






第5章 类型系统
在前几章中我们介绍了Kotlin的许多特性,通过与Java比较,你应该能感受到它为开发者提供了非常多的帮助。在这些强大的特性背后,类型系统发挥了不可或缺的作用。本章我们会深入介绍Kotlin在类型系统方面的设计。Kotlin的类型系统可以看作Java的升级版,如增加了类型的可控性,使得开发工程变得更加安全可靠;通过引入Smart Casts特性,使得用Kotlin编写出的代码更加简洁优雅。同时,你也将了解到Kotlin在泛型层面针对Java的改良。
5.1 null引用:10亿美元的错误
“我把null引用称为10亿美元的错误。它发明于1965年,那时我用一个面向对象的语言(ALGOL W)设计了第一个全面的引用类型系统。”——托尼·霍尔(Tony Hoare)。
2009年3月,Tony Hoare在Qcon技术会议上发表了题为《null引用:代价10亿美元的错误》的演讲,回忆自己1965年设计第一个全面的类型系统时,未能抵御住诱惑,加入了null引用,仅仅是因为实现起来非常容易。它后来成为许多程序设计语言的标准特性,导致了数不清的错误、漏洞和系统崩溃,可能在之后40年中造成了10亿美元的损失。
5.1.1 null做了哪些恶
如果说类型系统描述了一系列规则,那么null就是类型系统的一个漏洞。null是一个不是值的值。它在不同语言中有着不同的名字:NULL、nil、null、None、Nothing、Nil和nullptr等。大家在使用Java进行开发时,难免会遇到各种异常,不过最令人头疼的莫过于臭名昭著的NullPointerException(NPE)。在数组里、集合中,以及几乎所有的场景中都有它的影子。
在深入了解Kotlin类型系统之前,我们先来重新了解一下null,为什么说它是个严重的错误。
1.null存在歧义
首先,我们必须承认的是,一个值为null可以代表很多含义,比如:
• 该值从未被初始化;
• 该值不合法;
• 该值不需要;
• 该值不存在。
很多时候,我们都需要用HashMap来保存一些数据,Java中的HashMap允许key为null。比如一个教室,我们将座位号与坐在上面的人保存到HashMap里。
HashMap<Long, String> map = new HashMap<>();
map.put(null, null);
map.put(1001L, "Yison");
map.put(1002L, "Jilen");同时,我们也会存入空座位的信息:
map.put(1003L, null);但当我们要获取这些空座位的信息时,返回的null则产生了歧义:
• 这个座位不存在;
• 这个座位上没人(信息为空)。
上述HashMap的接口并不能够精确地区分这两种情况(Java 8之前),并且,实际的业务会比以上复杂得多,这样的歧义很可能造成不易察觉的bug。
好在Java 8中新增了一些友好的接口public V getOrDefault(Object key,V defaultValue),我们可以通过指定defaultValue来区分上述情况。尽管如此,依旧有很多API存在上述类似的问题,这里不一一赘述,你可以自行探索。
2.难以控制的NPE
其次,就是我们熟知NullPointerException问题,它往往让我们编写的Java程序变得脆弱。静态类型语言在编译时期就能对程序中的类型做出检查。例如以下Java代码:
String str = "just haha";
System.out.println(str.length());
Date date = new Date();
System.out.println(date.length());编译器会检查出上述代码中length方法调用者的类型,在编译的时候就会给你一些友好的提示。但是对于Java,编译时检查存在一个致命缺陷——由于任何引用都可以是null,而调用一个null对象的方法,将产生NPE。
我们尝试将代码变为这样:
String str = "just haha";
str = null;
System.out.println(str.length());编译顺畅地通过了,然而当你的程序愉快地运行时,却产生了丑陋的NPE。很多其他语言的类型系统也有同样的缺点。在这些语言中,null悄悄地越过类型检查,等待运行时释放出一大批错误。
3.冗余的防御式代码
虽然在很多情况下null是没有意义的,但是当类型系统允许万物为null时,我们就不得不写下一些判空(null)代码:
if (str == null || str.equals("")) {
// Todo
}你是否发现了一些问题?我们总是将null与字符串为空混为一谈,这多少有些违背业务初衷。
Kotlin中的nonEmpty方法
一种比较推荐的做法:在Kotlin或Scala等语言中,通常用str.nonEmpty来进行判断,这在表达上具备了更好的语义化。
看了上述null的几个缺点,相信你也能推测到,null还会让代码调试工作也变得不容易。这时候你难免会产生疑问:既然null如此不好,我们为何不彻底废弃它?
正如上文提到,null在1965年就被创造出来了。后来的语言中大多数都沿用了null引用这种设计。然而,如果想要替换掉null,首先我们需要花费大量的精力更新以前的工程;其次,你需要想出更好的一个代号来代表“空”。这样新的问题就又出现了。
5.1.2 如何解决NPE问题
不得不承认的是,null确实为我们解决了许多问题,过重的历史包袱让我们没办法立刻摆脱它。事实上,我们也发现一些语言中已经在初步替代、划分null,比如引入一些新的类型(Empty、undefined),把类型分为可空和非空等。
既然不能被彻底取代,就必须勇敢地面对。对于防止NPE,当前Java中已经有如下几种解决方案:
1)函数内对于无效值,更倾向于抛异常处理。特别地,在Java里应该使用专门的自定义Checked Exception。不过这种方案,对于经常出现无效值的、有性能需求或在代码中经常使用的函数并不适用。对于自身可取空值的类型,比如说集合类型,通常返回零长度的数组或者集合,虽然这样做会多出内存的开销。
2)采用@NotNull/@Nullable标注。对于一段复杂的代码,检查参数是否为空是一件比较耗费时间的事情。对于不可为空的参数,我们可以尝试采用@NotNull来注解,明确参数是否可空,在模块入口就加以控制,避免非法的null值进一步传递。
3)使用专门的Optional对象对可能为null的变量进行装箱。这类Optional对象必须拆箱后才能参与运算,因而拆箱步骤就提醒使用者必须处理null值的情况。
5.2 可空类型
Kotlin提供了一种崭新的思路,来解决由null引发的问题,这就是在类型层面提供一种“可空类型”。在介绍它之前,我们先来回忆下Java 8中的Optional类。
5.2.1 Java 8中的Optional
如果你深入了解过Java 8,那么肯定熟悉它增加的java.util.Optional<T>。
我们举一个简单的例子。这里还是以学生和座位为例,一个座位上可能坐着学生,也可能没有;一个学生可能戴着眼镜,也可能没有。对于不确定是否存在的属性,我们就可以用Optional来封装。
public class Seat {
private Optional<Student> student;
public Optional<Student> getStudent() {
return student;
}
}
public class Student {
private Optional<Glasses> glasses;
public Optional<Glasses> getGlasses() {
return glasses;
}
}
public class Glasses {
private double degreeOfMyopia; // 近视度数
public double getDegreeOfMyopia() {
return degreeOfMyopia;
}
}以上,将学生(Student)、眼镜(Glasses)声明为Optional类型:
• 声明其类型为可空,更具有语义;
• 在使用可空属性时,更好地处理了NPE问题。
在眼镜类中,因为眼镜肯定存在度数,则把度数degreeOfMyopia声明为double类型,不需要强行为其套一层Optional。
上述数据类型的设计看起来已经挺不错了,那我们尝试来获取一下Optional的值。假设我们已经从数据库中读取到了座位的信息,我们想获取某个座位上学生的眼镜度数。看到Optional有一个判断值是否存在的方法isPresent(),我们可能会想当然地写出如下代码:
public double getDegreeOfMyopia(Optional<Seat> seat) {
if (seat.isPresent()
&& seat.get().getStudent().isPresent()
&& seat.get().getStudent().get().getGlasses().isPresent())
//座位存在,学生存在,眼镜存在
return seat.get().getStudent().get().getGlasses().get().getDegree OfMyopia();
else return 0.00;
}不知道你是否察觉到哪里不对劲?似乎不加Optional之前的方式更加简洁。
public double getDegreeOfMyopia(Seat seat) {
return seat!=null && seat.student!=null && seat.student.glasses!=null ? seat.student.glasses.degreeOfMyopia: 0.00;
}如果真是这样,那也太不优雅了!事实上,Optional提供了map、flatMap、filter等方法,帮助我们从对象中提取信息。
提示
如果你不熟悉map、flatMap、filter,可以去了解一下Java Stream相关知识。于是,常见的代码应该是这样的:
public double getDegreeOfMyopia(Optional<Seat> seat) {
return seat.flatMap(Seat::getStudent)
.flatMap(Student::getGlasses)
.map(Glasses::getDegreeOfMyopia)
.orElse(0.00);
}除了获取数据很优雅以外,Optional还给我们提供了处理数据的机会——能在flatMap、map中对数据进行处理——这对传统的null来说肯定少不了嵌套大量的if-else。
注意
Optional也提供OptionalInt、OptionalLong及OptionalDouble,虽然字面上与Optional<Integer>类似,但是我们不推荐使用这些基础类型的Optional:它并不支持map、flatMap、filter方法,并且它们在序列化的时候会出现问题。引入它们可能仅仅只是为了避免自动装箱。
一切看起来都那么美好,甚至你是不是都想把书放在一边,准备去修改一下之前那些不堪入目的代码了呢?别急,如果你的应用对性能有着严格要求的话,请继续往下看。
我们给上述代码加上非Optional参数的类,加以测试:
public class StudentOld {
private Glasses glasses;
// ...省略get/set以及构造函数
}
public class SeatOld {
private StudentOld student;
// ...省略get/set以及构造函数
double getDegreeOfMyopiaOld(SeatOld seat) {
double result = 0.00;
if (seat != null && seat.student!=null && seat.student.getGlasses()!=null) result = seat.student.getGlasses().getDegreeOfMyopia();
return result;
}
}运行一下测试用例:
public static void main(String[] args) {
// 创建seat实例
Seat seat = ...
