









前言
你们项目中使用过线程池吗,它的工作过程是怎样的;你了解过ThreadLocal吗,你知道它的底层原理吗。本文重点对面试的问题进行介绍,祝愿每位程序员都能顺利上岸!!!
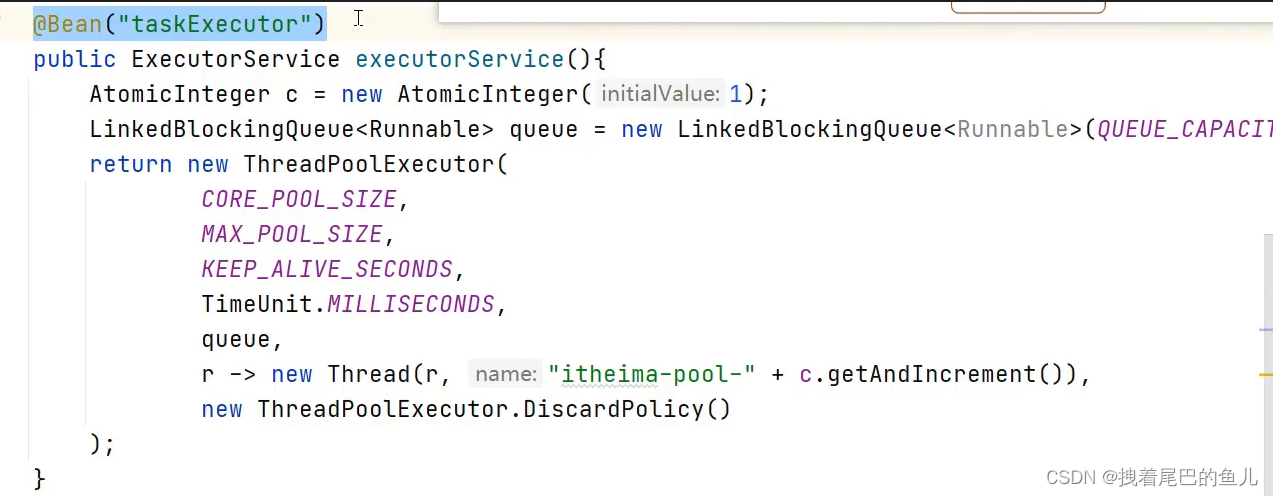
一、你们项目中用过线程池吗,你们怎么定义核心线程数,它的工作过程是怎样的?
项目中我们通过 ThreadPoolExecutor 来定义一个线程池,进行任务的提交;
1.1 jdk 中自带的线程池有哪些,为什么你们要自定义线程池,用现有的不好吗?
1.1.1 jdk 中自带的线程池有哪些:
固定线程数的线程池
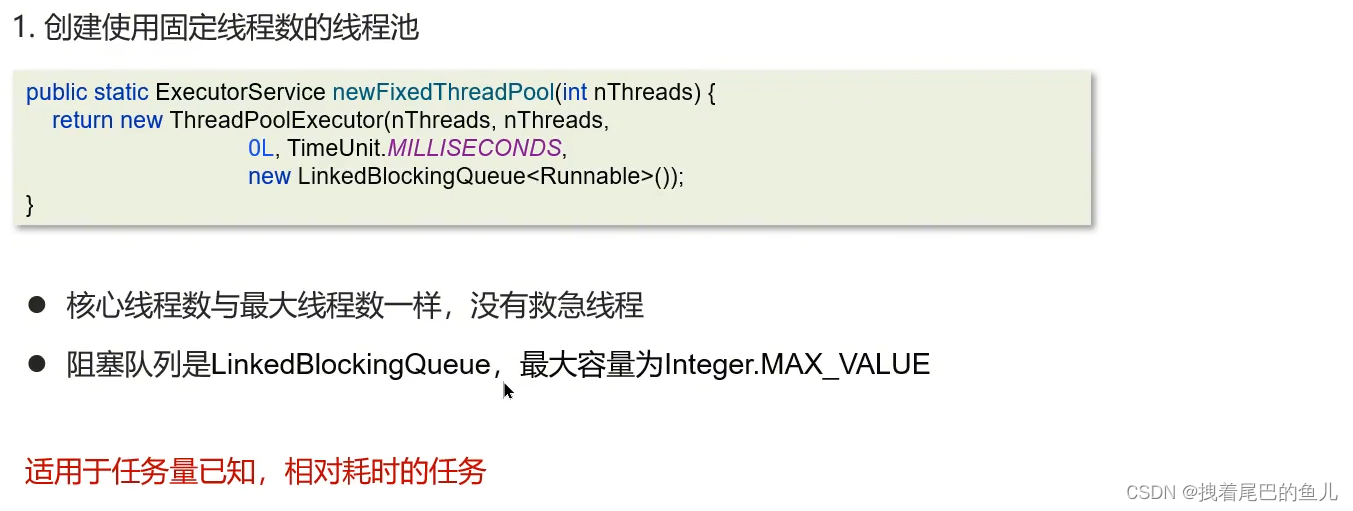
单线程化的线程池,它只会用唯一的工作线程来执行任 务,保证所有任务按照指定顺序(FIFO)执行.
