






文章目录
前言
在 Linux/UNIX 系统中包含很多种文本处理器或文本编辑器,其中包括我们之前用到的VIM 编辑器与 grep 等。而 grep,sed,awk 更是 shell 编程中经常用到的文本处理工具,被称之为 Shell 编程三剑客。
grep
grep 命令用于查找文件里符合条件的字符串
grep [选项]… 查找条件 目标文件
选项
- -i:查找时忽略大小写
- -v:反向查找,输出与查找条件不相符的行
- -o 只显示匹配项
- -f 对比两个文件的相同行
- -c 匹配的行数
显示行号-n,过滤出the

-vn显示行号反选
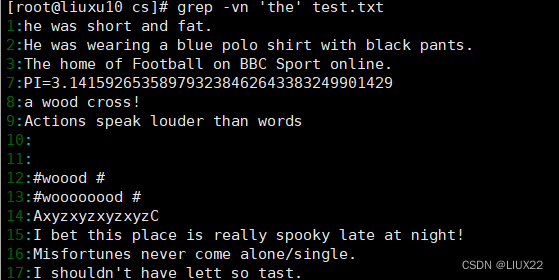
-in显示行号,忽略大小写

-c 匹配行数,后面跟要匹配的字符

-o只显示匹配的字符

sed 工具
概述
sed(Stream EDitor)是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等),最后输出所有行或者仅输出处理的某些行。sed也可以在无交互的情况下实现相当复杂的文本处理操作,被广泛应用于Shell脚本中,用以完成各种自动化处理任务。
sed 的工作流程主要包括读取、执行和显示三个过程。
- 读取:sed 从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)。
- 执行:默认情况下,所有的 sed 命令都在模式空间中顺序地执行,除非指定了行的地址,否则 sed 命令将会在所有的行上依次执行。
- 显示:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空。
在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完。
注意:默认情况下所有的 sed 命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出。
基本语法
通常情况下调用sed命令有两种格式,如下所示。其中,“参数”是指操作的目标文件,当存在多个操作对象时用,文件之间用逗号“,”分隔;而scriptfile表示脚本文件,需要用“-f”选项指定,当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。
Sed[选项] '操作' 参数
sed [选项] -f scriptfile 参数
常见的 sed 命令选项
- -e 或–expression=:表示用指定命令或者脚本来处理输入的文本文件。
- -f 或–file=:表示用指定的脚本文件来处理输入的文本文件。
- -h 或–help:显示帮助。
- -n、–quiet 或 silent:表示仅显示处理后的结果。
- -i:直接编辑文本文件。
常见的操作
“操作”用于指定对文件操作的动作行为,也就是 sed 的命令。通常情况下是采用的“[n1[,n2]]”操作参数的格式。n1、n2 是可选的,不一定会存在,代表选择进行操作的行数,如操作需要在 5~20 行之间进行,则表示为“5,20 动作行为”。常见的操作包括以下几种。
- a:增加,在当前行下面增加一行指定内容。
- c:替换,将选定行替换为指定内容。
- d:删除,删除选定的行。
- i:插入,在选定行上面插入一行指定内容。
- p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以 ASCII 码输出。其通常与“-n”选项一起使用。
- s:替换,替换指定字符。
- y:字符转换。
实验
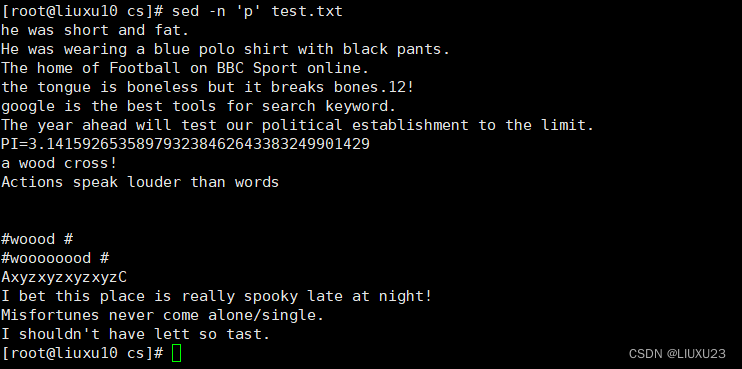
sed -n 'p' test.txt 输出所有内容 ,等同于使用cat
sed -n '3p' test.txt 输出第 3 行

