






前言
在学习的过程中,我们往往忽略了知识发展的过程,这让我们在理解和记忆的时候就变得尤为困难,不要盲目“记公式”,尝试去了解“公式”因何而来,你会发现根本不需要记忆。
在这篇文章中,会详细解释浮点数是什么意思以及IEEE754的规则是如何产生的。
一、浮点数
1.为什么要引入浮点数?
用定点数表示小数时,存在数值范围、精度范围有限的缺点,所以在计算机中,我们一般使用「浮点数」来表示小数。
2.浮点数是什么意思
之前我们学习了定点数,其中「定点」指的是约定小数点位置固定不变。那浮点数的「浮点」就是指,其小数点的位置是可以是漂浮不定的。
这怎么理解呢?
其实,浮点数是采用科学计数法的方式来表示的,例如十进制小数 8.345,用科学计数法表示,可以有多种方式:
8.345 = 8.345 * 10^0
8.345 = 83.45 * 10^-1
8.345 = 834.5 * 10^-2
...
看到了吗?用这种科学计数法的方式表示小数时,小数点的位置就变得「漂浮不定」了,这就是相对于定点数,浮点数名字的由来。
使用同样的规则,对于二进制数,我们也可以用科学计数法表示,也就是说把基数 10 换成 2 即可。
3.浮点数如何表示数字
我们已经知道,浮点数是采用科学计数法来表示一个数字的,它的格式可以写成这样:
V = (-1)^S * M * R^E
其中各个变量的含义如下:
- S:符号位,取值 0 或 1,决定一个数字的符号,0 表示正,1 表示负
- M:尾数,用小数表示,例如前面所看到的 8.345 * 10^0,8.345 就是尾数
- R:基数,表示十进制数 R 就是 10,表示二进制数 R 就是 2
- E:指数,用整数表示,例如前面看到的 10^-1,-1 即是指数
