低效。

对于一个朴素KMP中构造NEXT数组的模板,我们考虑做一些改动,**就像并查集中的路径压缩一样。**路径压缩考虑将一个节点的父亲直接牵引至其父亲的父亲,这样避免了多次迭代查找父亲。
我们考虑相邻相同字符的next值,应该是一样的,那么第i位为next【i】,若第i+1位字符等于第i位字符,则next【i+1】=next【i】
对比朴素模板和优化模板:
void kmp_pre(char x[],int m,int next[])
{
int i,j;
j=next[0]=-1;
i=0;
while(i<m)
{
while(j!=-1&&x[i]!=x[j])j=next[j];
next[++i]=++j;///朴素KMP
}
}
优化后:
void kmp_pre(char x[],int m,int next[])
{
int i,j;
j=next[0]=-1;
i=0;
while(i<m)
{
while(j!=-1&&x[i]!=x[j])j=next[j];
++i,++j;
next[i]= x[i]==x[j]?next[j]:j;///优化KMP
}
}
值得注意的是,这个优化已经改变了next数组的本质,即最大前缀后缀匹配,也就是说,我们只是为了查询得更快而进行数据存储方式的优化,对于一些利用next本质的题目,这样的优化可能会出现意想不到的错误,甚至反而会超时。如 POJ2752 ,因此优化KMP不能完全替代朴素KMP。














 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









