







Scrapy入门
首先给出官方中文文档链接——官方文档。遇到什么不懂得,看官方文档是最好的解决办法。
文章基于Windows10操作系统,使用Anaconda——Python3.7,IDE——Pycharm community 2018.3.2 ,Scrapy版本1.5.2
参考书籍:精通Scrapy网络爬虫 刘硕
直接使用Anaconda Prompt中shell指令conda install scrapy即可安装scrapy库
Scrapy简单介绍
Scrapy 使用了 Twisted 异步网络库来处理网络通讯。整体架构大致如下
其中绿色为数据流。图片来源于互联网
对于用户来说Spider是最核心得组件,Scrapy得开发是围绕着Spider展开的。
Scrapy运行流程大概如下:
- 当Spider要爬取某Url页面时,需要构造一个Request对象,并提交给Engine。
- Request对象进入Scheduler后按照某种算法进行排队,并在某个时刻送往Downloader。
- Downloader根据Request中得Url发送Http请求到网站服务器,并根据网站的Http响应构造一个Response对象,其中包含网站的Html文本
- Response对象最终被送给Spider的液面解析函数进行处理,并封装成Item后交给Engine之后送往Item Pipelines,最终可能由Exporter以某种数据格式写入文件,另一方面,页面解析函数可以从Html页面中构造出新的Request对象交给Engine。
Spider开发流程
对于Scrapy框架,需要用户实现的最重要的就是Spider子类,实现一个Spider子类需要用户完成以下几个问题
- 爬虫从哪个页面开始爬取
- 对于一个已经下载到本地的页面,需要提取哪些信息
- 当本页面信息提取完毕,接下来爬取哪些页面
解决了以上几个问题,爬虫也就实现的差不多了。下面开始简单介绍一下Scrapy库的使用。
Scrapy库的使用
Scrapy的使用离不开shell,除了完善Spider,items,setting,pipelines子类需要在Pycharm里编写代码,其他的都需要使用Anaconda Prompt
Scrapy简单介绍
在shell里输入scrapy会出现下图所示界面
 记住几个常用的就行,其他的需要用的时候在查
记住几个常用的就行,其他的需要用的时候在查
scrapy crawl <爬虫名称>运行一个编写好的爬虫。scrapy genspider <爬虫名称> <爬虫起始Url>生成一个Scrapy模板。scrapy shell <Url>在一个交互命令行下操作一个Scrapy爬虫,一般可以使用shell来做前期测试,如果可以正常爬取,再去编写Scrapy。scrapy startproject <Name>创建一个Scrapy项目Scrapy version显示Scrapy库的版本Scrapy view <Url>使用浏览器打开Url(此时的页面为下载到本地的页面,而不是http请求的页面)
简单小示例
下面编写一个简单的Scrapy爬虫爬取http://books.toscrape.com/中每一本书的信息,并保存到csv文件中。
首先需要对页面进行分析,在此我们就不分析了,默认读者有相关前端知识,直接去做。
创建一个Scrapy项目
scrapy startproject example
生成模板
cd example // 进入文件夹
scrapy genspider books books.toscrape.com
定义封装书籍信息的Item类
打开Pycharm,在example/items.py中输入
class bookItem(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
review_rating = scrapy.Field()
review_num = scrapy.Field()
upc = scrapy.Field()
stock = scrapy.Field()
pass
实现Spider解析函数
在example/spider/books.py中实现
- 书籍列表页面解析函数parse()
- 书籍页面解析函数parse_book()
#coding = utf-8
import scrapy