// 创建seat实例
SeatOld seatOld = ...
Long before = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
seat.getDegreeOfMyopiaA(Optional.of(seat));
}
System.out.println("Optional调用消耗时间: " + (System.currentTimeMillis() - before) + "毫秒");
Long before2 = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
seatOld.getDegreeOfMyopiaOld(seatOld);
}
System.out.println("原始调用消耗时间: " + (System.currentTimeMillis() - before2) + "毫秒");
}多次测试发现,Optional的耗时大约是普通判空的数十倍。这主要是因为Optional<T>是一个包含类型T引用的泛型类,在使用的时候多创建了一次对象,当数据量非常大的时候,频繁地实例化对象会造成性能损失。如果未来Java支持了值类(value class),这些开销将会不复存在。
5.2.2 Kotlin的可空类型
上节花了一些篇幅介绍Java 8中的Optional<T>,虽然它能够应对绝大多数的场景,却依旧存在一些看起来不够好的地方。有趣的是,在阅读一些开源代码时,你会发现Optional并没有被大范围使用(具体原因将在下面介绍)。
然而,在Kotlin中处理NPE问题非常容易,这也是Kotlin生态圈越来越强壮的原因之一。
在前面的章节中提到过,与Java不同,Kotlin可区分非空(non-null)和可空(nullable)类型。举个例子回顾一下:
// Java
Long x = null;
// Kotlin
val x:Long = null;在Java里我们可以给一个变量初始化为null,所以Optional类型的变量也可能为null。但是在Kotlin中,这在编译时就会报错:Error:Null cannot be a value of a non-null type Long。
这意味着在Kotlin中访问非空类型的变量将永远不会抛出空指针异常。既然Kotlin不存在Optional<T>这样的类,那如何表示可空类型呢?在Kotlin中,我们可以在任何类型后面加上“?”,比如“Int?”,实际上等同于“Int?=Int or null”。通过合理的使用,不仅能够简化很多判空代码,还能够有效避免空指针异常。
注意
由于null只能被存储在Java的引用类型的变量中,所以在Kotlin中基本数据的可空版本都会使用该类型的包装形式。同样,如果你用基本数据类型作为泛型类的类型参数,Kotlin同样会使用该类型的包装形式。
让我们先来把之前座位(Seat)-学生(Student)-眼镜(Glasses)的例子用Kotlin改写一下:
data class Seat(val student: Student?)//?表示可为空
data class Student(val glasses: Glasses?)
data class Glasses(val degreeOfMyopia: Double)1.安全的调用?.
同样举上面的例子。如果我们想知道一个座位上学生的眼镜度数,以前用Java会这么写:
if(seat.student != null) {
if (seat.student.glasses != null) {
System.out.println("该位置上学生眼镜度数:" + seat.student.glasses.degreeOfMyopia)
}
}而在Kotlin中可以这样写:
println("该位置上学生眼镜度数:${s.student?.glasses?.degreeOfMyopia}")这里的“?.”我们可以将其称作安全调用。当student存在时,才会调用其下的glasses。
2.Elvis操作符?:
假设座位上有学生,如果不戴眼镜,眼镜度数为-1。在Java中,我们会利用三目运算符,如下所示:
double result = student.glasses != null ? student.glasses.degreeOfMyopia :-1Kotlin中也有类似的运算符,但是它是类型安全版本的:
val result = student.glasses?.degreeOfMyopia?:-1以上的运算符我们称为Elvis操作符,或者合并运算符。
3.非空断言!!.
Java程序员在测试的时候经常会使用Assert来保证某个变量不为空。Kotlin中为你提供了另一种选择,如果我们在测试的时候想确保一个学生是戴眼镜的:
val result = student!!.glasses当这个学生不戴眼镜时,程序就会抛出NPE的异常。除此之外还有“!is”“as?”等运算符,这里不过多介绍。
对比Java版本,Kotlin的代码精简程度很高,但是简洁的背后一般都不简单。上节中我们提到过,目前解决NPE问题一般有3种方式:
• 用try catch捕获异常。
• 用Optional<T>类似的类型来包装。
• 用@NotNull/@Nullable注解来标注。
那Kotlin的可空对应的是那种方案呢?
4.Kotlin如何实现类型的可空性
我们利用IDEA的反编译工具,可以查看Kotlin相对应的Java代码。以getDegreeOf MyopiaKt(seat:Seat?)方法为例:
public final double getDegreeOfMyopiaKt(@Nullable Seat seat) {
double var3;
if(seat != null) {
Student var10000 = seat.getStudent();
if(var10000 != null) {
Glasses var2 = var10000.getGlasses();
if(var2 != null) {
var3 = var2.getDegreeOfMyopia();
return var3;
}
}
}
var3 = 0.0D;
return var3;
}我们发现Kotlin在方法参数上标注了@Nullable,在实现上,依旧采用了if..else来对可空情况进行判断。这么做的原因很可能是:
• 兼容Java老版本(兼容Android);
• 实现Java与Kotlin的100%互转换;
• 在性能上达到最佳。
5.T?与Optional的差异
看完上述内容,我们应该都知道,Kotlin的可空类型实质上只是在Java的基础上进行了语法层面的包装,我们可以将Kotlin可空类型的性能看成与Java近似一致,所以其性能上优于Java 8中的Optional是毋庸置疑的。
另外,Optional实质上是一种新的类型,这与Kotlin可空类型不同。我们在使用的时候,你是想写Optional<T>还是“T?”呢?上面的例子其实也完美解释了这个问题:Kotlin的可空类型更加精练。
总而言之,Kotlin可空类型优于Java Optional的地方体现在:
• Kotlin可空类型兼容性更好;
• Kotlin可空类型性能更好、开销更低;
• Kotlin可空类型语法简洁。
6.用Either代替可空类型
光有“T?”就足够了吗?以上例子避开了null的情况,并且在设置默认值的情况下,我们可能无法区分出程序是否出错。如何才能获取到这个异常呢?
Kotlin中也有try..catch..finally,用它我们可以轻松地捕获异常。需要注意的是,
fun getDegreeOfMyopiaKt(seat: Seat?): Either<Error, Double> {
return seat?.student?.glasses?.let { Either.Right<Error, Double>(it.degreeOfMyopia) } ?: Either.Left<Error, Double>(Error(code=-1))
}忽略异常并不总是一种好的做法。
如果需要让程序抛出异常,我们可以结合Elvis操作符:
seat?.student?.glasses?.degreeOfMyopia ?: throw NullPointerException("some reasons")上述两种方案都不是非常优雅。如果你熟悉Scala,会比较自然地想到用Either[A,B]来解决。
Either的子类型
Either只有两个子类型:Left、Right,如果Either[A,B]对象包含的是A的实例,那它就是Left实例,否则就是Right实例。
通常来说,Left代表出错的情况,Right代表成功的情况。
Kotlin虽然没有Either类,但是我们可以通过密封类便捷地创造出Either类:
sealed class Either<A,B>() {
class Left<A,B>(val value: A): Either<A,B>()
class Right<A,B>(val value: B) : Either<A,B>()
}我们就可以利用Either将程序改造为:
fun getDegreeOfMyopiaKt(seat: Seat?): Either<Error, Double> {
return seat?.student?.glasses?.let { Either.Right<Error, Double>(it.degreeOfMyopia) } ?: Either.Left<Error, Double>(Error(code=-1))
}let的概念
定义:public inline fun<T,R>T.let(block:(T)->R):R=block(this)
功能:调用某对象的let函数,该对象会作为函数的参数,在函数块内可以通过it指代该对象。返回值为函数块的最后一行或指定return表达式。
也许你会疑惑,这样写起来代码不是变多了吗?是
这样,没错。但是正如上一章所提及的,我们需要用ADT良好地组织业务。在获取数据时,我们往往是经过多个方法逐步获取,最后整合在一起。定义一个Error类,将所有步骤中的错误都抽象为不同的子类型,便于最终的处理以及后期排查错误,何乐而不为。如果我们不这么做,只是隐藏了潜在的异常,调用者通常会忽略可能发生的错误,这是很危险的设计。在第10章中,我们会详细介绍异步过程中的数据异常处理。
5.2.3 类型检查
在开发的时候,我们会接触非常多类型,难免需要判断一个对象是什么类型。在Java中,一般使用A instanceof T来判断A是T或者T的子类的一个实例。而在Kotlin中,我们可以用“is”来判断。这里借用官方文档的例子:
if (obj is String) {
print(obj.length)
}
if (obj !is String) { // 等同于 !(obj is String)
print("Not a String")
} else {
print(obj.length)
}还记得上一章介绍的增强版的switch—when表达式吗?利用它我们可以让代码变得更优雅:
when (obj) {
is String -> print(obj.length)
!is String -> print("Not a String")
}这里的obj为Any类型,虽然做了类型判断,但在没有类型转换的情况下,我们使用了String的方法length。是不是上述代码写错了?
