







 本文介绍了如何使用C++设计并实现一个类C语言的词法分析器。在编译和运行时,测试文件需置于工程目录,生成的可执行文件应放于相应目录以确保正确执行。
本文介绍了如何使用C++设计并实现一个类C语言的词法分析器。在编译和运行时,测试文件需置于工程目录,生成的可执行文件应放于相应目录以确保正确执行。
一、词法分析器简介
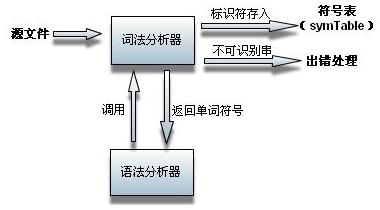
词法分析过过程,即从左至右扫描输入串,并将其转化为有特定含义单词符号(token,相当于DFA中的终结符)。同时,删除空白符(whitespace,包括空格,'/t','/r','/n')。其中单词符号种类包括:标识符,关键字,常数(本例中包括int,real,字符串,char类型),还有{,},[,],(,),;,*/-+等特定符号。
词法分析器相当于语法分析器的一个子函数。当语法分析器为了分析一个句子时,就需要调用词法分析器来获取一个单词,按需索取,并不是我原先所理解的那样,先由词法分析器把源文件一遍统统分析完,再全部交与语法分析器。就像吃饭一样,饿了才做,而不是一次都做出来,以后慢慢吃,这样可以避免浪费,不是吗?
具体流程图如下:
![]()
![]()
二、DFA(关键部分)
图就不画了,现在没什么时间,弄这个耗了我三天了,得准备复试了。
DFA的实现是采用switch-case的控制流方式,case结点都为DFA的非终结态,终态直接返回。当然case中又有if-else控制语句。
Token的获取采用“地主-长工”模式(自创的,待以后对GOF的模式熟悉后再为其正名),即GetNextToken()作为lex对外接口,负责返回一个Token,这是个体面活,相当于一个地主。然而,其内部,长达250多行的DFA转化工作由它的长工ProceedChar()来完成。地主每次从输入串中获取一个char,然后交给长工,然后长工根据以前记录的状态以及后文(超前搜索,主要用于/**/,<=,==,>=,!=等两个以上字符组合的识别中),来判断出这个Token何时结束,是哪一种类(id)。
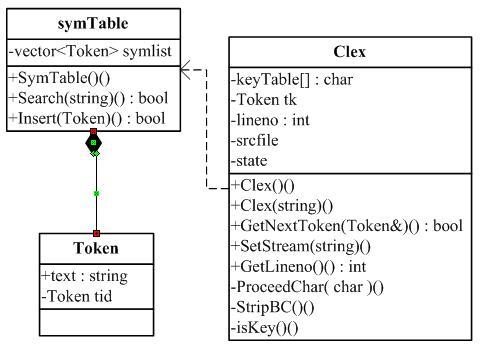
三、实现之类图
Clex:词法分析器
symTalbe:符号表,insert(Token tk)操作先判断符号表中是否已先存在tk,若是则无操作
Token:单词符号,text属性为表示该单词符号的字符串,tid为其属性
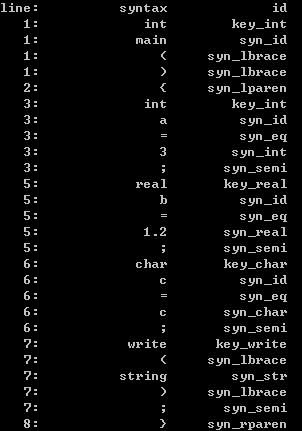
四、程序结果
注:不支持头文件的识别,数据类型只有int,real,char。其余和C语言类似
输入测试程序代码:
int main()
{
int a=3; /*dddd
dddd*/
real b=1.2;
char c='c';
write("string");
}
结果:
五、开发笔记一二
3. ios 类的 get (), unget (), peek() 对单个输入字符的读取,退回输入流,测试方便了超前搜索的实现。 但要主义当srcfile.get(c)返回假,即文件读取完毕时,c的值是没有改变的,所以此时自己设置其c=NULL,可方便后文对文件结束的判断。
六、关键代码( 欢迎下载源文件并指导)
见过250多行的函数吗?反正我是第一次写这么长的,调试过程是很辛苦滴:)
 bool Clex::GetNextToken(Token
&
tok)
bool Clex::GetNextToken(Token
&
tok)
 {
{
 StripBC();
StripBC();
tk.text.clear();
tk.tid=syn_start;
state=dfa_start;
char c;
//c为空时表示文件读取完毕,但此时必须让ProceedChar也知道,故用do-while
do
 {
{
if( !srcfile.get(c))
c=NULL;
 }while((state=ProceedChar(c))<dfa_INTERVAL && c);
}while((state=ProceedChar(c))<dfa_INTERVAL && c);
if( tk.tid==syn_id && !isKey() ) //判断标识符是否为关键字,若不是插入符号表
symtbl.Insert(tk);
tok=tk;
if( NULL==c) return false; //文件读取完毕,返回false
return true; //文件尚未读完
 }
}
//
DFA
DFA_state Clex::ProceedChar(
char
ch)
{
switch( state )
{
case dfa_start:
if( isalpha(ch) )
{
tk.text+=ch;
return dfa_inid;
} //come to be a indentifer
else if( isdigit(ch) )
{
tk.text+=ch;
return dfa_inint;
}
else if( ';'==ch )
{
tk.text=ch;
tk.tid=syn_semi;
return dfa_semi;
}
else if( '('==ch )
{
tk.text=ch;
tk.tid=syn_lbrace;
return dfa_lbrace;
}
else if( ')
词法分析过过程,即从左至右扫描输入串,并将其转化为有特定含义单词符号(token,相当于DFA中的终结符)。同时,删除空白符(whitespace,包括空格,'/t','/r','/n')。其中单词符号种类包括:标识符,关键字,常数(本例中包括int,real,字符串,char类型),还有{,},[,],(,),;,*/-+等特定符号。
词法分析器相当于语法分析器的一个子函数。当语法分析器为了分析一个句子时,就需要调用词法分析器来获取一个单词,按需索取,并不是我原先所理解的那样,先由词法分析器把源文件一遍统统分析完,再全部交与语法分析器。就像吃饭一样,饿了才做,而不是一次都做出来,以后慢慢吃,这样可以避免浪费,不是吗?