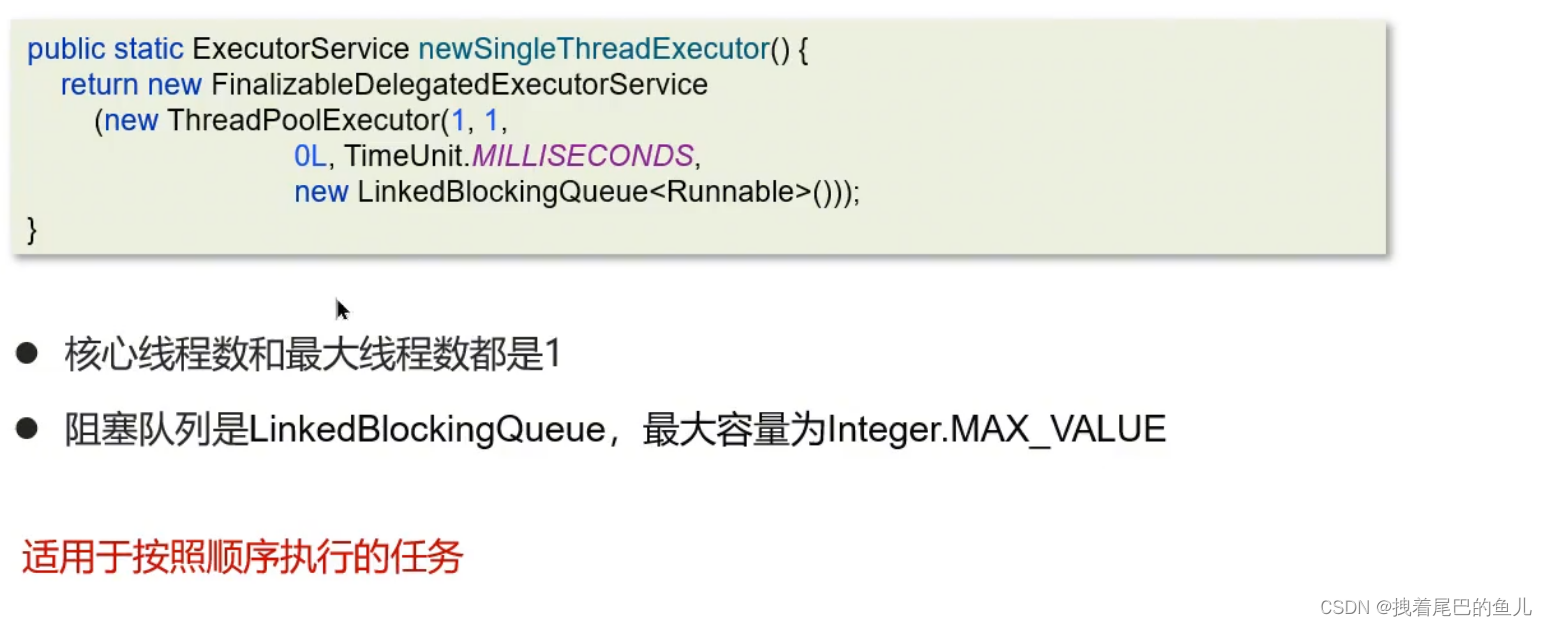
按需分配的线程池

以一定的频率进行任务调度的线程池
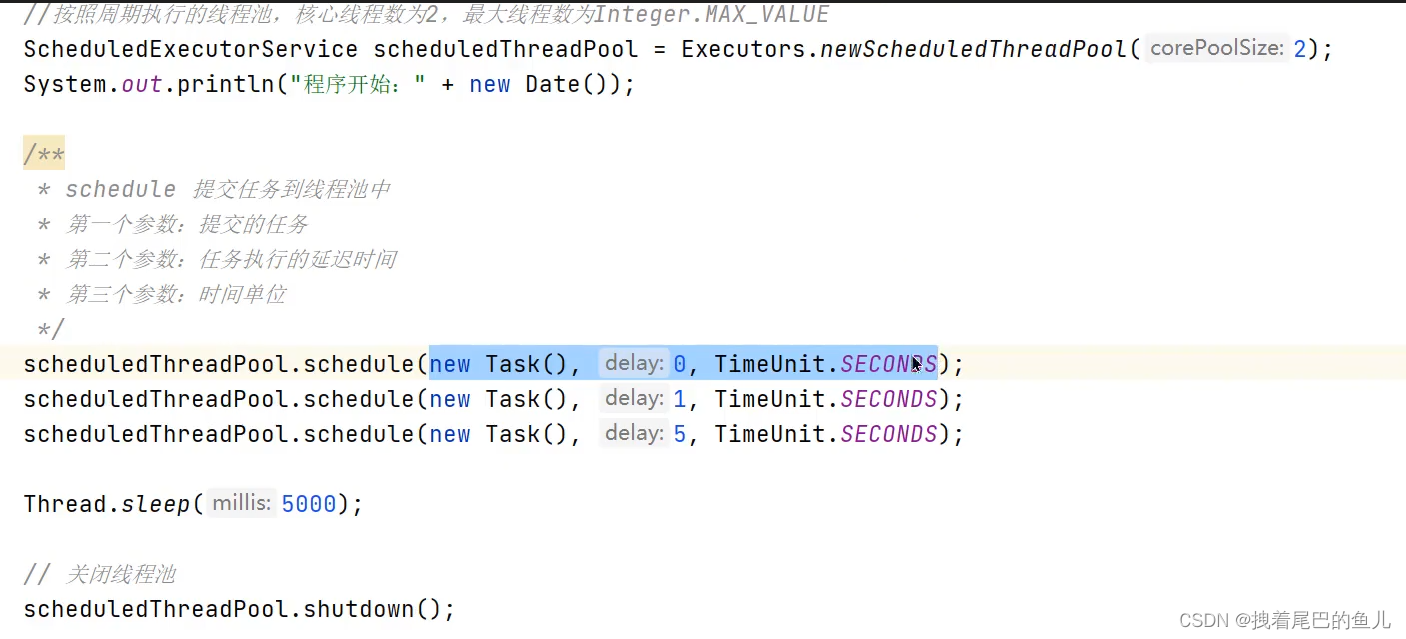
1.1.2 线程池的核心参数有哪些:

- corePoolSize 核心线程数目
- maximumPoolSize 最大线程数目=(核心线程+救急线程的最大数目)
- keepAliveTime 生存时间-救急线程的生存时间,生存时间内没有新任务,此线程资源会释放
- unit 时间单位-救急线程的生存时间单位,如秒、毫秒等
- workQueue-当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