例如:
十进制数
121
=
(
−
1
)
0
×
1.21
×
1
0
2
121=(-1)^0 × 1.21 × 10^2
121=(−1)0×1.21×102
二进制数
−
10101
=
(
−
1
)
1
×
1.0101
×
2
4
-10101=(-1)^1×1.0101×2^4
−10101=(−1)1×1.0101×24
假设现在我们用 32 bit 表示一个浮点数,把以上变量按照一定规则,填充到这些 bit 上就可以了:
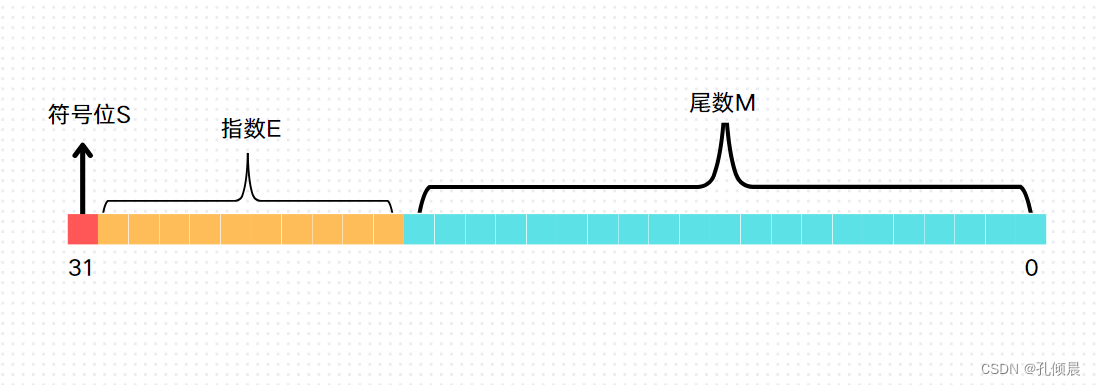
假设我们定义如下规则来填充这些 bit:
- 符号位 S 占 1 bit
- 指数 E 占 10 bit
- 尾数 M 占 21 bit
按照这个规则,将十进制数 25.125 转换为浮点数,转换过程就是这样的(D代表十进制,B代表二进制):
- 整数部分:25(D) = 11001(B)
- 小数部分:0.125(D) = 0.001(B)
- 用二进制科学计数法表示:25.125(D) = 11001.001(B) = 1.1001001 * 2^4(B)
所以符号位 S = 0,尾数 M = 1.001001(B),指数 E = 4(D) = 100(B)。
按照上面定义的规则,填充到 32 bit 上,就是这样:
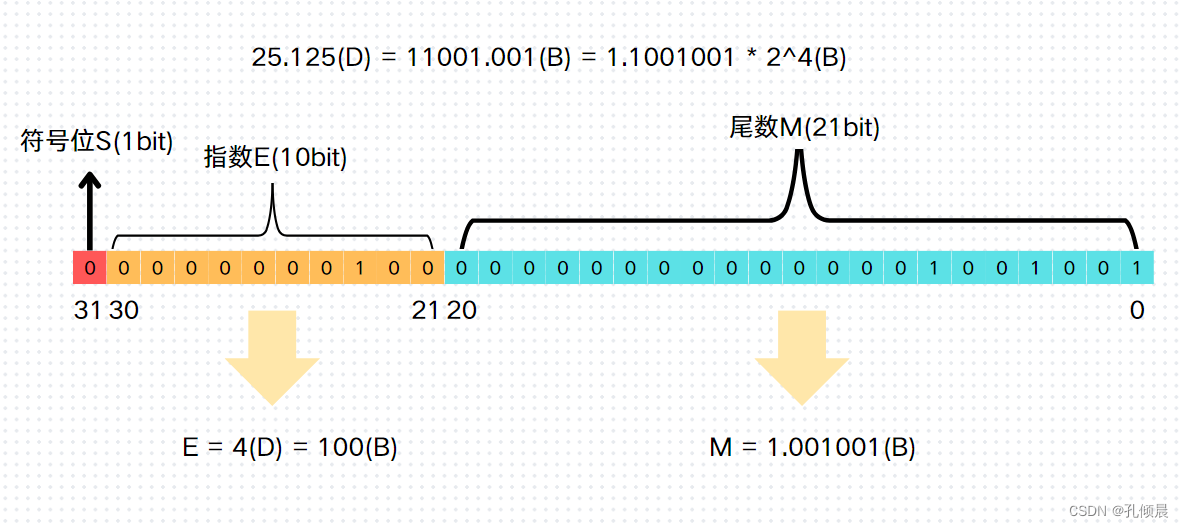
浮点数的结果就出来了,是不是很简单?
但这里有个问题,我们刚才定义的规则,符号位 S 占 1 bit,指数位 E 占 10 bit,尾数 M 占 21 bit,这个规则是我们拍脑袋随便定义出来的。