其实,是Kotlin中的智能转换(Smart Casts)帮我们省略了一些工作。
5.2.4 类型智能转换
Smart Casts可以将一个变量的类型转变为另一种类型,它是隐式完成的。举个例子:
val stu: Any = Student(Glasses(189.00))
if(stu is Student) println(stu.glasses)如果在Java中,我们还需要将stu的类型做强制转换,方可调用其属性:
Object stu = Student(Glasses(189.00))
if(stu instanceof Student) System.out.println(((Student)stu).glasses)同样,对于可空类型,我们可以使用Smart Casts:
val stu: Student = Student(Glasses(189.00))
if (stu.glasses != null) println(stu.glasses.degreeOfMyopia)你一定会想知道Kotlin是怎么做到的。我们将第一个例子反编译成Java,核心代码如下:
...
Intrinsics.checkParameterIsNotNull(args, "args");
Student stu = new Student(new Glasses(189.0D));
if(stu instanceof Student) {
Glasses var2 = ((Student)stu).getGlasses();
System.out.println(var2);
}
...我们可以看到,这与我们写的Java版本一致,这其实是Kotlin的编译器帮我们做出了转换。根据官方文档介绍:当且仅当Kotlin的编译器确定在类型检查后该变量不会再改变,才会产生Smart Casts。利用这点,我们能确保多线程的应用足够安全。举个例子:
class Kot {
var stu: Student? = getStu()
fun dealStu() {
if (stu != null) {
print(stu.glasses)
}
}
}上述代码中,我们将stu声明为引用可变变量,这意味着在判断(stu!=null)之后,stu在其他线程中还是会被修改的,所以被编译器无情地拒绝了。
将var改为val就不会存在这样的问题,引用不可变能够确保程序运行不产生额外的副作用。我们可以用let函数来简化一下:
class Kot {
var stu: Student? = getStu()
fun dealStu() {
stu?.let { print(it.glasses) }
}
}在实际开发中,我们并不总能满足Smart Casts的条件。并且Smart Casts有时会缺乏语义,并不适用于所有场景。当类型需要强制转换时,我们可以利用“as”操作符来实现。还记得之前Smart Casts失败的例子吗:
// 编译出错
class Kot {
var stu: Student? = getStu()
fun dealStu() {
if (stu != null) {
print(stu.glasses)
}
}
}那我们是否能用as来拯救它?我们尝试做如下修改:
class Kot {
var stu: Student? = getStu() as Student?
fun dealStu() {
if (stu != null) {
print(stu.glasses)
}
}
}这样,我们在外部已经确定了stu的类型,当stu不为空时,在dealStu成员方法里就可以成功调用stu的参数。因为getStu可能为空,如果我们将转换类型改为Student:
var stu: Student? = getStu() as Student则会抛出类型转换失败的异常,因为它不是可空的。所以,我们通常称之为“不安全”的类型转换。那是否有安全版本的转换呢?除了上述写法外,Kotlin还提供了操作符“as?”,利用它我们可以这样改写:
var stu: Student? = getStu() as? Student这时,如果stu为空将不会抛出异常,而是返回转换结果null。
除此之外,我们可能在某些业务下需要频繁地进行类型转换,所以会配合泛型封装一个更“有效的”类型转换方法:
fun <T> cast(original: Any): T? = original as? T观察以上代码,我们的目标是将任意不为空的类型转为目标类型T,因为可能转换失败,所以返回类型为“T?”。我们可以这样使用:
val ans = cast<String>(140163L)代码看起来挺合理的,但是在调用的时候却出现了意料之外的结果:
Exception in thread "main" java.lang.ClassCastException: java.lang.Long cannot be cast to java.lang.String… 其实,这是类型擦除造成的影响。如果你使用一些比较智能的IDEA,在编写代码时你就会看到类似“Warning:Unchecked cast:Any to T”这样的警告。Kotlin的设计者们同样注意到了这点,他们加入了关键字reified,我们可以将之理解为“具体化”,利用它我们可以在方法体内访问泛型指定的JVM类对象(注意,还需要在方法前加入inline修饰)。
inline fun <reified T> cast(original: Any): T? = original as? T这样,我们就可以顺利地使用了。关于类型擦除,我们将在5.5节详细介绍。
5.3 比Java更面向对象的设计
关于面向对象,我们在第3章已经做了详细的介绍。在“纯面向对象”或“完全面向对象”的语言中,应该把程序里所有东西都视作对象。提到纯面向对象语言,也许你会先想到SmallTalk,它就是一门纯面向对象的编程语言。那么,Kotlin是一门纯面向对象的语言吗?
我们都知道,Java并不能在真正意义上被称作一门“纯面向对象”语言,因为它的原始类型(如int)的值与函数等并不能视作对象。
但是Kotlin不同,在Kotlin的类型系统中,并不区分原始类型(基本数据类型)和包装类型,我们使用的始终是同一个类型。虽然从严格意义上,我们不能说Kotlin是一门纯面向对象的语言,但它显然比Java有更纯的设计。
接下来,让我们一起来看看Kotlin的类型结构,如图5-1所示。
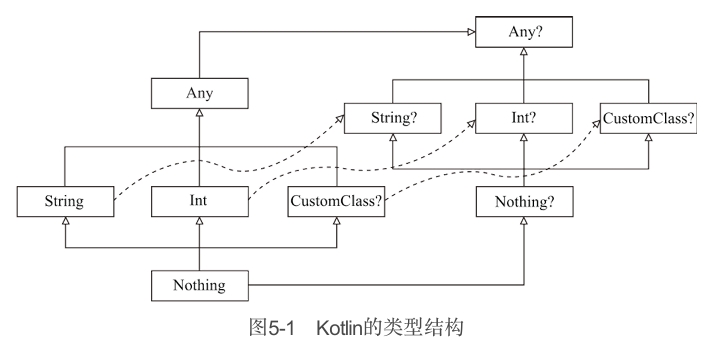
需要注意的是,以上的类型结构中省略了除String、Int之外的一些原生类型,比如Double、Long等。
5.3.1 Any:非空类型的根类型
与Object作为Java类层级结构的顶层类似,Any类型是Kotlin中所有非空类型(如String、Int)的超类,如图5-2所示。
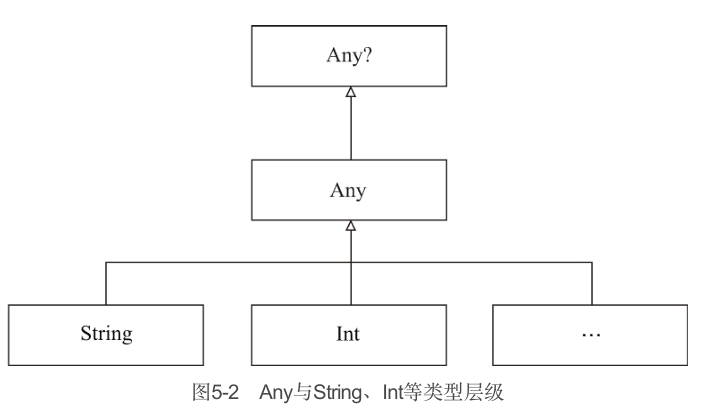
与Java不同的是,Kotlin不区分“原始类型”(primitive type)和其他的类型,它们都是同一类型层级结构的一部分。
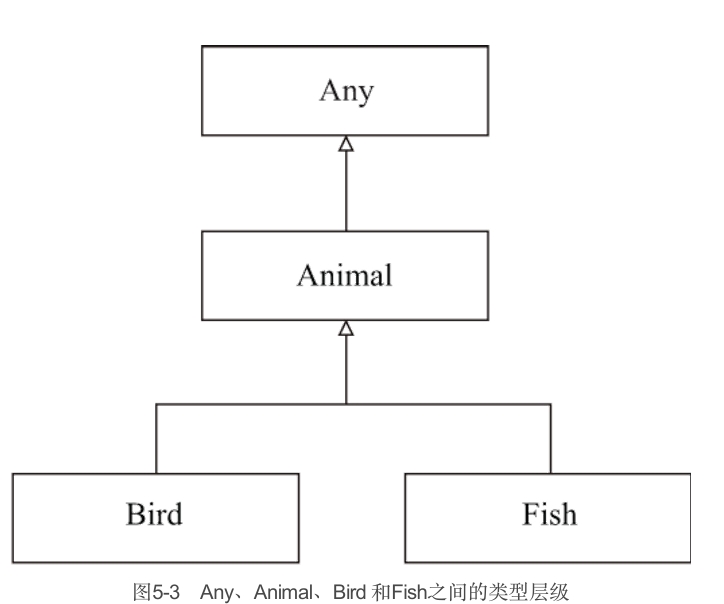
如果定义了一个没有指定父类型的类型,则该类型将是Any的直接子类型。如:
class Animal(val weight: Double)如果你为定义的类型指定了父类型,则该父类型将是新类型的直接父类型,但是新类型的最终根类型为Any。
abstract class Animal(val weight: Double)
class Bird(weight: Double, val flightSpeed: Double): Animal(weight)
class Fish(weight: Double, val swimmingSpeed: Double): Animal(weight)它们之间的类型层级关系如图5-3所示。
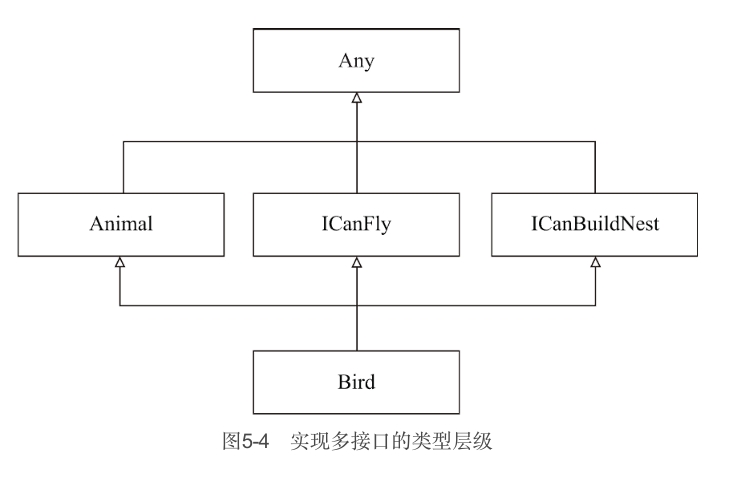
如果你的类型实现了多个接口,那么它将具有多个直接的父类型,而Any同样是最终的根类型。
interface ICanFly
interface ICanBuildNest
class Bird(weight: Double, flightSpeed: Double): Animal(weight), ICanFly, ICanBuildNest该情况的类型层级关系如图5-4所示。
Kotlin的Type Checker强制检查了父子关系。例如,你可以将子类型值存储到父类型变量中:
var f: Animal = Bird(weight = 0.1, flightSpeed = 15.0)
f = Fish(weight = 0.15, swimmingSpeed = 10.0)但是你不能将父类型值存储到子类型变量中:
val b = Bird(weight = 0.1, flightSpeed = 15.0)
val f: Animal = b
val b2: Bird = f
// Error: Type mismatch: inferred type is Animal but Bird was expected这正好也符合我们的日常理解:“鸟类是动物,而动物不是鸟类。”
另外,Kotlin把Java方法参数和返回类型中用到的Object类型看作Any(更确切地说是当作“平台类型”)。当在Kotlin函数中使用Any时,它会被编译成Java字节码中的Object。
什么是平台类型?