- threadFactory线程工厂-可以定制线程对象的创建,例如设置线程名字、是否是守护线程等
- handler拒绝策略-当所有线程都在繁忙,workQueue 也放满时,会触发拒绝策略
1.1.3 你们为什么还要自定义线程池:
线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下
1)FixedThreadPool和SingleThreadPool允许的请求队列长度为 Integer.MAX VALUE,可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool :
允许的创建线程数量为 Integer.MAX VALUE,可能会创建大量的线程,从而导致 OOM。
1.1.4 你们定义线程时核心线程和最大线程数量怎么确定:
根据不同的业务,核心线程数量也不相同,通常是计算密集型核心线程数为:cpu 核数+1;IO 密集型 核心线程数为:cpu 核数*2 +1;

1.2 你了解过线程池的工作过程吗
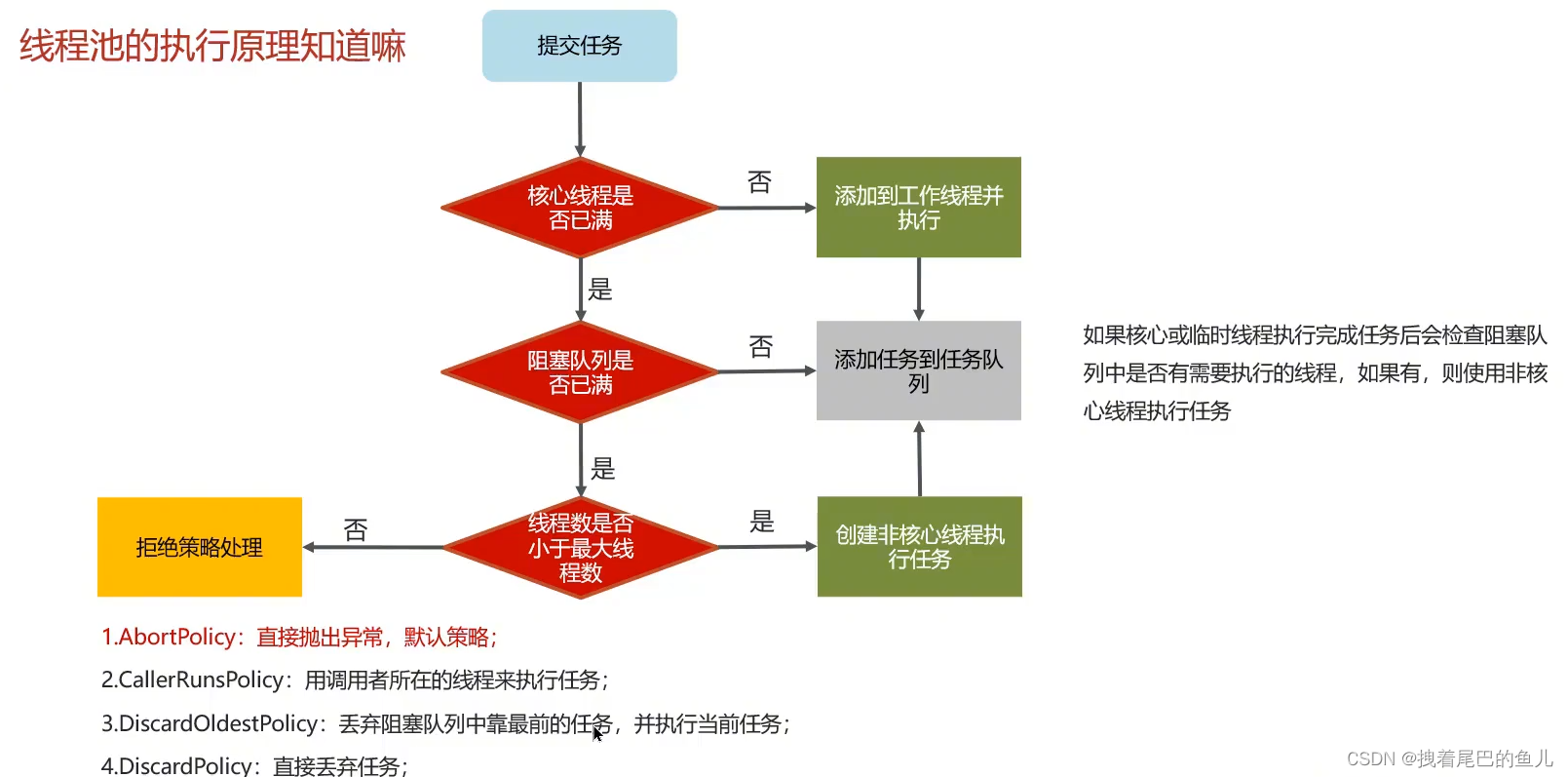
- 如果线程池中的线程还没有达到核心线程数,则创建线程,执行任务;
- 如果当前线程池的线程已经达到核心线程数,如果队列没有满,则放入队列;
- 如果队列已经满了:
- 如果当前线程池还没有达到最大线程池,则创建线程执行任务;
- 如果已经达到最大线程池个数,则执行拒绝策略;
- 如果队列已经满了:
1.3 你们都在哪些场景中使用过线程池
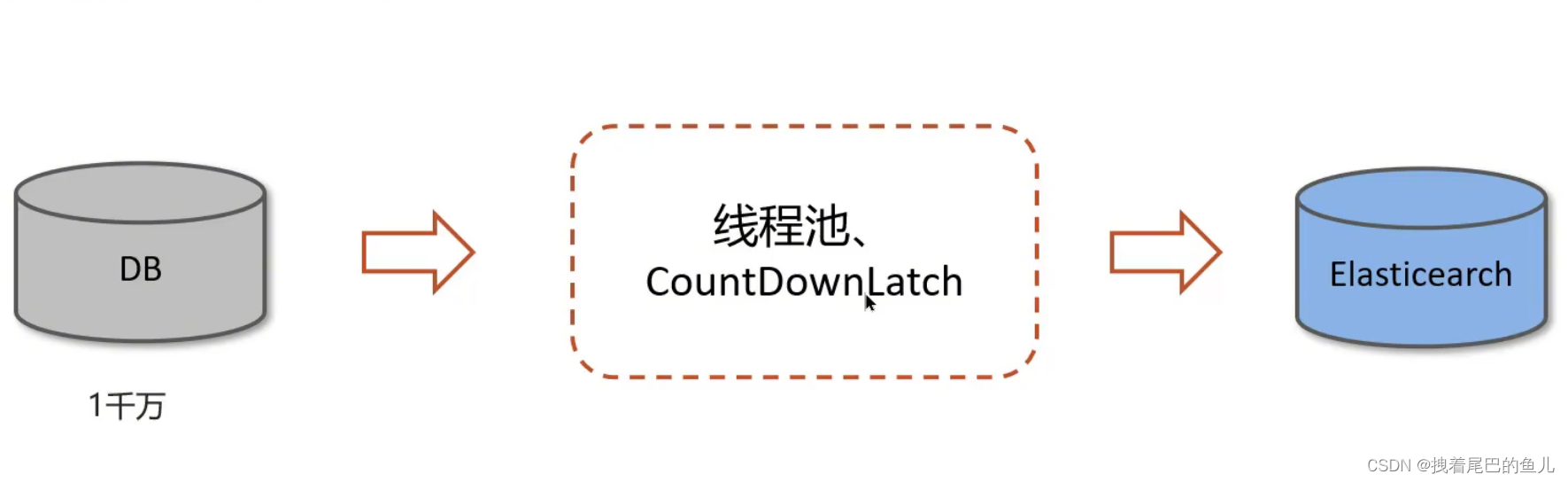
1.3.1 ES 数据批量导入:
