







从物理执行的角度透视Spark Job
视频学习来源:DT-大数据梦工厂 IMF传奇行动视频(后附王家林老师联系方式)
本期内容:
1 再次思考pipeline2 窄依赖物理执行内幕3 宽依赖物理执行内幕4 Job提交流程
思考一:pipeline(计算两种方式)
即使采用pipeline的方式,函数对依赖的RDD中的数据的操作也会有两种方式:
1、f(record),f作用于集合的每一条记录,每次只作用于一条记录;
2、f(record),f一次性作用于全部数据;
Spark采用第一种方式,原因:
1、无需等待,最大化使用集群的资源;
2、减少OOM的发生;
3、最大化的有利于并发;
4、可以精准控制每一个Partition本身(Dependency)及其内部的计算(最重要);
5、基于lineage的算子流动式函数式编程,减少中间结果的产生,并且可以最快的恢复;
疑问:会不会增加网络通信,答案是不会,因为在pipeline
思考二:思考Spark Job的物理式执行
Spark Application里边可以产生一个或者多个Job,例如Spark-shell默认启动的时候没有job,只是作为资源的分片程序,可以在里面写代码会产生若干个job,普通程序中一般会有不同的Action,每一个Action一般也会产生一个Job(也有情况是Action会产生其他Action)。
Spark是MapReduce思想的更加精致的实现,MapReduce有很多具体不同的实现,例如Hadoop的MapReduce,基本的计算流程如下:
首先并发,以JVM为对象的并发执行的mapper,mapper的map会产生输出数据,输出数据会根据Partition指定的规则放到Local FileSystem,然后在经由Shuffle、Sort、Aggregate变成Reducer中的reduce的输出,执行reduce产生的输出结果,Hadoop MapReduce执行的流程若然简单,但是笔记死板,尤其在构造复杂算法的时候,非常不利于算法的实现,且执行效率极为低下!
Spark执行时物理算法构造和物理执行时最最基本的核心最大化pipeline,pipeline愈多数据覆用越好,速度非常快,也就是数据被使用的时候再进行计算。
从数据流动的视角来说,是数据流动到计算的位置!
实质上从逻辑的角度看是算子在数据上流动;
从算法构建的角度而言,肯定是算子作用于数据,所以是算子在数据上流动,方便算法的构建;
从物理执行角度而言,是数据流动到计算的位置,有利于最高效的计算,方便系统最高效的运行。
对于pipeline而言,数据计算的位置就是每个Stage最后的RDD,前面的RDD都是最后一个步骤进行函数式展开的,即可以理解为一个函数。
内幕:每个Stage中除了最后一个RDD的算子是真实的以外,前面的算子都是假的。原因有下面两点:
1、从第5000个步骤要结果,然后进行算子合并,从后往前推进行函数式展开,进而产生链条;
2、JVM不知道什么是RDD;
由于计算的lazy特性,导致计算 从后往前回溯,形成Computing Chain,导致的结果就是需要首先计算出一个Stage内部左侧的RDD的本次计算依赖的Partition(实际计算是从前往后的),
第三点:窄依赖的物理执行内幕
一个Stage内部的RDD都是窄依赖,窄依赖计算本身是逻辑上看是从Stage内部最左侧的RDD开始立即计算的,根据Computing Chain,数据(Record)从一个计算步骤流动到下一个计算步骤,以此类推,知道计算到Stage内部的最后一个RDD来产生计算结果。
Computing Chian的构建是从后往前回溯构建而成的,而实际的物理计算则是让数据从前往后在算子上流动的,知道流动到不能在进行流动位置才开始计算下一个Record,这就导致一个美好的结果:
后面的RDD对前面的RDD的依赖虽然是Partition级别的数据集合的依赖,但是并不需要父RDD把Partition中所有的Records计算完毕才整体往后流动数据进行计算,这就极大的提高了计算速率!
/**
* An RDD that applies the provided function to every partition of the parent RDD.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false)
extends RDD[U](prev) {
override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
override def getPartitions: Array[Partition] = firstParent[T].partitions
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
第四点:宽依赖物理执行内幕
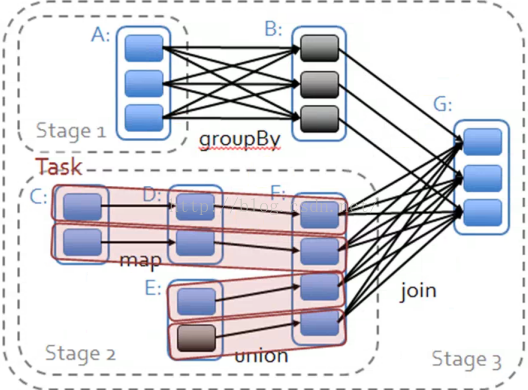
注:
必须等到依赖的父Stage中的最后一个RDD把全部数据彻底计算完毕,才能过经过Shuffle来计算当前的Stage(我们在写代码的时候尽量减少宽依赖)
/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
/**
* Approximate version of count() that returns a potentially incomplete result
* within a timeout, even if not all tasks have finished.
*/
def countApprox(
timeout: Long,
confidence: Double = 0.95): PartialResult[BoundedDouble] = withScope {
val countElements: (TaskContext, Iterator[T]) => Long = { (ctx, iter) =>
var result = 0L
while (iter.hasNext) {
result += 1L
iter.next()
}
result
}
val evaluator = new CountEvaluator(partitions.length, confidence)
sc.runApproximateJob(this, countElements, evaluator, timeout)
}
王家林老师是大数据技术集大成者,中国Spark第一人:
DT大数据梦工厂
新浪微博:www.weibo.com/ilovepains/
微信公众号:DT_Spark
博客:http://.blog.sina.com.cn/ilovepains
TEL:18610086859
Email:18610086859@vip.126.com














 4588
4588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