如果你也想定一个新规则,例如符号位 S 占 1 bit,指数位 E 这次占 5 bit,尾数 M 占 26 bit,是否也可以?当然可以。
按这个规则来,那浮点数表示出来就是这样:
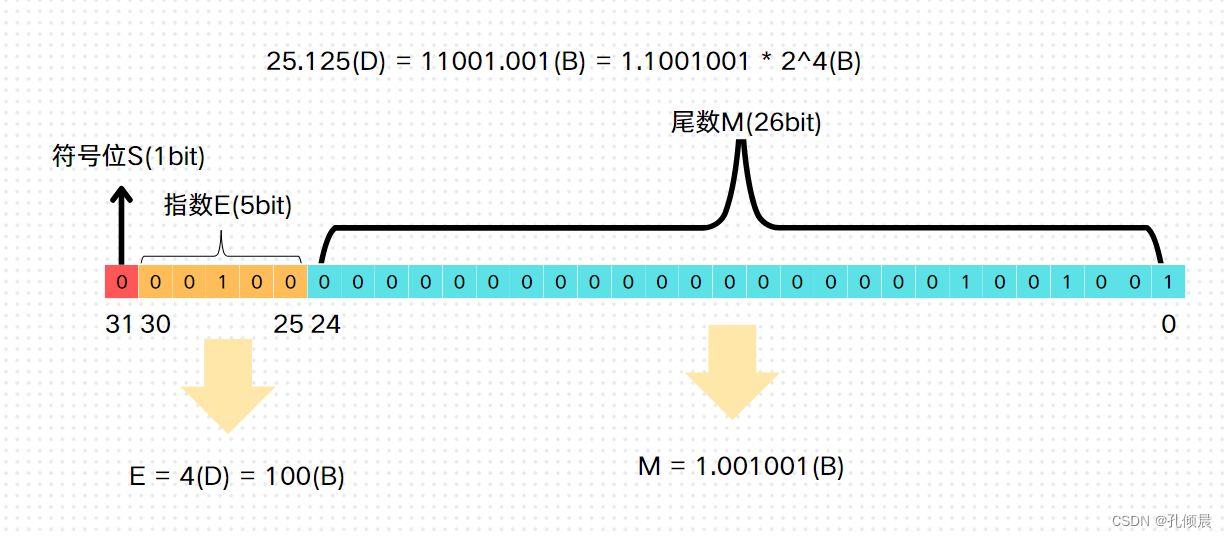
我们可以看到,指数和尾数分配的位数不同,会产生以下情况:
- 指数位越多,尾数位则越少,其表示的范围越大,但精度就会变差,反之,指数位越少,尾数位则越多,表示的范围越小,但精度就会变好
- 一个数字的浮点数格式,会因为定义的规则不同,得到的结果也不同,表示的范围和精度也有差异
早期人们提出浮点数定义时,就是这样的情况,当时有很多计算机厂商,例如IBM、微软等,每个计算机厂商会定义自己的浮点数规则,不同厂商对同一个数表示出的浮点数是不一样的。
这就会导致,一个程序在不同厂商下的计算机中做浮点数运算时,需要先转换成这个厂商规定的浮点数格式,才能再计算,这也必然加重了计算的成本。
那怎么解决这个问题呢?业界迫切需要一个统一的浮点数标准。
二、浮点数标准
直到1985年,IEEE 组织推出了浮点数标准,就是我们经常听到的 IEEE754 浮点数标准,这个标准统一了浮点数的表示形式,并提供了 2 种浮点格式:
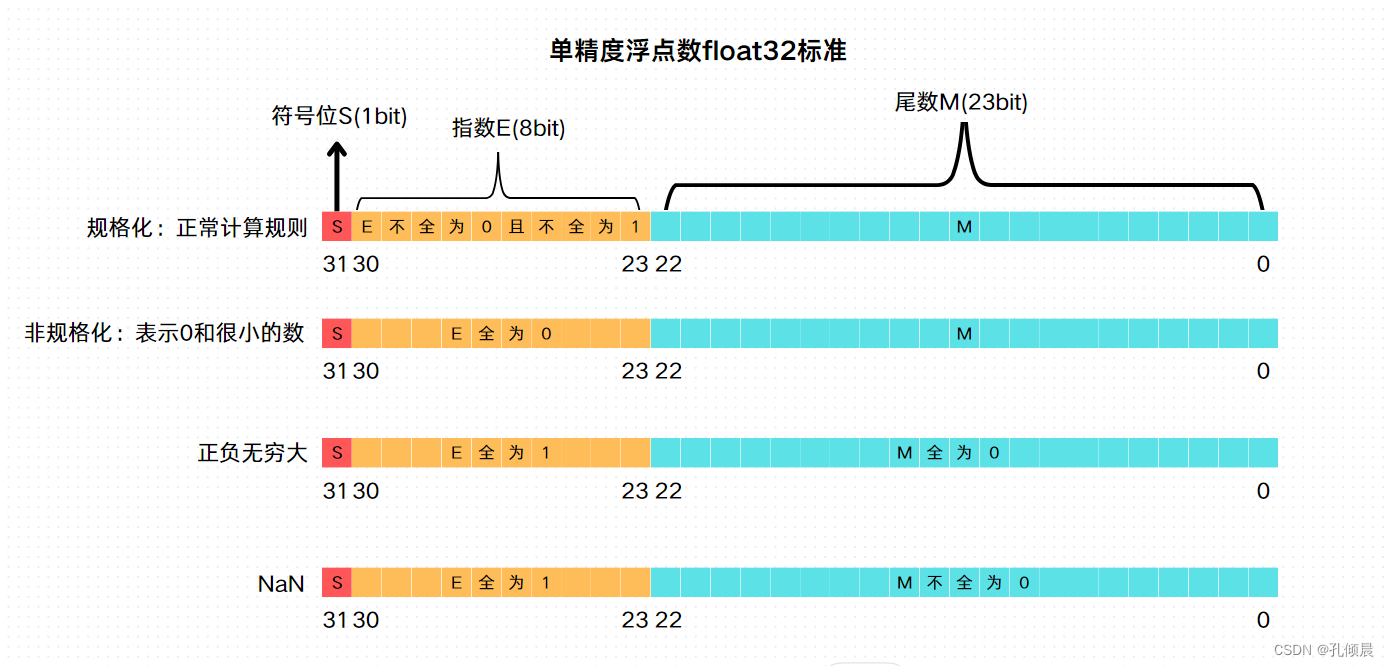
- 单精度浮点数 float:32 位,符号位 S 占 1 bit,指数 E 占 8 bit,尾数 M 占 23 bit
- 双精度浮点数 double:64 位,符号位 S 占 1 bit,指数 E 占 11 bit,尾数 M 占 52 bit
为了使其表示的数字范围、精度最大化,浮点数标准还对指数和尾数进行了规定:
-
指数 E ,