在我们项目上线之前,我们需要把数据库中的数据一次性的同步到es索引库中,但是当时的数据好像是1000万左右一次性读取数据肯定不行(oom异常),当时我就想到可以使用线程池的方式导入,利用CountDownLatch来控制就能避免一次性加载过多,防止内存溢出。
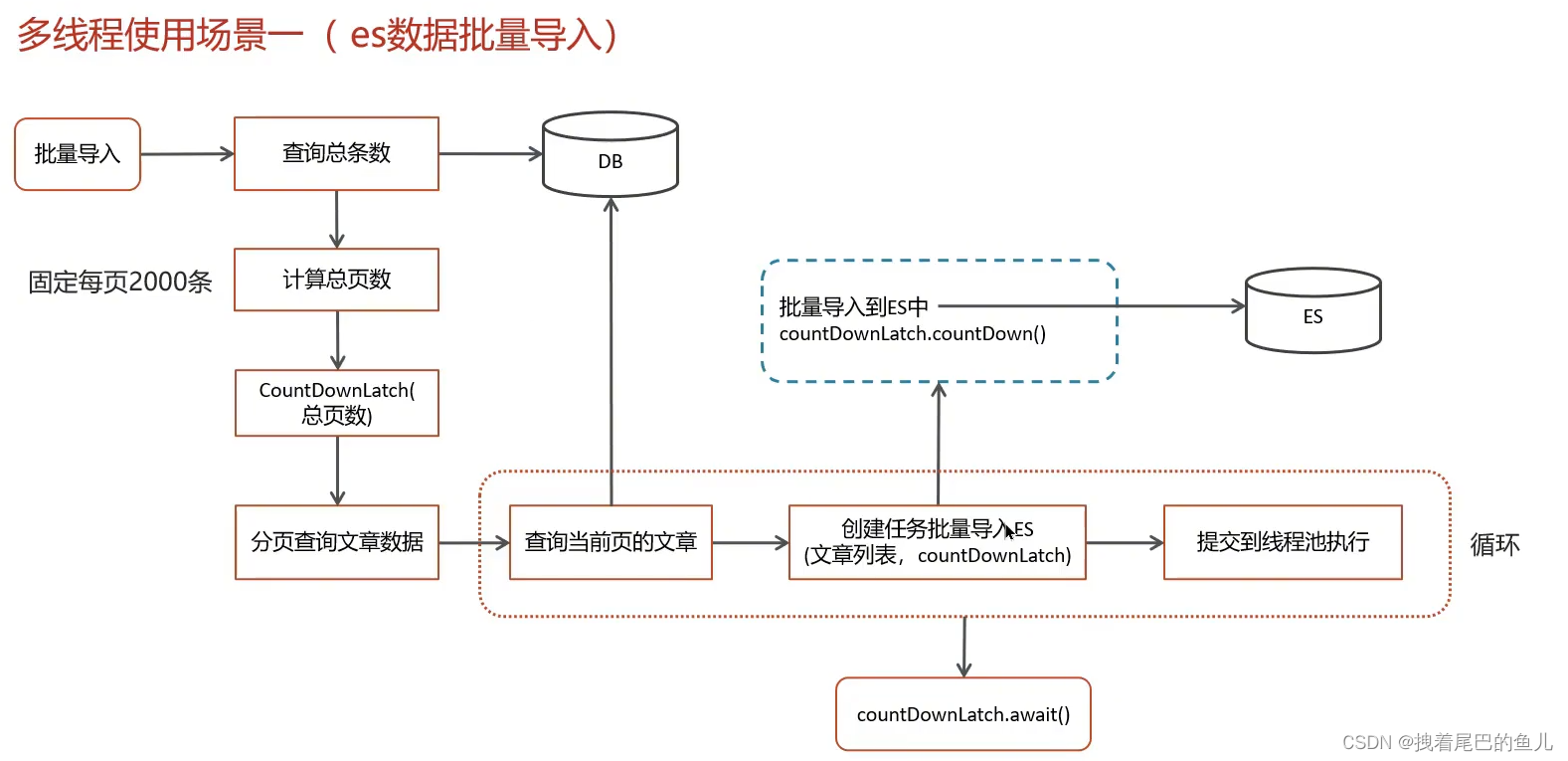
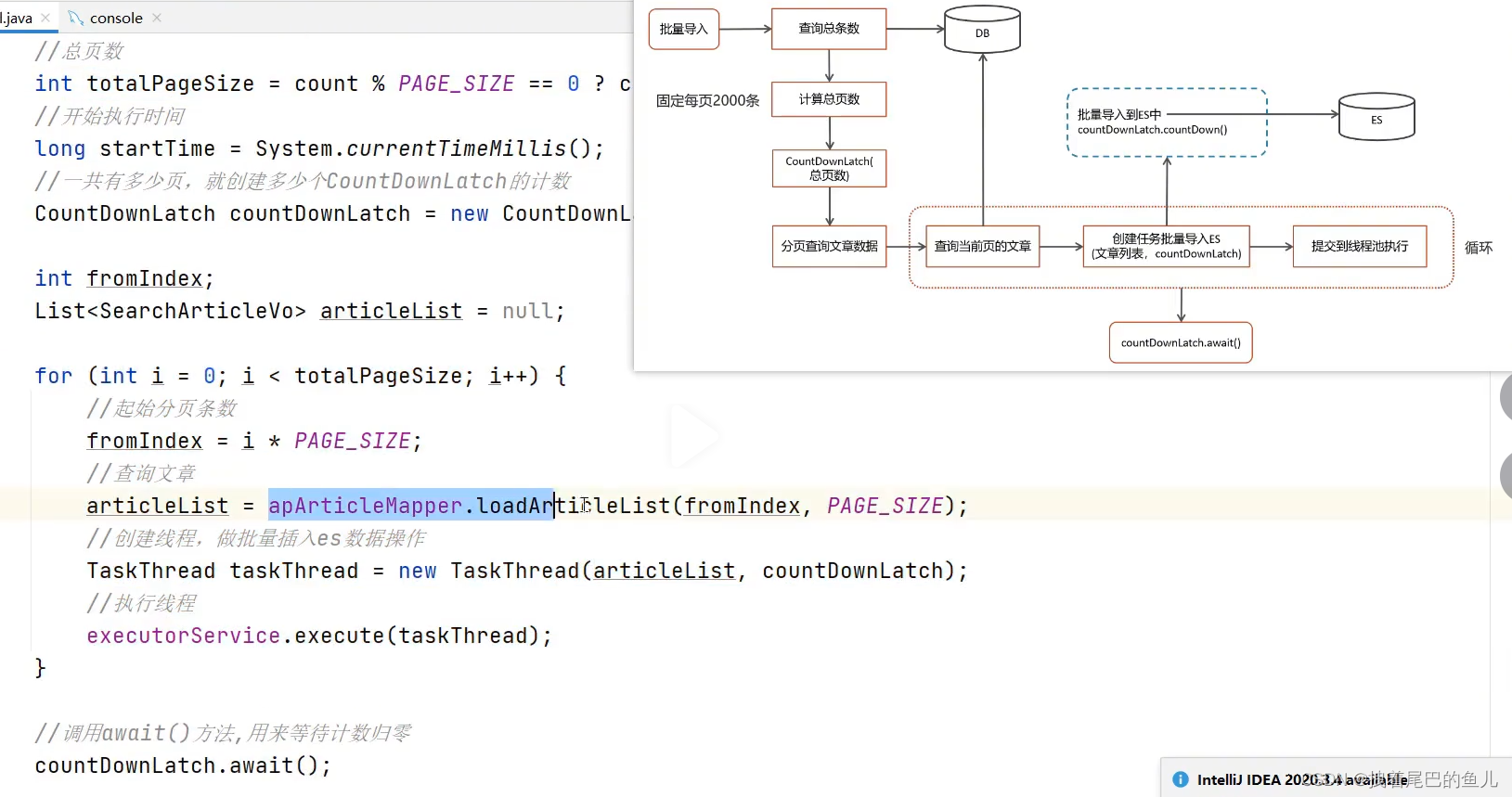
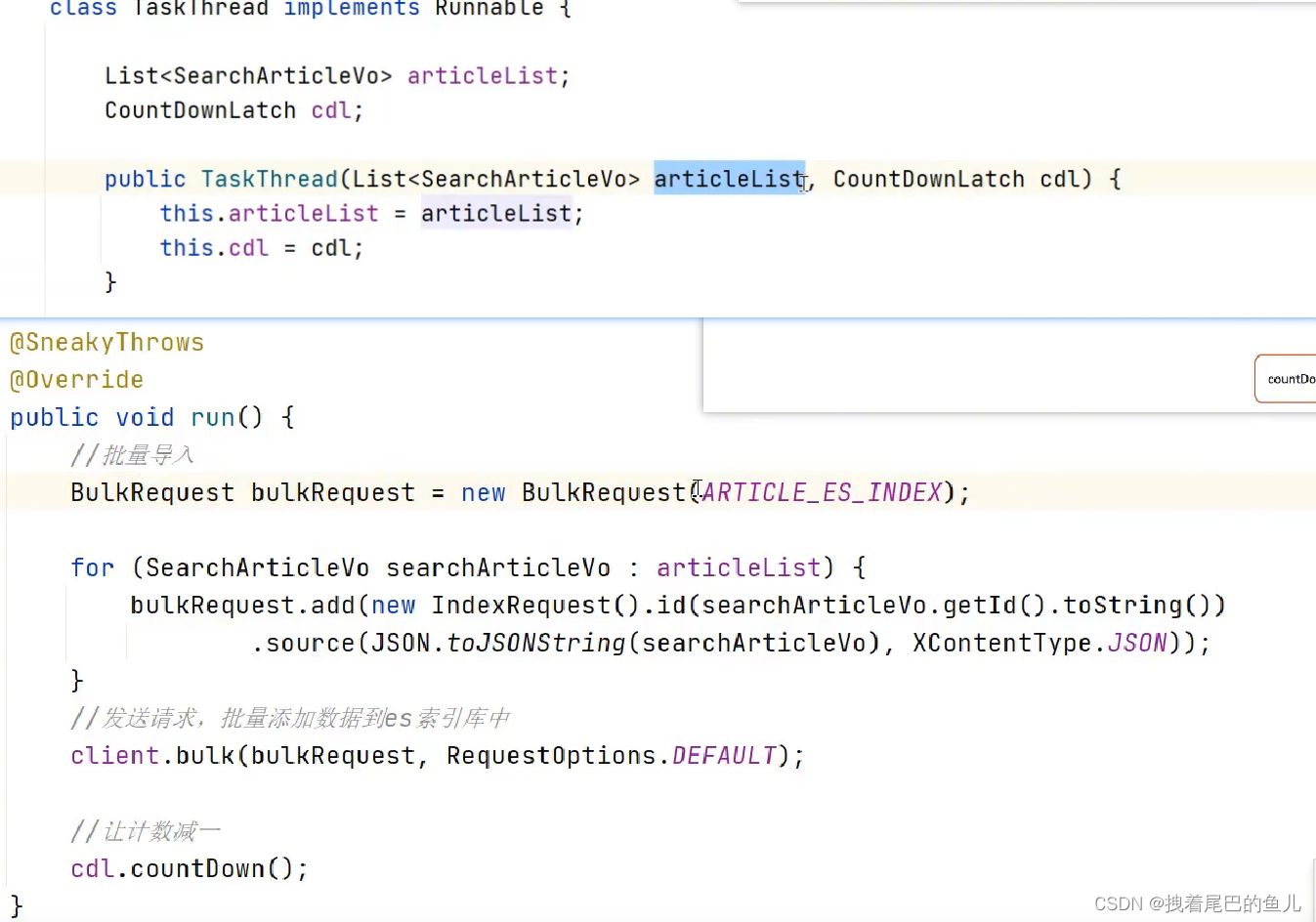
代码实现
1.3.2 多个线程并行执行分别进行数据统计,最后进行汇总
在一个电商网站中,用户下单之后,需要查询数据,数据包含了三部分:订单信息、包含的商品、物流信息;这三块信息都在不同的微服务中进行实现的,我们如何完成这个业务呢?