平台类型本质上就是Kotlin不知道可空性信息的类型,所有Java引用类型在Kotlin中都表现为平台类型。当在Kotlin中处理平台类型的值的时候,它既可以被当作可空类型来处理,也可以被当作非空类型来操作。
平台类型的引入是Kotlin兼容Java时的一种权衡设计。试想下,如果所有来自Java的值都被看成非空,那么就容易写出比较危险的代码。反之,如果Java中的值都强制当作可空,则会导致大量的null检查。综合考量,平台类型是一种折中的设计方案。
5.3.2 Any?:所有类型的根类型
如果说Any是所有非空类型的根类型,那么Any?才是所有类型(可空和非空类型)的根类型。这也就是说,?Any?是?Any的父类型。为什么会是这样呢?
一个看似容易实则不简单的问题是,到底什么才是子类型化(Subtyping)?如果你只有Java这门编程语言的开发经验,很容易陷入一个误区:继承关系决定父子类型关系。因为在Java中,类与类型大部分情况下都是“等价”的(在Java泛型出现前)。
事实上,“继承”和“子类型化”是两个完全不同的概念。子类型化的核心是一种类型的替代关系,可表示为:
S <: T以上S是T的子类,这意味着在需要T类型值的地方,S类型的值同样适用。如在Kotlin中Int是Number的子类:
fun printNum(num: Number) {
println(num)
}
>>> val n: Int = 1
>>> printNum(n)
>>> 1
>>> printNum("I am a String")
error: type mismatch: inferred type is String but Number was expected作为比较,继承强调的是一种“实现上的复用”,而子类型化是一种类型语义的关系,与实现没关系。部分语言如Java,由于在声明父子类型关系的同时也声明了继承的关系,所以造成了某种程度上的混淆。
虽然Any与Any?看起来没有继承关系,然而在我们需要用Any?类型值的地方,显然可以传入一个类型为Any的值,这在编译上不会产生问题。反之却不然,比如一个参数类型为Any的函数,我们传入符合Any?类型的null值,就会出现如下的错误:
error: null can not be a value of a non-null type Any因此,我们可以很大胆地说,Any?是Any的父类型,而且是所有类型的根类型,虽然当前的Kotlin官网文档没有介绍过这一点。
Any?与Any??
如果Any?是Any的父类型,那么Any??是否又是Any?的父类型?如果成立,那么是否意味着就没有所谓的所有类型的根类型了?
其实,Kotlin中的可空类型可以看作所谓的Union Type,近似于数学中的并集。如果用类型的并集来表示Any?,可写为Any∪Null。相应的Any??就表示为Any∪Null∪Null,等价于Any∪Null,即Any??等价于Any?。因此,说Any?是所有类型的根类型是没有问题的。
5.3.3 Nothing与Nothing?
在Kotlin类型层级结构的最底层是Nothing类型。在加入Nothing类型之后,以上我们讨论的类型结构如图5-5所示。
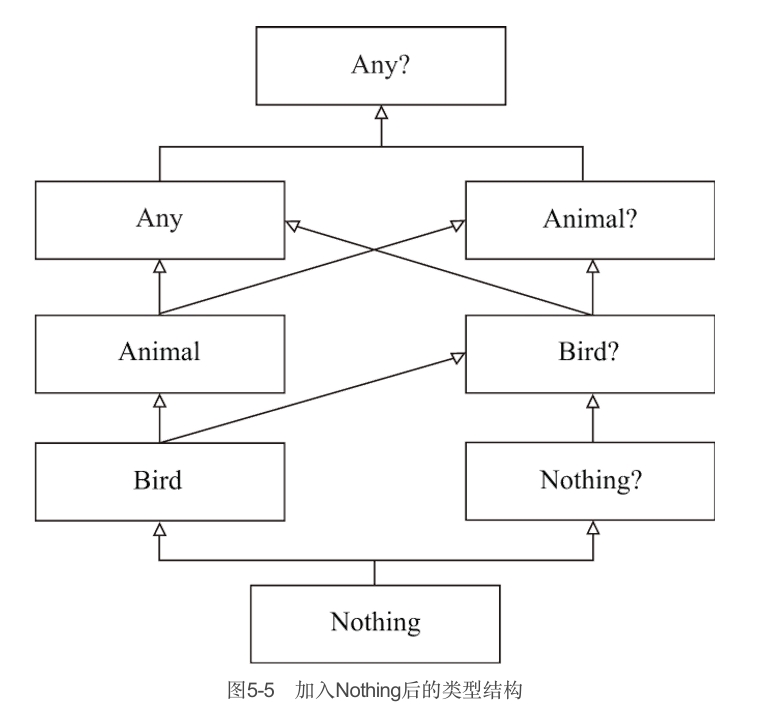
顾名思义,Nothing是没有实例的类型。Nothing类型的表达式不会产生任何值。需要注意的是,任何返回值为Nothing的表达式之后的语句都是无法执行的。你是不是感觉这有点像return或者break的作用?没错,Kotlin中return、throw等(流程控制中与跳转相关的表达式)返回值都为Nothing。
与Nothing对应的Nothing?,我们从字面上翻译可能会解释为:可空的空。与Any、Any?类似,Nothing?是Nothing的父类型,所以Nothing处于Kotlin类型层级结构的最底层。
其实,它只能包含一个值:null,本质上与null没有区别。所以我们可以使用null作为任何可空类型的值。
5.3.4 自动装箱与拆箱
介绍完顶层与底层类型,让我们来看看中间的类型。我
们发现,Kotlin中并没有int、float、double、long这样的原始类型,取而代之的是它们对应的引用类型包装类Int、Float、Double、Long。
除了以上代表数值的类型,还有布尔(Boolean)、字符(Char)、字符串(String)及数组(Array)。这让Kotlin比起Java来更加接近纯面向对象的设计——一切皆对象。
但这么说其实也是不够严谨的。以Int为例,虽然它可以像Integer一样提供额外的操作函数,但这两个类型在底层实现上存在差异。先来看一段代码:
val x1: Int = 18 // Kotlin
int x2 = 18; // Java
Integer x3 = 18; // Java借助IDEA我们可以看到Kotlin编译后的字节码分别是:
BIPUSH 18
ISTORE 1
bipush 18
istore_1
bipush 18
invokestatic #2 <java/lang/Integer.valueOf>
astore_1观察以上结果,我们发现:Kotlin中的Int在JVM中实际以int存储(对应字节码类型为I)。但是,作为一个“包装类型”,编译后应该装箱才对(以上代码中我们可以看到Java通过调用静态方法java/lang/Integer.valueOf来进行装箱)。
难道,Kotlin不会自动装箱?