表示单精度浮点数 float 时,指数一共占 8 bit,8位二进制可以表示256种状态, IEEE754规定, 指数位用于表示[-127, 128]范围内的指数.
不过为了表示起来更方便, 浮点型的指数位都有一个固定的偏移量(bias), 用于使 指数 + 这个偏移量 = 一个非负整数. 这样指数位部分就不用为如何表示负数而担心了.
规定: 在32位单精度类型中, 这个偏移量是127. 在64位双精度类型中, 偏移量是1023.
即, 如果你运算后得到的指数是 -127, 那么偏移后, 在指数位中就需要表示为: -127 + 127(偏移量) = 0
如果你运算后得到的指数是 -10, 那么偏移后, 在指数位中需要表示为: -10 + 127(偏移量) = 117
看, 有了偏移量, 指数位中始终都是一个非负整数.
-
尾数M
①隐藏高位
你会发现, 尾数部分的最高位始终为1. 比如这里的 1.1001001, 这是因为, 规范化之后, 尾数中的小数点会位于左起第一位和第二位之间. 且第一位是个非0数. 而二进制中, 每一位可取值只有0或1, 如果第一位非0, 则第一位只能为1. 所以在存储尾数时, 可以省略前面的 1和小数点. 只记录尾数中小数点之后的部分, 这样就节约了一位内存. 所以这里只需记录剩余的尾数部分: 1001001
所以, 以后再提到尾数, 如无特殊说明, 指的其实是隐藏了整数部分1. 之后, 剩下的小数部分
②低位补0
有时候尾数会不够填满尾数位(即图中的蓝色格子). 比如这里的, 尾数1001001不够23位
此时, 需要在低位补零, 补齐23位.
之所以在低位补0, 是因为尾数中存储的本质上是二进制的小数部分, 所以如果想要在不影响原数值的情况下, 填满23位, 就需要在低位补零.