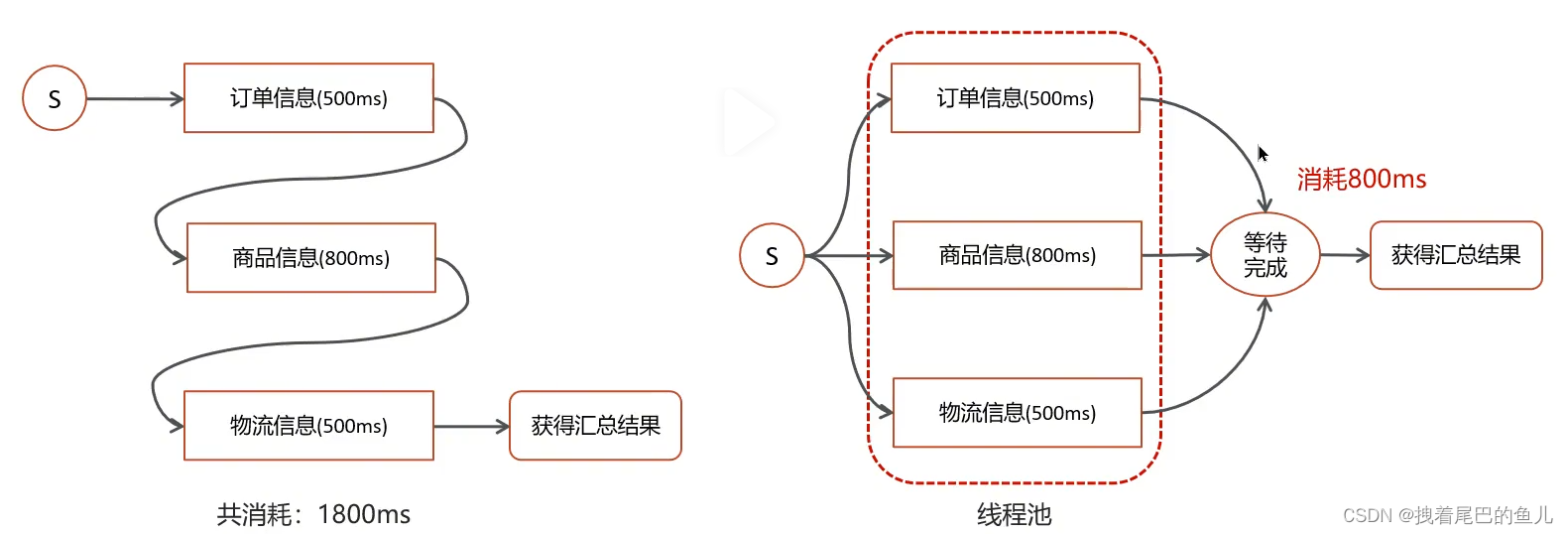
在实际开发的过程中,难免需要调用多个接口来汇总数据,如果所有接口(或部分接口)的没有依赖关系,就可以使用线程池+future来提升性能。
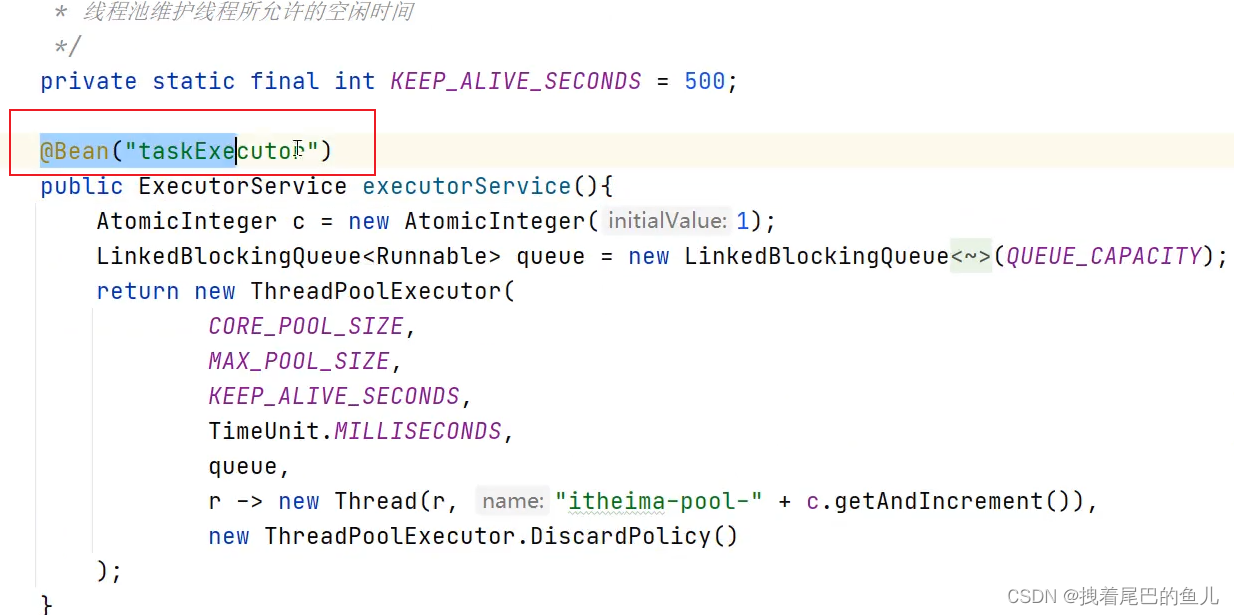
1.3.3 进行异步数据操作
启动类开启异步调用

定义线程池
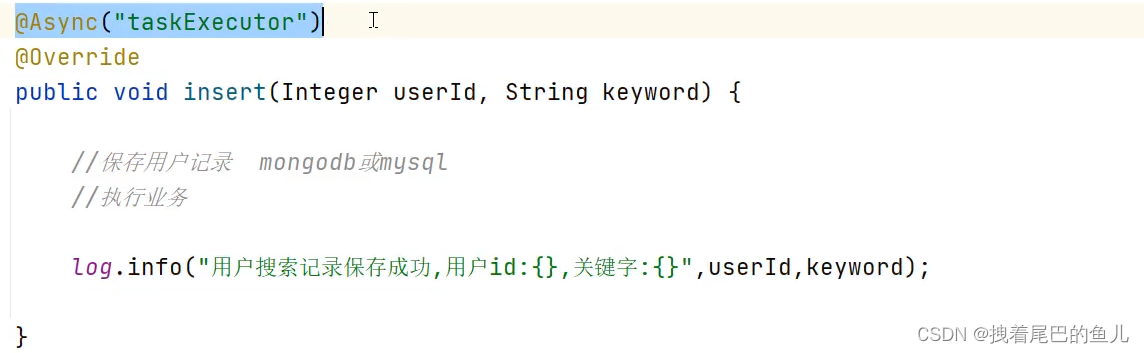
异步数据保存
二、你们项目中使用过ThreadLocal 吗,你知道它的原理吗
ThreadLocal是多线程中对于解决线程安全的一个操作类,它会为每个线程都分配一个独立的线程副本从而解决了变量并发访问冲突的问题。ThreadLocal同时实现了线程内的资源共享。
2.1 你们在哪些场景中用过ThreadLocal ?