装箱与拆箱的含义
自动装箱基本类型自动转为包装类,自动拆箱指包装类自动转为基本类型。
别着急下结论,你还记得可空类型吗?我们来看看Int?的字节码:
val x4: Int? = 18
// 对应字节码
BIPUSH 18
INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer;
ASTORE 1我们可以简单地认为:
• Kotlin中的Int类型等同于int;
• Kotlin中Int?等同于Integer。
Int作为一种小技巧,让Int看起来是引用类型,这在语法上让Kotlin更接近纯面向对象语言。
5.3.5 “新”的数组类型
数组是类型系统不可或缺的一部分,它在我们处理数据时提供了很多便利。相信你们一定很熟悉Java的数组,其在创建时通常使用一种简洁的写法。然后,我们就可以通过遍历、下标或Arrays里的方法来对funList进行修改。Kotlin中抛弃了这种C/C++风格的写法,我们可以这样创造数组:
val funList = arrayOf() // 声明长度为0的数组
val funList = arrayOf(n1, n2, n3..., nt) // 声明并初始化长度为t的数组 [插图]Kotlin中Array并不是一种原生的数据结构,而是一种Array类,甚至我们可以将Kotlin中的Array视作集合类的一部分。
由于Smart Casts,编译器能够隐式推断出funList元素类型。当然,我们也可以手动指定类型:
val funList = arrayOf<T>(n1, n2, n3..., nt)在Kotlin中,还为原始类型额外引入了一些实用的类:IntArray、CharArray、ShortArray等,分别对应Java中的int[]、char[]、short[]等。
与array类似,我们可以这样定义原始类型的数组:
注意
IntArray等并不是Array的子类,所以用两者创建的相同值的对象,并不是相同对象。
由于Kotlin对原始类型有特殊的优化(主要体现在避免了自动装箱带来的开销),所以我们建议优先使用原始类型数组。
若你熟悉Java,你应该知道数组的一些特性:
• 数组大小固定,并且同一个数组只能存放类型一样的数据(基本类型/引用类型);
• 数组在内存中地址是连续的,所以性能比较好。
因为数组大小固定,所以限制了很多使用场景。我们通常采用可自动扩容的集合,这将在第6章中详细介绍。
5.4 泛型:让类型更加安全
在了解完Kotlin中的类型系统设计之后,我们肯定少不了探讨另一个东西,那就是泛型。你已经知道的是,Kotlin支持在写方法的时候这样指定方法参数的具体类型:
fun sum(a: Int, b: Int) {
return a + b
}那么,能不能将参数的类型也参数化呢?比如:
fun sum(a: T, b: T) {
return a + b
}其实这便是Kotlin中的泛型。在具体介绍该语法及对比Java的泛型之前,我们先来看看为什么要有泛型。
5.4.1 泛型:类型安全的利刃
众所周知,Java 1.5引入泛型。那么我们来思考一个问题,为什么Java一开始没有引入泛型,而1.5版本却引入泛型?先来看一个场景:
List stringList = new ArrayList();
stringList.add(new Double(2.0));
String str = (String)stringList.get(0);
执行结果:
>>> java.lang.ClassCastException: java.lang.Double cannot be cast to java.lang.String
at javat.Rectangle.main(Rectangle.java:29)因为ArrayList底层是用一个Object类型的数组实现的,这种实现虽然能让ArrayList变得更通用,但也会带来弊端。比如上面例子中,我们不小心向原本应作为String类型的List中添加了一个Double类型的对象,理想的情况下编译器应该能够提示错误,但事实上这段代码能编译通过,在运行时却会报错。这是一个非常糟糕的体验,我们真正需要的是在代码编译的时候就能发现错误,而不是让错误的代码发布到生产环境中。这便是泛型诞生的一个重要的原因。有了泛型后,我们可以这么做:
List<String> stringList = new ArrayList<String>();
stringList.add(new Double(2.0)); //编译时报错,add(java.lang.String)无法适配add (java.lang.Double)利用泛型代码在编译时期就能发现错误,防止在真正运行的时候出现ClassCastException。当然,泛型除了能帮助我们在编译时期进行类型检查外,还有很多其他好处,比如自动类型转换。
我们继续来看第一段代码,在获取List中的值的时候,我们进行了以下操作:
String str = (String)stringList.get(0);是不是感觉异常的烦琐,明明知道里面存的是String类型的值,取值的时候还要进行类型强制转换。但有了泛型之后,就可以利用下面这种方式实现:
List<String> stringList = new ArrayList<String>();
stringList.add("test");
String str = stringList.get(0);有了泛型之后,不仅在编译的时候能进行类型检查,在运行时还会自动进行类型转换。而且通过引入泛型,增强上述功能的同时并没有增加代码的冗余性。比如我们无须为声明一个类型安全的List而去创建StringList、DoubleList等类,只需在声明List的同时指定参数类型即可。
总的来说,泛型有以下几点优势:
• 类型检查,能在编译时就帮你检查出错误;
• 更加语义化,比如我们声明一个List<String>,便可以知道里面存储的是String对象,而不是其他对象;
• 自动类型转换,获取数据时不需要进行类型强制转换;
• 能写出更加通用化的代码。
本节我们简单地回顾了一下Java中的泛型。下面我们就来看看在Kotlin中如何使用泛型。
5.4.2 如何在Kotlin中使用泛型
Kotlin和Java一样,都使用尖括号这种方式来表示泛型,比如<T>、<E>、<?>等。比如我们上面举例的Collection<E>便是一个泛型接口。接下来我们就来看看如何在Kotlin中声明一个泛型类和泛型函数。
我们还是以Kotlin中的集合为例,假设现在我们有一个需求,定义一个find方法,传入一个对象,若列表中存在该对象,则返回该对象,不存在则返回空。由于原有的集合类不存在这个方法,所以可以定义一个新的集合类,同样也要声明泛型。我们可以这么做:
class SmartList<T> : ArrayList<T>(){
fun find(t: T) : T? {
val index = super.indexOf(t)
return if (index >= 0) super.get(index) else null
}
}
fun main(args: Array<String>) {
val smartList = SmartList<String>()
smartList.add("one")
println(smartList.find("one")) //输出 one
println(smartList.find("two").isNullOrEmpty()) // 输出true
}我们发现,Kotlin定义泛型类的方式与我们在Java中所看到的类似。另外泛型类同样还可以继承另一个类,这样我们就可以使用ArrayList中的属性和方法了。
当然,除了定义一个新的泛型集合类外,我们还可以利用扩展函数来实现这种需求。由于扩展函数支持泛型的情况,所以我们可以这么做:
fun <T> ArrayList<T>.find(t: T): T? {
val index = this.indexOf(t)
return if (index >= 0) this.get(index) else null
}
fun main(args: Array<String>) {
val arrayList = ArrayList<String>()
arrayList.add("one")
println(arrayList.find("one")) //输出 one
println(arrayList.find("two").isNullOrEmpty()) // 输出true
}利用扩展函数这种方式也非常简洁,所以,当你只是需要对一个集合扩展功能的时候,使用扩展函数非常合适。有关扩展函数的具体内容将会在第7章讲解。
使用泛型时是否需要主动指定类型?
在Kotlin中,以下的方式不被允许:
val arrayList = ArrayList()而在Java中却可以这么做,这主要是因为泛型是Java 1.5版本才引入的,而集合类在Java早期版本中就已经有了。各种系统中已经存在大量的类似代码:
List list = new ArrayList();所以,为了保证兼容老版本的代码,Java允许声明没有具体类型参数的泛型类。而Kotlin是基于Java 6版本的,一开始就有泛型,不存在需要兼容老版本代码的问题。所以,当你声明一个空列表时,Kotlin需要你显式地声明具体的类型参数。当然,因为Kotlin具有类型推导的能力,所以以下这种方式也是可行的:
val arrayList = arrayListOf("one", "two")总的来说,使用泛型可以让我们的代码变得更加通用化,更加灵活。但有时过于通用灵活并不是一个好的选择,比如现在我们创建一个类型,只允许添加指定类型的对象。接下来我们就来看看如何在Kotlin中约束类型参数。
5.4.3 类型约束:设定类型上界
前面我们已经说过,泛型本身就有类型约束的作用,比如你无法向一个String类型List中添加一个Double对象。那么,这里所说的类型约束到底是什么呢?我们来看以下简单的场景。
假设现在有一个盘子,它可以放任何东西,在Kotlin中我们可以这么做:
class Plate<T>(val t : T)上面的代码创建了一个Plate类,并且拥有一个类型参数,我们可以将它看作盘子中的东西的一种泛化,比如它可以是一种水果,也可以是一种主食。但是突然有一天,你想把自己的盘子归归类,一些盘子只能放水果,一些盘子用来放菜,那么我们又该怎么做呢?
我们现在来定义一个Fruit类,并声明Apple类和Banana类来继承它:
open class Fruit(val weight: Double)
class Apple(weight: Double): Fruit(weight)
class Banana(weight: Double): Fruit(weight)然后,再定义一个水果盘子泛型类:
class FruitPlate<T: Fruit>(val t : T)这种语法是不是很熟悉?它跟Kotlin中继承的语法类似,这里的T只能是Fruit类及其子类的类型,其他类型则不被允许。比如:
class Noodles(weight: Double) //面条类
val applePlate = FruitPlate<Apple>(Apple(100.0)) // 允许
// 简化写法
val applePlate = FruitPlate(Apple(100.0)) // 允许
val noodlesPlate = FruitPlate<Noodles>(Noodles(200.0)) //不允许从上面的例子就可以看出,利用这种方式约束一个泛型类只接受一个类型的对象来帮我们在一些特殊场景使用泛型,比如实现了Comparable接口的类,我们就可以比较它们的大小。其实Java中也有类似的语法:
class FruitPlate<T extends Fruit>{
...
