







【selenium】selenium+chrome+chromedriver部署
1. 无界面的使用引言
1.1 优势:
- 最大近似的模拟用户访问
- 最小成本解决页面跳转问题
- 不需要设置Header
- 根据用户名和密码可以进行自动化登录
1.2 劣势:
- 占用CPU资源与内存不是一般的多
- 提高了并发量,因为无界面会加载各种js和css
1.3 个人对于无界面的态度:
- 如果使用代理IP且代理IP的并发量有上限,那么采用无界面的话,压力就太大了,加载每一个静态资源都是一个并发
- 网上很多人说无界面最文本的提取简单,其实真的不如XPath做
- 我使用无界面一般只有一个目的,场景有两个,但目的都是为了跳过反爬
- 比如爬取电商平台,没有登录的Cookie是会被重定向到登录界面的,可以把几百个账号和密码保存在键值对中,写一个自动化登录的py文件,只要登录后保存在Header中的Cookie
- 对于阿里反爬(最近火的挺厉害,CSDN的博客最近也加入了阿里的反爬),阿里反爬允许不登录的用户访问,但会验证访问者的Cookie,也就是说,第一次访问某博客地址,响应回来的内容是JS代码,JS设置加密的Cookie并刷新页面,因为提交的Cookie是合法的,所以在第二次访问的时候才看到页面的真正内容,为了不琢磨被加密的JS加密代码,用无界面做重定向,拿Cookie
- 能不用就不用这玩意
2 Windows上部署无界面
- selinum
- 谷歌浏览器chrome
- 谷歌浏览器引擎chromedriver
注意事项:
- chrome的版本要与chromedriver的版本一致,否则不稳
- chrome最好用官方的,安装官方的chrome,用默认的安装方式
2.1 安装selenium
pip install selenium
2.2 安装chrome
官网地址:
- https://cloud.google.com/chrome-enterprise/browser/download/
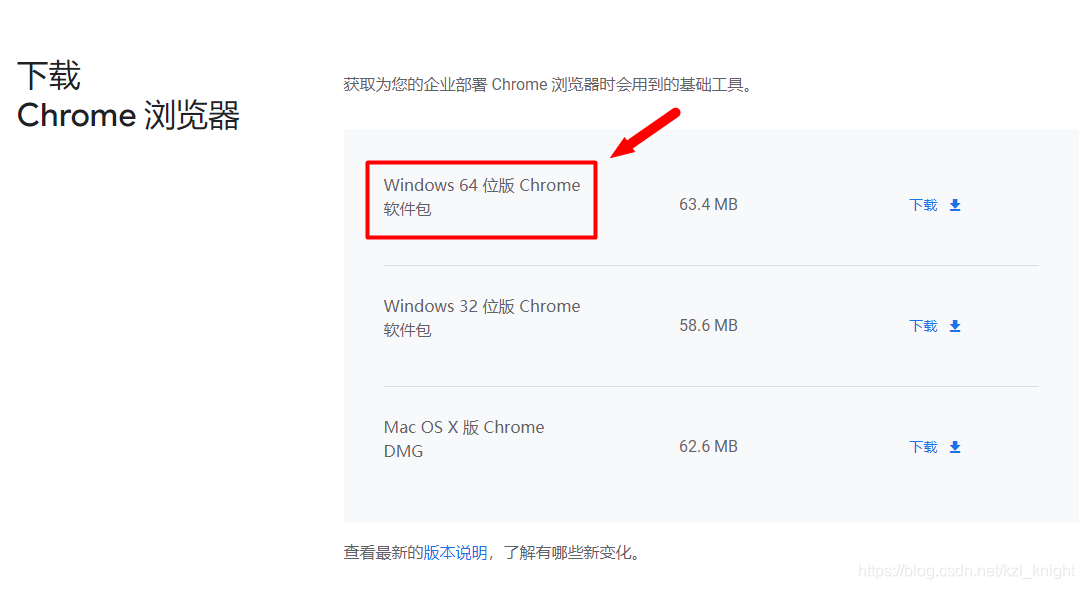
注:谷歌浏览器不许你下载指定的版本
2.3 安装chromedirver
镜像地址:
- https://npm.taobao.org/mirrors/chromedriver/
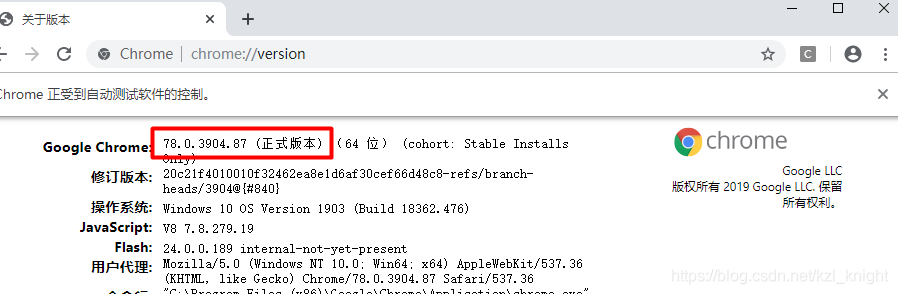
2.4 查看自己chrome的版本
在浏览器中输入:chrome://version/
2.4.2 下载对应版本的chromedriver
在chromedriver的下载地址中:
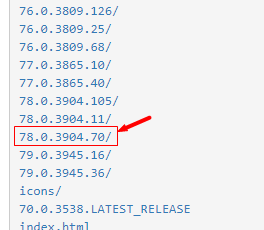
没有版本号完全一致的,只能找个差不多的,我测试后发现这两个搭配没问题
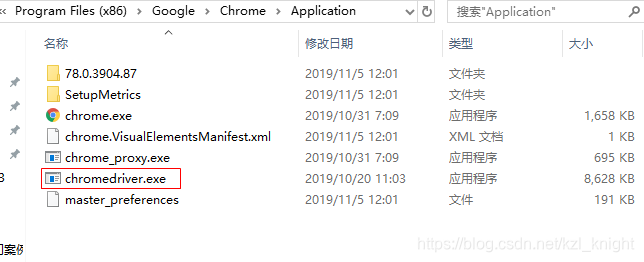
2.4.3 把chromedriver放置在chrome文件夹中
- 默认安装路径:C:\Program Files (x86)\Google\Chrome\Application
3. 通过selenium启动chrome
- 代码
from selenium import webdriver
# 实例化driver
driver = webdriver.Chrome(
executable_path='C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe',
)
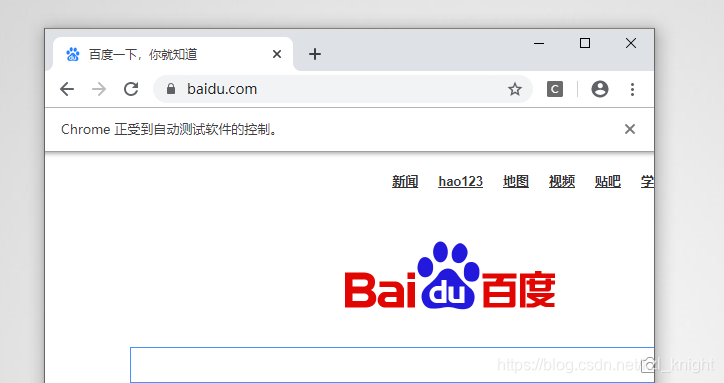
driver.get('http://www.baidu.com')
- 运行结果
















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