具体流程图如下:
二、DFA(关键部分)
图就不画了,现在没什么时间,弄这个耗了我三天了,得准备复试了。
DFA的实现是采用switch-case的控制流方式,case结点都为DFA的非终结态,终态直接返回。当然case中又有if-else控制语句。
Token的获取采用“地主-长工”模式(自创的,待以后对GOF的模式熟悉后再为其正名),即GetNextToken()作为lex对外接口,负责返回一个Token,这是个体面活,相当于一个地主。然而,其内部,长达250多行的DFA转化工作由它的长工ProceedChar()来完成。地主每次从输入串中获取一个char,然后交给长工,然后长工根据以前记录的状态以及后文(超前搜索,主要用于/**/,<=,==,>=,!=等两个以上字符组合的识别中),来判断出这个Token何时结束,是哪一种类(id)。
三、实现之类图
Clex:词法分析器
symTalbe:符号表,insert(Token tk)操作先判断符号表中是否已先存在tk,若是则无操作
Token:单词符号,text属性为表示该单词符号的字符串,tid为其属性
四、程序结果
注:不支持头文件的识别,数据类型只有int,real,char。其余和C语言类似
输入测试程序代码:
int main()
{
int a=3; /*dddd
dddd*/
real b=1.2;
char c='c';
write("string");
}
结果:
五、开发笔记一二
1.编译运行时,测试文件应放在工程目录下,生成可执行文件后,才可放在可执行文件目录下。
2.编程时最好一句一行,以便调试。3. ios 类的 get (), unget (), peek() 对单个输入字符的读取,退回输入流,测试方便了超前搜索的实现。 但要主义当srcfile.get(c)返回假,即文件读取完毕时,c的值是没有改变的,所以此时自己设置其c=NULL,可方便后文对文件结束的判断。
六、关键代码( 欢迎下载源文件并指导)
见过250多行的函数吗?反正我是第一次写这么长的,调试过程是很辛苦滴:)
bool Clex::GetNextToken(Token
&
tok)
{
 StripBC(); tk.text.clear(); tk.tid=syn_start; state=dfa_start; char c; //c为空时表示文件读取完毕,但此时必须让ProceedChar也知道,故用do-while do {
StripBC(); tk.text.clear(); tk.tid=syn_start; state=dfa_start; char c; //c为空时表示文件读取完毕,但此时必须让ProceedChar也知道,故用do-while do {
 if( !srcfile.get(c)) c=NULL; }while((state=ProceedChar(c))<dfa_INTERVAL && c); if( tk.tid==syn_id && !isKey() ) //判断标识符是否为关键字,若不是插入符号表 symtbl.Insert(tk); tok=tk; if( NULL==c) return false; //文件读取完毕,返回false return true; //文件尚未读完}
//
DFA
DFA_state Clex::ProceedChar(
char
ch)
{
switch( state ) {
case dfa_start: if( isalpha(ch) ) {
tk.text+=ch; return dfa_inid; } //come to be a indentifer else if( isdigit(ch) ) {
tk.text+=ch; return dfa_inint; } else if( ';'==ch ) {
tk.text=ch; tk.tid=syn_semi; return dfa_semi; } else if( '('==ch ) {
tk.text=ch; tk.tid=syn_lbrace; return dfa_lbrace; } else if( ')
if( !srcfile.get(c)) c=NULL; }while((state=ProceedChar(c))<dfa_INTERVAL && c); if( tk.tid==syn_id && !isKey() ) //判断标识符是否为关键字,若不是插入符号表 symtbl.Insert(tk); tok=tk; if( NULL==c) return false; //文件读取完毕,返回false return true; //文件尚未读完}
//
DFA
DFA_state Clex::ProceedChar(
char
ch)
{
switch( state ) {
case dfa_start: if( isalpha(ch) ) {
tk.text+=ch; return dfa_inid; } //come to be a indentifer else if( isdigit(ch) ) {
tk.text+=ch; return dfa_inint; } else if( ';'==ch ) {
tk.text=ch; tk.tid=syn_semi; return dfa_semi; } else if( '('==ch ) {
tk.text=ch; tk.tid=syn_lbrace; return dfa_lbrace; } else if( ')
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