比如, 要把二进制数1.01在不改变原值的情况下填满八位内存, 写出来就应该是: 1.010 0000, 即需要在低位补0
同理, 本例中因为尾数部分存储的实际上是省略了整数部分 1. 之后, 剩余的小数部分, 所以这里补0时也需要在低位补0:
原尾数是: 01001(不到23位)
补零之后是: 0100 1000 0000 0000 000 (补至23位)
为什么IEEE754浮点数标准一定要在低位补0才不会影响原数值呢?
因为我们刚才刚讲了隐藏高位这一操作,如果在高位补0
原尾数是: 01001(不到23位)补零之后是: 0000 0000 0000 0001 001 (补至23位)
将尾数和隐藏的高位组合后得到1.0000 0000 0000 0001 001(高位补0),是不是原数值就变了?
有了这个统一的浮点数标准,我们再把 25.125 转换为标准的 float 浮点数:
- 整数部分:25(D) = 11001(B)
- 小数部分:0.125(D) = 0.001(B)
- 用二进制科学计数法表示:25.125(D) = 11001.001(B) = 1.1001001 * 2^4(B)
所以 S = 0,尾数 M = 1.001001 = 001001(去掉1,隐藏位),指数 E = 4 + 127(中间数) = 131(D) = 10000011(B)。填充到 32 bit 中,如下:
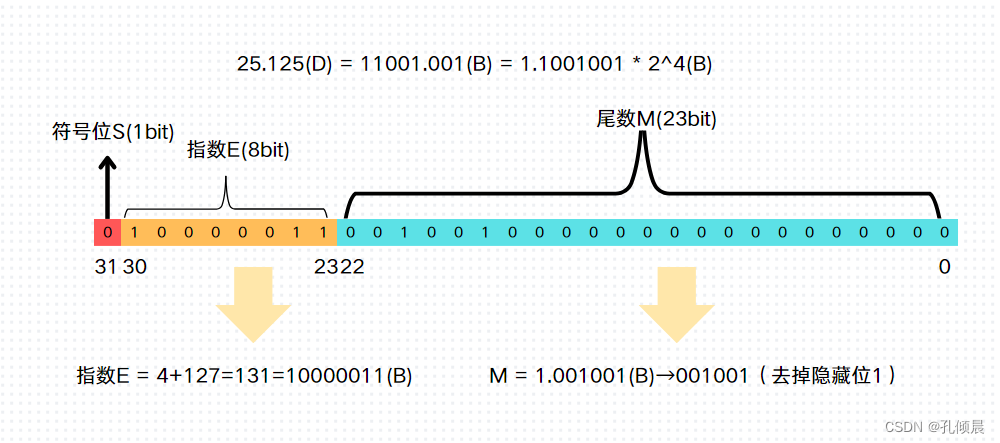
除了规定尾数和指数位,还做了以下规定:
- 指数 E 非全 0 且非全 1:规格化数字,按上面的规则正常计算
- 指数 E 全 0,尾数非 0:非规格化数,尾数隐藏位不再是 1,而是 0(M = 0.xxxxx),这样可以表示 0 和很小的数
- 指数 E 全 1,尾数全 0:正无穷大/负无穷大(正负取决于 S 符号位)
- 指数 E 全 1,尾数非 0:NaN(Not a Number)
关于IEEE754浮点数标准,还有很多内容要谈,本文只是帮助新手快速理解浮点数及IEEE754标准的由来。
参考文献
[1] Kaito.什么是定点数?[EB/OL].2021:[2024].https://zhuanlan.zhihu.com/p/339949186.
[1] 等夏天再见啦.IEEE754标准: 一 , 浮点数在内存中的存储方式[EB/OL].2021:[2024].https://zhuanlan.zhihu.com/p/343033661.


















 1935
1935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