sed -n '3,5p' test.txt 输出 3~5 行

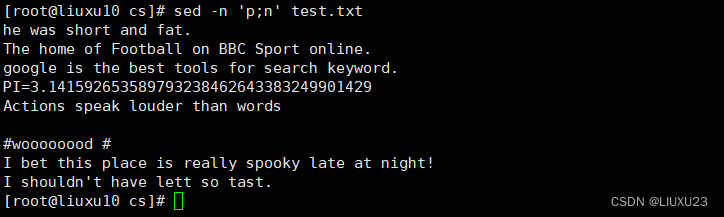
sed -n 'p;n' test.txt 输出所有奇数行,n 表示读入下一行资料
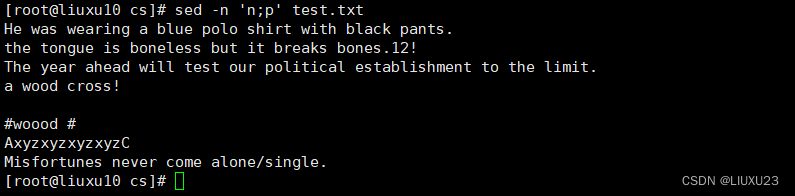
sed -n 'n;p' test.txt 输出所有偶数行,n 表示读入下一行资料
sed -n '1,5{p;n}' test.txt 输出第 1~5 行之间的奇数行(第 1、3、5 行)