在项目中我们在aop 进行接口访问情况统计的时候使用了ThreadLocal ,在方法被访问前 我们通过ThreadLocal 记录了当前方法改方法的用户信息,在后置方法中通过ThreadLocal 获取到了之前保存的用户访问记录对象,然后记录接口的耗时,然后交给线程池进行数据的记录。
2.2 你了解过ThreadLocal 的原理吗
ThreadLocal 内部实际上使用ThreadLocal Map 对当前线程数据进行保存;

ThreadLocal 的set 方法

ThreadLocal 的get 和remove 方法
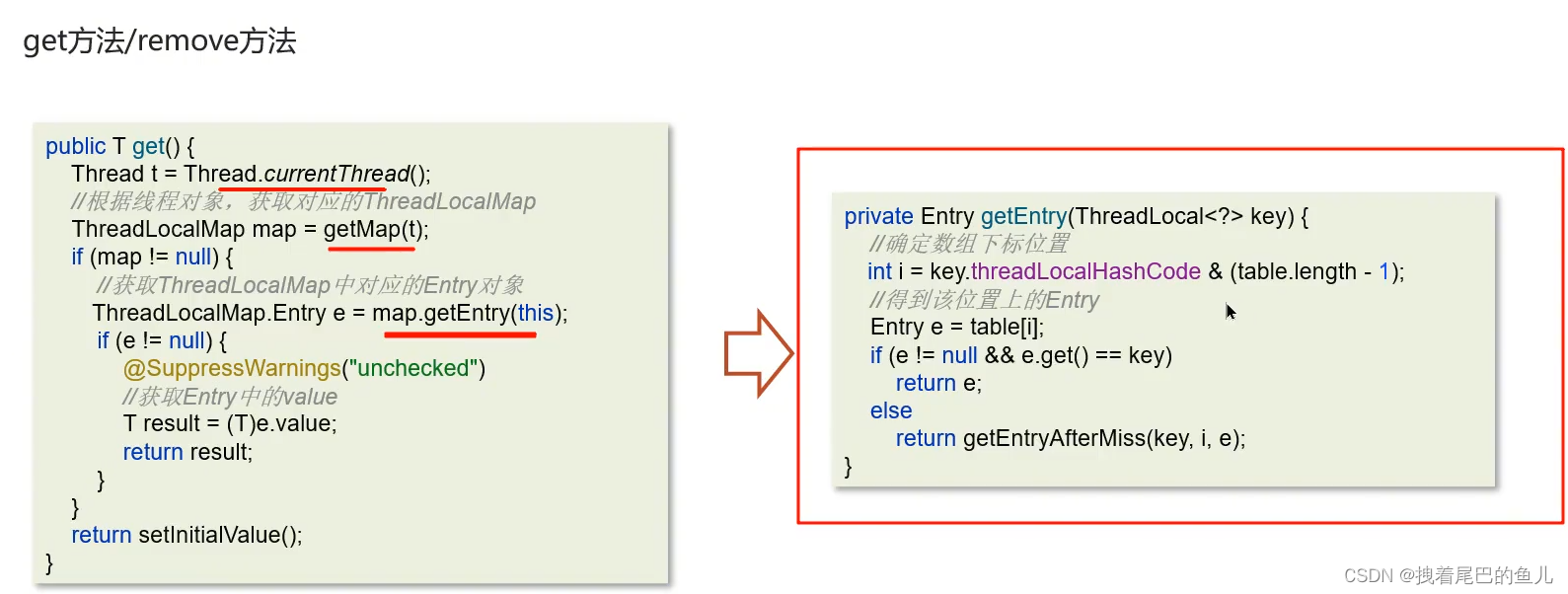

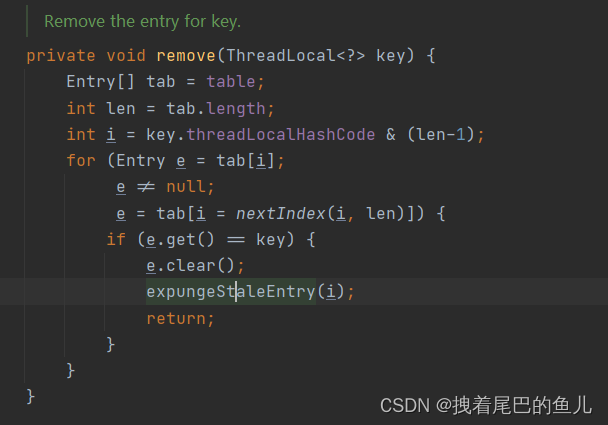
2.3 你知道ThreadLocal 的内存泄露吗
2.3.1 你知道Java 中的四种引用类型吗
Java对象中的四种引用类型:强引用、软引用、弱引用、虚引用
-
强引用:最为普通的引用方式,表示一个对象处于有用且必须的状态,如果一个对象具有强引用,则GC并不会回收它。即便堆中内存不足了,宁可出现OOM,也不会对其进行回收

-
软引用
软引用是用来描述一些还有用但并非必需的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行第二次回收。
如果这次回收还没有足够的内存,才会抛出内存溢出异常。 -
弱引用:表示一个对象处于可能有用且非必须的状态。在GC线程扫描内存区域时-旦发现弱引用,就会回收到弱引用相关联的对象。对于弱引用的回收,无关内存区域是否足够,一旦发现则会被回收

-
虚引用
虚引用也称为幽灵引用或者幻影引用,它是最弱的一种引用关系。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,
也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。
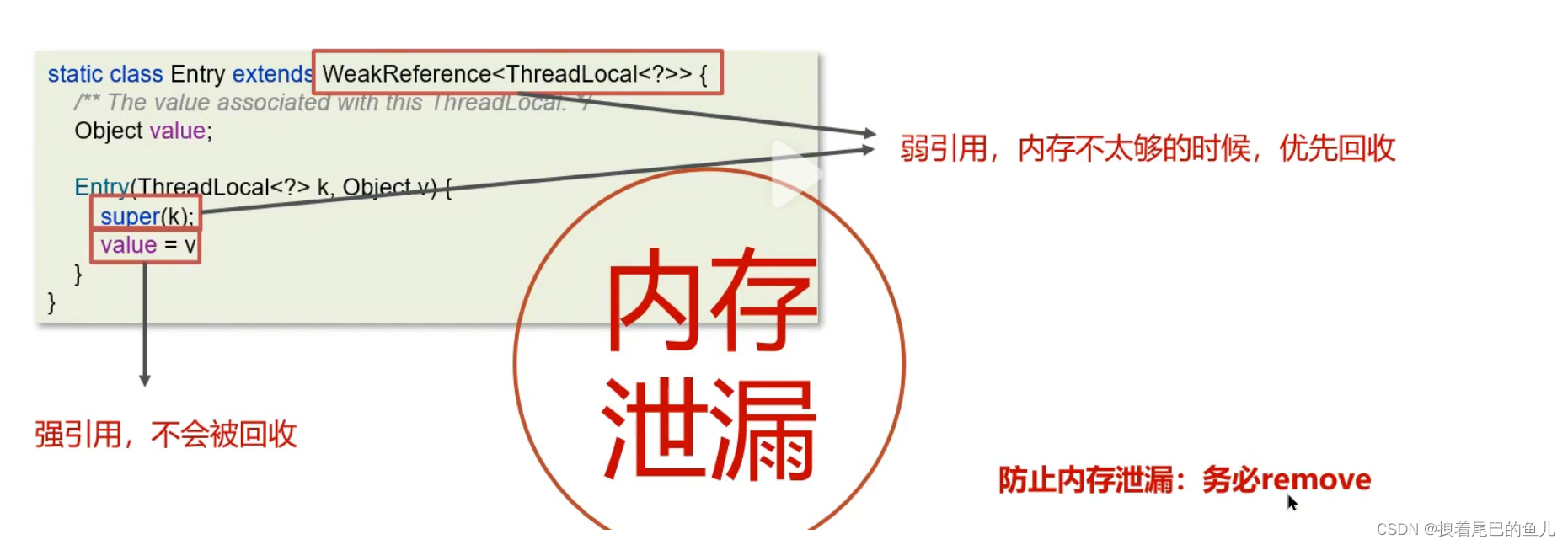
2.3.2 ThreadLocal 为什么会有内存泄露风险
每一个Thread维护一个ThreadLocalMap,在ThreadLocalMap中的Entry对象继承了WeakReference。其中key为使用弱引用的ThreadLocal实例,value为线程变量的副本。尤其是当我们使用线程池中的线程执行任务时,因为每个线程都会被分配多个任务,从而需要在ThreadLocalMap 保存多个ThreadLocal 对象,这样使用ThreadLocal Map 越来越大。