}它们之间的区别就是在继承语法上的区别,Java使用extends关键字,而Kotlin使用“:”,这种类型的泛型约束,我们称之为上界约束。
现在假设我们的水果盘子不一定都要装水果,有时也可以空着。比如:
val fruitPlate = FruitPlate(null)可是,前面这种方式声明的FruitPlate泛型类并不支持,这时你应该也已经意识到了,Kotlin由于区分可空和不可空类型,上面我们声明FruitPlate类是一个参数类型不可空的泛型类,所以我们需要在参数类型后面加一个“?”。比如:
class FruitPlate<T: Fruit?>(val t : T)这与我们在Kotlin中声明一个变量可空和不可空的形式类似,保持了语法的一致性。上面你所看到的类型约束都是单个条件的约束,比如类型上界是什么,是否可空。那么,有多个条件的时候该怎么办?我们来看一个例子。
现在假设有一把刀只能用来切长在地上的水果(比如西瓜),我们可以如此实现:
interface Ground{}
class Watermelon(weight: Double): Fruit(weight), Ground
fun <T> cut(t: T) where T: Fruit, T: Ground {
print("You can cut me.")
}
cut(Watermelon(3.0)) //允许
cut(Apple(2.0)) //不允许我们可以通过where关键字来实现这种需求,它可以实现对泛型参数类型添加多个约束条件,比如这个例子中要求被切的东西是一种水果,而且必须是长在地上的水果。
前面所讲的都是泛型在静态时的行为,也就是Kotlin代码编译阶段关于泛型的知识点。下面我们就来看看Kotlin中的泛型在运行时是一种怎样的状态。
5.5 泛型的背后:类型擦除
通过前面的学习,你对泛型应该有所了解了,接下来我们将深入泛型背后的实现原理。我们先回到熟悉的Java领域,来看看Java泛型如何实现。在Java中声明一个普通数组相信大家都知道怎么做,但你知道如何声明一个泛型数组吗?
5.5.1 Java为什么无法声明一个泛型数组
我们先来看一个简单的例子,Apple是Fruit的子类,思考下Apple[]和Fruit[],以及List<Apple>和List<Fruit>是什么关系呢?
Apple[] appleArray = new Apple[10];
Fruit[] fruitArray = appleArray; //允许
fruitArray[0] = new Banana(0.5); //编译通过,运行报ArrayStoreException
List<Apple> appleList = new ArrayList<Apple>();
List<Fruit> fruitList = appleList; //不允许我们发现一个奇怪的现象,Apple[]类型的值可以赋值给Fruit[]类型的值,而且还可以将一个Banana对象添加到fruitArray,编译器能通过。作为对比,List<Friut>类型的值则在一开始就禁止被赋值为List<Apple>类型的值,这其中到底有什么不同呢?
其实这里涉及一个关键点,数组是协变的,而List是不变的。简单来说,就是Object[]是所有对象数组的父类,而List<Object>却不是List<T>的父类。关于协变和不变的具体内容将会在下一节讲解。
在解释为什么在Java中无法声明泛型数组之前,我们先来看一下Java泛型的实现方式。Java中的泛型是类型擦除的,可以看作伪泛型,简单来说,就是你无法在程序运行时获取到一个对象的具体类型。我们可以用以下代码来对比一下List<T>和数组:
System.out.println(appleArray.getClass());
System.out.println(appleList.getClass());
// 运行结果
class [Ljavat.Apple;
class java.util.ArrayList从上面的代码我们可以知道,数组在运行时是可以获取自身的类型,而List<Apple>在运行时只知道自己是一个List,而无法获取泛型参数的类型。而Java数组是协变的,也就是说任意的类A和B,若A是B的父类,则A[]也是B[]的父类。但是假如给数组加入泛型后,将无法满足数组协变的原则,因为在运行时无法知道数组的类型。
Kotlin中的泛型机制与Java中是一样的,所以上面的特性在Kotlin中同样存在。比如通过下面的方式同样无法获取列表的类型:
val appleList = ArrayList<Apple>()
println(appleList.javaClass)但不同的是,Kotlin中的数组是支持泛型的,当然也不再协变,也就是说你不能将任意一个对象数组赋值给Array<Any>或者Array<Any?>。在Kotlin中Any为所有类的父类,下面是一个例子:
val appleArray = arrayOfNulls<Apple>(3)
val anyArray: Array<Any?> = appleArray //不允许我们已经知道了在Kotlin和Java中泛型是通过类型擦除来实现的,那么这又是为什么呢?
5.5.2 向后兼容的罪
Java的一大特性就是向后兼容。简单来说,就是老版本的Java文件编译后可以运行在新版本的JVM上。我们知道,Java一开始是没有泛型的,那么在Java 1.5之前,在程序中会出现大量的以下代码:
ArrayList list = new ArrayList(); //没有泛型一般在没有泛型的语言上支持泛型,一般有两种方式,以集合为例:
• 全新设计一个集合框架(全新实现现有的集合类或者创造新的集合类),不保证兼容老的代码,优点是不需要考虑兼容老的代码,写出更符合新标准的代码;缺点是需要适应新的语法,更严重的是可能无法改造老的业务代码。
• 在老的集合框架上改造,添加一些特性,兼容老代码的前提下,支持泛型。
很明显,Java选择了后种方式实现泛型,这也是有历史原因的,主要有以下两点原因:
1)在Java1.5之前已经有大量的非泛型代码存在了,若不兼容它们,则会让使用者抗拒升级,因为他要付出大量的时间去改造老代码;
2)Java曾经有过重新设计一个集合框架的教训,比如Java 1.1到Java1.2过程中的Vector到ArrayList,HashTable到HashMap,引起了大量使用者的不满。
所以,Java为了填补自己埋下的坑,只能用一种比较别扭的方式实现泛型,那便是类型擦除。
那么,为什么使用类型擦除实现泛型可以解决我们上面说的新老代码兼容的问题呢?我们先来看一下下面两行代码编译后的内容:
ArrayList list = new ArrayList(); //(1)
ArrayList<String> stringList = new ArrayList<String>(); //(2)对应字节码:
0: new #2 // class java/util/ArrayList
3: dup
4: invokespecial #3 // Method java/util/ArrayList."<init>":()V
7: astore_1
8: new #2 // class java/util/ArrayList
11: dup
12: invokespecial #3 // Method java/util/ArrayList."<init>":()V
15: astore_2我们发现方式1和方式2声明的ArrayList再编译后的字节码是完全一样的,这也说明了低版本编译的class文件在高版本的JVM上运行不会出现问题。既然泛型在编译后是会擦除泛型类型的,那么我们又为什么可以使用泛型的相关特性,比如类型检查、类型自动转换呢?
类型检查是编译器在编译前就会帮我们进行类型检查,所以类型擦除不会影响它。那么类型自动转换又是怎么实现的呢?我们来看一个例子:
ArrayList<String> stringList = new ArrayList<String>();
String s = stringList.get(0);这段代码中,get方法返回的值的类型就是List泛型参数的类型。来看一下ArrayList的get方法的源码:
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index]; //强制类型转换
}
public E get(int index) {
rangeCheck(index);
return elementData(index);
}我们发现,背后也是通过强制类型转化来实现的。这点从编译后的字节码也可以得到验证:
0: new #2 // class java/util/ArrayList
3: dup
4: invokespecial #3 // Method java/util/ArrayList."<init>":()V
7: astore_1
8: aload_1
9: iconst_0
10: invokevirtual #4 // Method java/util/ArrayList.get:(I)Ljava/lang/Object; 获取的是Object
13: checkcast #5 // class java/lang/String 强制类型转换
16: astore_2
17: return所以可以得出结论,虽然Java受限于向后兼容的困扰,使用了类型擦除来实现了泛型,但它还是通过其他方式来保证了泛型的相关特性。
5.5.3 类型擦除的矛盾
通常情况下使用泛型我们并不在意它的类型是否是类型擦除,但是在有些场景,我们却需要知道运行时泛型参数的类型,比如序列化/反序列化的时候。这时候我们应该怎么办?既然编译后会擦除泛型参数类型,那么我们是不是可以主动指定参数类型来达到运行时获取泛型参数类型的效果呢?我们试着对上面的例子的Plate进行一下改造:
open class Plate<T>(val t : T, val clazz: Class<T>) {
fun getType() {
println(clazz)
}
}
val applePlate = Plate(Apple(1.0), Apple::class.java)
applePlate.getType()
//结果
class Apple使用这种方式确实可以达到运行时获取泛型类型参数的效果。但是这种方式也有限制,比如我们就无法获取一个泛型的类型,比如:
val listType = ArrayList<String>::class.java //不被允许
val mapType = Map<String,String>::class.java //不被允许那么,还有没有另外的方式能获取各种类型的信息呢?有,那就是利用匿名内部类。我们来看下面的一个例子:
val list1 = ArrayList<String>()
val list2 = object : ArrayList<String>(){} //匿名内部类
println(list1.javaClass.genericSuperclass)
println(list2.javaClass.genericSuperclass)
//结果:
java.util.AbstractList<E>
java.util.ArrayList<java.lang.String>第2种方式竟然能在运行时知道这个list是一个什么样的类型。list2声明的其实是一个匿名内部类。关于如何在Kotlin中用object来声明一个匿名内部类的相关知识可以回顾一下第3章的相应内容。那么,为什么使用匿名内部类的这种方式能够在运行时获取泛型参数的类型呢?其实泛型类型擦除并不是真的将全部的类型信息都擦除,还是会将类型信息放在对应class的常量池中的。
Java将泛型信息存储在哪里?