from scrapy.linkextractors import LinkExtractor
from ..items import bookItem
class bookSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
le = LinkExtractor(restrict_css = 'article.product_pod h3')
for link in le.extract_links(response):
yield scrapy.Request(link.url, callback= self.parse_book)
le = LinkExtractor(restrict_css = 'ul.pager li.next')
links = le.extract_links(response)
if links:
next_url = links[0].url
yield scrapy.Request(next_url, callback = self.parse)
def parse_book(self, response):
book = bookItem()
sel = response.css('div.product_main')
book['name'] = sel.xpath('./h1/text()').extract_first()
book['price'] = sel.css('p.price_color::text').extract_first()
book['review_rating'] = sel.css('p.star-rating::attr(class)').re_first('star-rating ([A-Za-z]+)')
sel = response.css('table.table.table-striped')
book['upc'] = sel.xpath('(.//tr)[1]/td/text()').extract_first()
book['stock'] = sel.xpath('(.//tr)[last()-1]/td/text()').re_first('\((\d+) available\)')
book['review_num'] = sel.xpath('(.//tr)[last()]/td/text()').extract_first()
yield book
设置管道
在pipelines.py中实现bookPipeline()类,用以实现映射功能(仅针对本例中将one,two…映射为1,2,…方便阅读)
class bookPipeline(object):
review_rating_map={
'One': 1,
'Two': 2,
'Three': 3,
'Four': 4,
'Five': 5,
}
def process_item(self, item, spider):
rating = item.get('review_rating')
if rating:
item['review_rating'] = self.review_rating_map[rating]
return item
配置文件
在setting.py中进行最后配置
先启用管道
ITEM_PIPELINES = {
'example.pipelines.bookPipeline': 300,
}
再设置数据输出顺序
FEED_EXPORT_FIELDS=['upc','name','price','stock','review_rating','review_num']
运行爬虫
在shell中运行爬虫
scrapy crawl books -o books.csv
之后就可以看到自己所爬到的数据啦
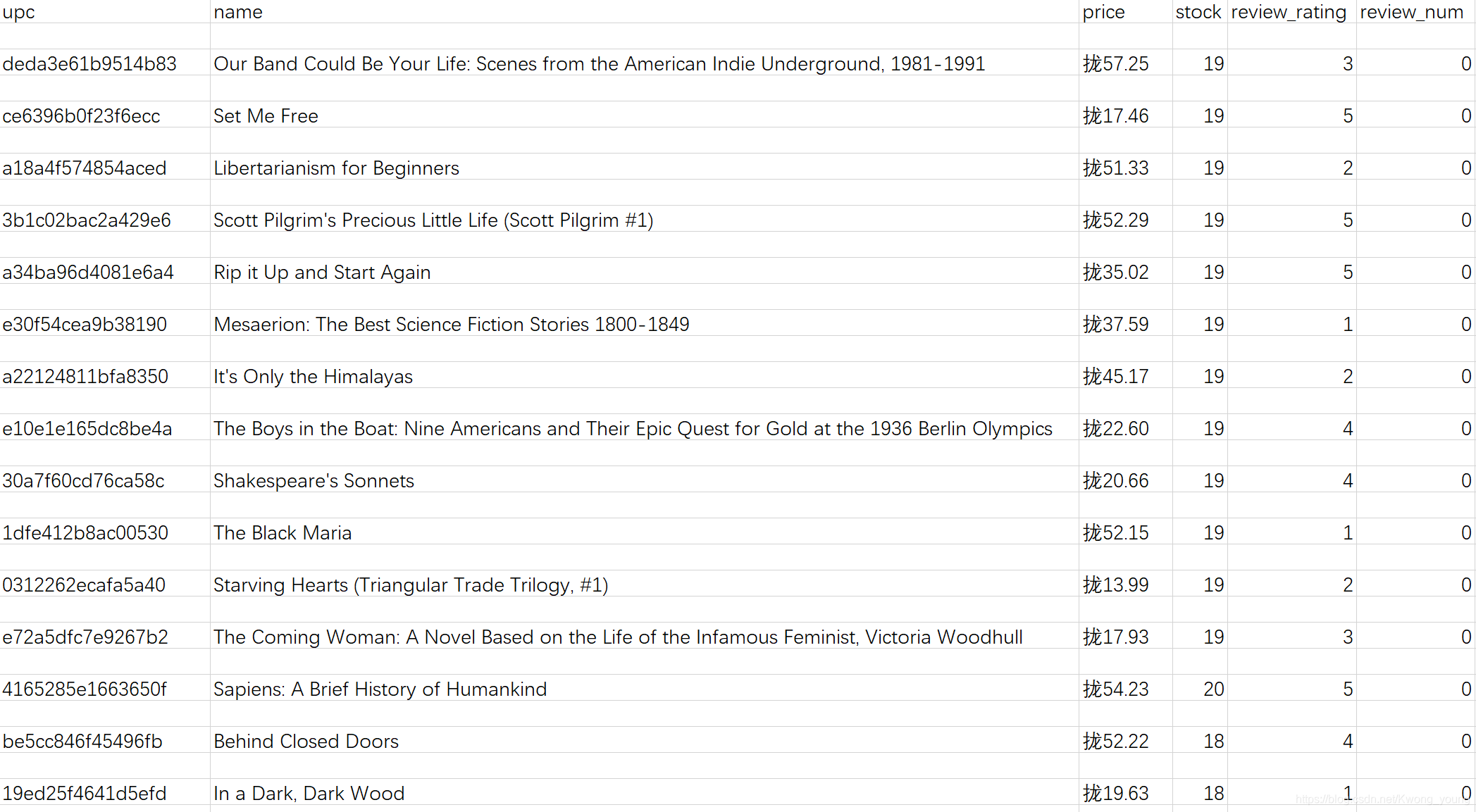
本次项目所留下的坑
- xpath()选择器
- css()选择器
- 正则表达式如何运用
- field是怎样处理数据的
- Item Pipeline是怎样处理数据的
- linkextractor怎样提取Url链接














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