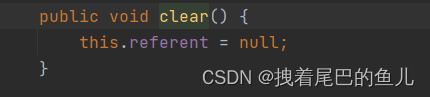
另外当改ThreadLocal 对象 已经没有被其它对象强引用时,此时entry 对象的key 是虚引用,在jvm每次进行垃圾回收时,都会回收弱引用的对象;但是,如果此时对应的value对象还有强引用(比如被其他对象引用),那么这个value对象就会成为“幽灵”数据,因为它已经无法通过ThreadLocal变量来访问了,但仍然占用着内存空间。如果这样的“幽灵”数据越来越多,就会导致内存泄漏。
应该在使用完ThreadLocal变量后及时调用remove()方法进行清理(将其对象的引用置为null),特别是在使用线程池的情况下。这样可以确保不会留下无用的key-value对在ThreadLocalMap中,从而避免内存泄漏和不必要的内存占用。
2.3.3 hreadLocalMap 中hash 冲突怎么处理
使用线性探索的方式,从当前index 下标的entry[] 数组依次向后遍历,如果达到了数组末尾还没有找到空缺的位置,此时下标位置会被置为0 继续进行遍历,插入后如果发现达到阈值(数组初始化长度为12,负载因子是0.75)进行数组长度2被的扩容.
2.3.3 说说你对ThreadLocal 的理解
- ThreadLocal 可以实现【资源对象】的线程隔离,让每个线程各用各的【资源对象避免争用引发的线程安全问题
- ThreadLocal 同时实现了线程内的资源共享
- 每个线程内有一个 ThreadLocalMap 类型的成员变量,用来存储资源对象
-
- a)调用 set 方法,就是以 ThreadLocal 自己作为 key,资源对象作为 value,放入当前线程的 ThreadLocalMap 集合中
-
- b)调用 get 方法,就是以 ThreadLocal自己作为 key,到当前线程中查找关联的资源值c)调用 remove 方法,就是以 ThreadLocal 自己作为 key,移除当前线程关联的资源值
- ThreadLocal内存泄漏问题
ThreadLocalMap 中的 key是弱引用,值为强引用;key 会被GC释放内存,关联 value的内存并不会释放。建议主动remove 释放 key,value。
总结
本文对线程池的定义,工作过程,ThreadLocal 的使用及其原理进行总结。















 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