可以参考以下网页:https://stackoverflow.com/questions/937933/where-are-generic-types-stored-in-java-class-files/937999#937999
所以,既然还存储着相应的类型信息,那么我们就能通过相应的方式来获取这个类型信息。使用匿名内部类我们就可以实现这种需求。我们着手来设计一个能获取所有类型信息的泛型类:
import java.lang.reflect.ParameterizedType
import java.lang.reflect.Type
open class GenericsToken<T> { //
var type: Type = Any::class.java
init {
val superClass = this.javaClass.genericSuperclass
type = (superClass as ParameterizedType).getActualTypeArguments()[0]
}
}
fun main(args: Array<String>) {
val gt = object : GenericsToken<Map<String,String>>(){} //使用object创建一个匿名内部类
println(gt.type)
}
//结果
java.util.Map<java.lang.String, ? extends java.lang.String>匿名内部类在初始化的时候就会绑定父类或父接口的相应信息,这样就能通过获取父类或父接口的泛型类型信息来实现我们的需求。你可以利用这样一个类来获取任何泛型的类型,我们常用的Gson也是使用了相同的设计。
Gson的TypeToken实现参考以下网址:https://github.com/google/gson/blob/master/gson/src/main/java/com/google/gson/reflect/TypeToken.java
比如,我们在Kotlin中可以这样使用Gson来进行泛型类的反序列化:
val json = ...
val rType = object : TypeToken<List<String>>() {}.type
val stringList = Gson().fromJson<List<String>>(json, rType)其实,在Kotlin中除了用这种方式来获取泛型参数类型以外,还有另外一种方式,那就是内联函数。
5.5.4 使用内联函数获取泛型
Kotlin中的内联函数在编译的时候编译器便会将相应函数的字节码插入调用的地方,也就是说,参数类型也会被插入字节码中,我们就可以获取参数的类型了。有关内联函数的内容可以看一下第6章的相应章节。下面我们就用内联函数来实现一个可以获取泛型参数的方法:
inline fun <reified T> getType() {
return T::class.java
}使用内联函数获取泛型的参数类型非常简单,只需加上reified关键词即可。这里的意思相当于,在编译的会将具体的类型插入相应的字节码中,那么我们就能在运行时获取到对应参数的类型了。所以,我们可以在Kotlin中改进Gson的使用方式:
inline fun <reified T : Any> Gson.fromJson(json: String): T { //对Gson进行扩展
return Gson().fromJson(json, T::class.java)
}
//使用
val json = ...
val stringList = Gson().fromJson<List<String>>(json)这里利用了Kotlin的扩展特性对Gson进行了功能扩展,在不改变原有类结构的情况下新增方法,很多场景用Kotlin来实现便会变得更加优雅。有关扩展的相关内容会在第7章讲解。
另外需要注意的一点是,Java并不支持主动指定一个函数是否是内联函数,所以在Kotlin中声明的普通内联函数可以在Java中调用,因为它会被当作一个常规函数;而用reified来实例化的参数类型的内联函数则不能在Java中调用,因为它永远是需要内联的。
5.6 打破泛型不变
前面我们所讲的都是泛型的一些基本概念,比如为什么需要泛型,运行时泛型的状态等。下面我们将会了解泛型的一些高级特性,比如协变、逆变等,并学习Kotlin如何将之前在Java泛型中比较难以理解的概念进行更优雅的改造,变得更容易理解。
5.6.1 为什么List<String>不能赋值给List<Object>
我们在上面5.5.1节中已经提出了类似的问题,List<Apple>无法赋值给List<Fruit>,并接触了数组是协变,而List是不变的相关概念,而且用反证法说明了如果在Java支持直接声明泛型数组会出现什么问题。现在我们用同样的思维来看待这个问题,假如List<String>能赋值给List<Object>会出现什么情况。我们来看一个例子:
List<String> stringList = new ArrayList<String>();
List<Object> objList = stringList; //假设可以,编译报错
objList.add(Integer(1));
String str = stringList.get(0); //将会出错我们发现,在Java中如果允许List<String>赋值给List<Object>这种行为的话,那么它将会和数组支持泛型一样,不再保证类型安全,而Java设计师明确泛型最基本的条件就是保证类型安全,所以不支持这种行为。但是到了Kotlin这里我们发现了一个奇怪的现象:
val stringList: List<String> = ArrayList<String>()
val anyList: List<Any> = stringList //编译成功在Kotlin中竟然能将List<String>赋值给List<Any>,不是说好的Kotlin和Java的泛型原理是一样的吗?怎么到了Kotlin中就变了?其实我们前面说的都没错,关键在于这两个List并不是同一种类型。我们分别来看一下两种List的定义:
public interface List<E> extends Collection<E> {
...
}
public interface List<out E> : Collection<E> {
...
}虽然都叫List,也同样支持泛型,但是Kotlin的List定义的泛型参数前面多了一个out关键词,这个关键词就对这个List的特性起到了很大的作用。普通方式定义的泛型是不变的,简单来说就是不管类型A和类型B是什么关系,Generic<A>与Generic<B>(其中Generic代表泛型类)都没有任何关系。比如,在Java中String是Oject的子类型,但List<String>并不是List<Object>的子类型,在Kotlin中泛型的原理也是一样的。但是,Kotlin的List为什么允许List<String>赋值给List<Any>呢?
5.6.2 一个支持协变的List
上面我们看到了Kotlin中List的定义,它在泛型参数前面加了一个out关键词,我们在心里大概猜想,难道这个List的泛型参数是可变的?确实是这样的,如果在定义的泛型类和泛型方法的泛型参数前面加上out关键词,说明这个泛型类及泛型方法是协变,简单来说类型A是类型B的子类型,那么Generic<A>也是Generic<B>的子类型,比如在Kotlin中String是Any的子类型,那么List<String>也是List<Any>的子类型,所以List<String>可以赋值给List<Any>。但是我们上面说过,如果允许这种行为,将会出现类型不安全的问题。那么Kotlin是如何解决这个问题的?我们来看一个例子:
val stringList: List<String> = ArrayList<String>()
stringList.add("kotlin") //编译报错,不允许这又是什么情况,往一个List中插入一个对象竟然不允许,难道这个List只能看看?确实是这样的,因为这个List支持协变,那么它将无法添加元素,只能从里面读取内容。这点我们从List的源码也可以看出:
public interface List<out E> : Collection<E> {
override val size: Int
override fun isEmpty(): Boolean
override fun contains(element: @UnsafeVariance E): Boolean
override fun iterator(): Iterator<E>
override fun containsAll(elements: Collection<@UnsafeVariance E>): Boolean
public operator fun get(index: Int): E
public fun indexOf(element: @UnsafeVariance E): Int
public fun lastIndexOf(element: @UnsafeVariance E): Int
public fun listIterator(): ListIterator<E>
public fun listIterator(index: Int): ListIterator<E>
public fun subList(fromIndex: Int, toIndex: Int): List<E>
}我们发现,List中本来就没有定义add方法,也没有remove及replace等方法,也就是说这个List一旦创建就不能再被修改,这便是将泛型声明为协变需要付出的代价。那么为什么泛型协变会有这个限制呢?同样我们用反证法来看这个问题,如果允许向这个List插入新对象,会发生什么?我们来看一个例子:
val stringList: List<String> = ArrayList<String>()
val anyList: List<Any> = stringList
anyList.add(1)
val str: String = anyList.get(0) //Int无法转换为String[插图]从上面的例子可以看出,假如支持协变的List允许插入新对象,那么它就不再是类型安全的了,也就违背了泛型的初衷。所以我们可以得出结论:支持协变的List只可以读取,而不可以添加。其实从out这个关键词也可以看出,out就是出的意思,可以理解为List是一个只读列表。在Java中也可以声明泛型协变,用通配符及泛型上界来实现协变:<?extends Object>,其中Object可以是任意类。比如在Java中声明一个协变的List:
public interface List <? extends T> {
......
}但泛型协变实现起来非常别扭,这也是Java泛型一直被诟病的原因。很庆幸,Kotlin改进了它,使我们能用简洁的方式来对泛型进行不同的声明。
另外需要注意的一点的是:通常情况下,若一个泛型类Generic<out T>支持协变,那么它里面的方法的参数类型不能使用T类型,因为一个方法的参数不允许传入参数父类型的对象,因为那样可能导致错误。
但在Kotlin中,你可以添加@UnsafeVariance注解来解除这个限制,比如上面List中的indexOf等方法。
上面介绍了泛型不变和协变的两种情况,那么会不会出现第3种情况,比如类型A是类型B的子类型,但是Generic<B>反过来又是Generic<A>的子类型呢?
5.6.3 一个支持逆变的Comparator
协变:原来是父子,支持泛型协变后的泛型类也还是父子关系。但是反过来又是什么一个什么情况?比如Double是Number的子类型,反过来Generic<Double>却是Generic<Number>的父类型?那么到底有没有这种场景呢?
我们来思考一个问题,假设现在需要对一个MutableList<Double>进行排序,利用其sortWith方法,我们需要传入一个比较器,所以可以这么做:
val doubleComparator = Comparator<Double> {
d1, d2 -> d1.compareTo(d2)
}
val doubleList = mutableListOf(2.0, 3.0)
doubleList.sortWith(doubleComparator)暂时来看,没有什么问题。但是现在我们又需要对MutableList<Int>、MutableList<Long>等进行排序,那么我们是不是又需要定义intComparator、longComparator等呢?现在看来这并不是一种好的解决方法。那么试想一下可不可以定义一个比较器,给这些列表使用。我们知道,这些数字类有一个共同的父类Number,那么Number类型的比较器是否代替它的子类比较器?比如:
val numberComparator = Comparator<Number> {
n1, n2 -> n1.toDouble().compareTo(n2.toDouble())
}
val doubleList = mutableListOf(2.0, 3.0)
doubleList.sortWith(numberComparator)
val intList = mutableListOf(1,2)
intList.sortWith(numberComparator)编译通过,验证了我们的猜想。那么为什么numberComparator可以代替doubleComparator、intComparator呢?我们来看一下sortWith方法的定义:
public fun <T> MutableList<T>.sortWith(comparator: Comparator<in T>): Unit {
if (size > 1) java.util.Collections.sort(this, comparator)
}这里我们又发现了一个关键词in,跟out一样,它也使泛型有了另一个特性,那就是逆变。简单来说,假若类型A是类型B的子类型,那么Generic<B>反过来是Generic<A>的子类型,所以我们就可以将一个numberComparator作为doubleComparator传入。那么将泛型参数声明为逆变会不会有什么限制呢?
前面我们说过,用out关键字声明的泛型参数类型将不能作为方法的参数类型,但可以作为方法的返回值类型,而in刚好相反。比如声明以下一个列表:
interface WirteableList<in T> {
fun get(index: Int): T //Type parameter T is declared as 'in' but occurs in 'out' position in type T
fun get(index: Int): Any //允许
fun add(t: T): Int //允许
}我们不能将泛型参数类型当作方法返回值的类型,但是作为方法的参数类型没有任何限制,其实从in这个关键词也可以看出,in就是入的意思,可以理解为消费内容,所以我们可以将这个列表看作一个可写、可读功能受限的列表,获取的值只能为Any类型。在Java中使用<?super T>可以达到相同效果。
到这里相信大家对泛型的变形,以及如何在Kotlin中使用协变与逆变有了大概的了解了。下面我们就着重来探讨一下如何简单地使用它们,并总结它们之间的差异。
5.6.4 协变和逆变
in和out是一个对立面,其中in代表泛型参数类型逆变,out代表泛型参数类型协变。从字面意思上也可以理解,in代表着输入,而out代表着输出。但同时它们又与泛型不变相对立,统称为型变,而且它们可以用不同方式使用。比如:
public interface List<out E> : Collection<E> {}这种方式是在声明处型变,另外还可以在使用处型变,比如上面例子中sortWith方法。在了解了泛型变形的原理后,我们来看一下泛型变形到底在什么地方发挥了它最大的用处。
假设现在有个场景,需要将数据从一个Double数组拷贝到另一个Double数组,我们该怎么实现呢?
一开始我们可能会这么做:
fun copy(dest: Array<Double>, src: Array<Double>) {
if (dest.size < src.size) {
throw IndexOutOfBoundsException()
} else {
src.forEachIndexed{index,value -> dest[index] = src[index]}
}
}
var dest = arrayOfNulls<Double>(3)
val src = arrayOf<Double>(1.0,2.0,3.0)
copy(dest, src)这很直观也很简单,但是学过泛型后的你一定不会这么做了,因为假如替换成Int类型的列表,是不是又得写一个copy方法?所以我们可以对其进一步抽象:
fun <T> copy(dest: Array<T>, src: Array<T>) {
if (dest.size < src.size) {
throw IndexOutOfBoundsException()
} else {
src.forEachIndexed{index,value -> dest[index] = src[index]}
}
}
var destDouble = arrayOfNulls<Double>(3)
val srcDouble = arrayOf<Double>(1.0,2.0,3.0)
copy(destDouble, srcDouble)
var destInt = arrayOfNulls<Int>(3)
val srcInt = arrayOf<Int>(1,2,3)
copy(destInt, srcInt)通过实现一个泛型的copy,可以支持任意类型的List拷贝。那么这种方式有没有什么局限呢?我们发现,使用copy方法必须是同一种类型,那么假如我们想把Array<Double>拷贝到Array<Number>中将不允许,这时候我们就可以利用上面所说的泛型变形了。这种场景下是用协变还是逆变呢?
//in版本
fun <T> copyIn(dest: Array<in T>, src: Array<T>) {
if (dest.size < src.size) {
throw IndexOutOfBoundsException()
} else {
src.forEachIndexed{index,value -> dest[index] = src[index]}
}
}
//out版本
fun <T> copyOut(dest: Array<T>, src: Array<out T>) {
if (dest.size < src.size) {
throw IndexOutOfBoundsException()
} else {
src.forEachIndexed{index,value -> dest[index] = src[index]}
}
}
var dest = arrayOfNulls<Number>(3)
val src = arrayOf<Double>(1.0,2.0,3.0)
copyIn(dest, src) //允许
copyOut(dest, src) //允许到这里你可能迷糊了,为什么两种方式都允许?其实细看便能发现不同,in是声明在dest数组上,而out是声明在src数组上,所以dest可以接收T类型的父类型的Array,out可以接收T类型的子类型的Array。当然这里的T要到编译的时候才能确定。比如:
• in版本,T是Double类型,所以dest可以接收Double类型的父类型Array,比如Array<Number>。
• out版本,T是Number类型,所以src可以接收Number类型的子类型Array,比如Array<Double>。
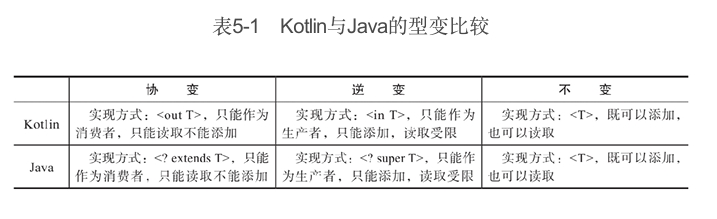
所以in和out的使用是非常灵活的。当然上面我们也提到了使用了它们就会有相应的限制,这里我们就对泛型参数类型不同情况的特性及实现方式进行一下总结,如表5-1所示。
前面我们所说的泛型变形或者不变都是在一种前提下的讨论,那就是你需要知道泛型参数是什么类型或者哪一类类型,比如它是String或者是Number及其子类型的。如果你对泛型参数的类型不感兴趣,那么你可以使用类型通配符来代替泛型参数。前面已经接触过Java中的泛型类型通配符“?”,而在Kotlin中则用“*”来表示类型通配符。比如:
val list: MutableList<*> = mutableListOf(1,"kotlin")
list.add(2.0) //出错这个列表竟然不能添加,不是说好是通配吗?按道理应该可以添加任意元素。其实不然,MutableList<*>与MutableList<Any?>不是同一种列表,后者可以添加任意元素,而前者只是通配某一种类型,但是编译器却不知道这是一种什么类型,所以它不允许向这个列表中添加元素,因为这样会导致类型不安全。不过细心的读者应该发现前面所说的协变也是不能添加元素,那么它们两者之间有什么关系呢?其实通配符只是一种语法糖,背后上也是用协变来实现的。所以MutableList<*>本质上就是MutableList<out Any?>,使用通配符与协变有着一样的特性。
当前泛型变形的另一大用处是体现于高阶函数,比如Java 8中新增的Stream中就有其应用:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);另外,在第10章中的责任链模式也会涉及高阶函数对于泛型变形的应用。
5.7 本章小结
(1)null引发的问题
null是一个不是值的值,它在不同语言中有着不同的名字:NULL、nil、null、None、Nothing、Nil和nullptr。它经常会给程序带来NPE异常,所以臭名昭著。并且在程序中,它是有歧义、不受控制并且很难调试的。
(2)解决null的一些方案
• 函数内对于无效值,可以抛异常处理。
• 采用@NotNull/@Nullable标注。
• 使用专门的Optional对象对可能为null的变量进行装箱。
(3)可空类型
很多高级语言都有可空类型,如Haskell的Maybe、Scala的Option[T]、Java 8的Optional<T>。Kotlin也不例外,采用了Type?来表示可空。虽然都表示可空,但是相互存在差异。文中用Java 8的Optional和Kotlin进行对比,发现效率上Kotlin更优。
(4)Kotlin类型层级
Kotlin并没有新加入其他的类型,但是具备比Java更加纯的设计:在Kotlin的类型系统中,并不区分原始类型(基本数据类型)和包装类型,我们使用的始终是同一个类型。这在装箱与拆箱方面有着不同的表现。另外Kotlin加入了可空类型,这是Java中一个重要的跨越。
(5)泛型让类型更加安全
泛型可以让我们的代码更加安全,语义化,通用化。Kotlin的泛型使用跟Java的很类似,同样用<T>来表示泛型,同时Kotlin提供了更加简洁的方式来实现泛型约束。
(6)泛型擦除
探究泛型的背后实现原理,为什么在JVM上是使用类型擦除来实现泛型,并探讨如何解决由于泛型擦除引起的问题。同时介绍了如何在Kotlin中通过内联函数在运行时获取泛型参数的具体类型。
(7)泛型变形
泛型是不变的,但是很多场景下我们需要泛型类型是可变的,讲解了什么是泛型的协变(out)与逆变(in),以及它们的特性,并比较了Kotlin与Java中实现泛型变形的方式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