sed -n '10,${n;p}' test.txt 输出第 10 行至文件尾之间的偶数行

结合正则表达式
输出符合条件的文本
sed -n '/the/p' test.txt 输出包含the 的行

sed -n '4,/the/p' test.txt 输出从第4行至第1个包含the的行

sed -n '/the/=' test.txt 输出包含the 的行所在的行号,等号(=)用来输出行号

sed -n '/^PI/p' test.txt 输出以PI 开头的行

sed -n '/[0-9]$/p' test.txt 输出以数字结尾的行

sed -n '/\<wood\>/p' test.txt 输出包含单词wood 的行,\<、\>代表单词边界

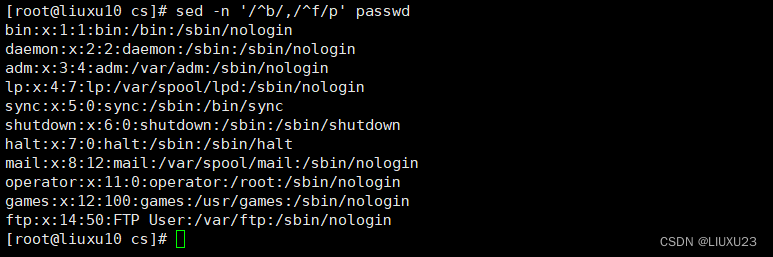
sed -n '/^b/,/^f/p' passwd
基本格式 '/表达式1/,/表达式2/p' (不要忘记打印)p 文件名
删除符合条件的文本
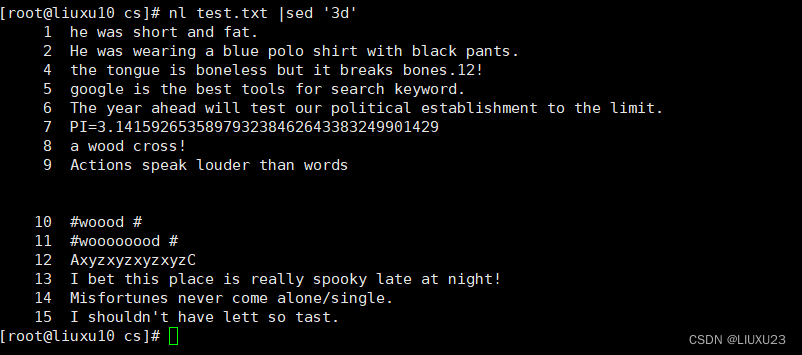
nl test.txt |sed '3d' 删除第 3 行
nl 命令用于计算文件的行数
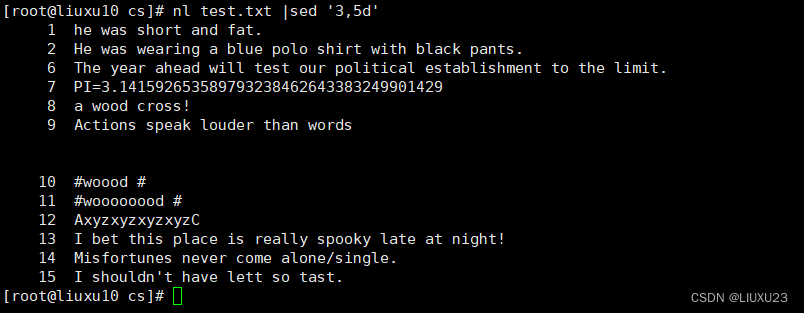
nl test.txt |sed '3,5d' 删除第 3~5 行
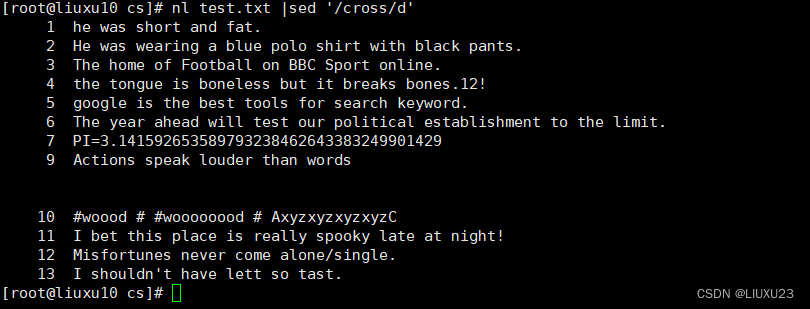
nl test.txt |sed '/cross/d' 删除包含cross 的行,原本的第 8 行被删除
删除不包含cross 的行,用!符号表示取反操作,如'/cross/!d'

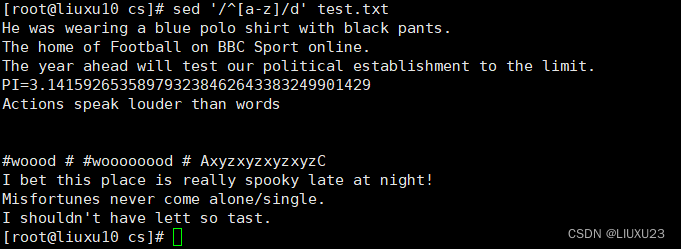
sed '/^[a-z]/d' test.txt 删除以小写字母开头的行
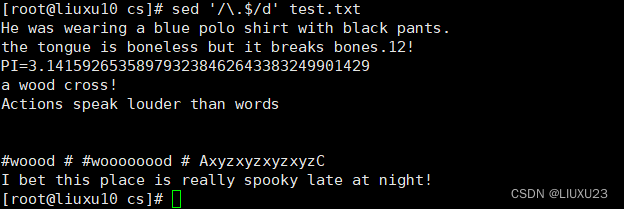
sed '/\.$/d' test.txt 删除以"."结尾的行
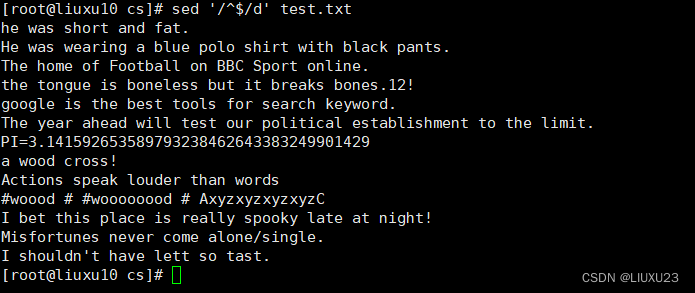
sed '/^$/d' test.txt 删除所有空行
替换符合条件的文本
在使用 sed 命令进行替换操作时需要用到 s(字符串替换)、c(整行/整块替换)、y(字符转换)命令选项
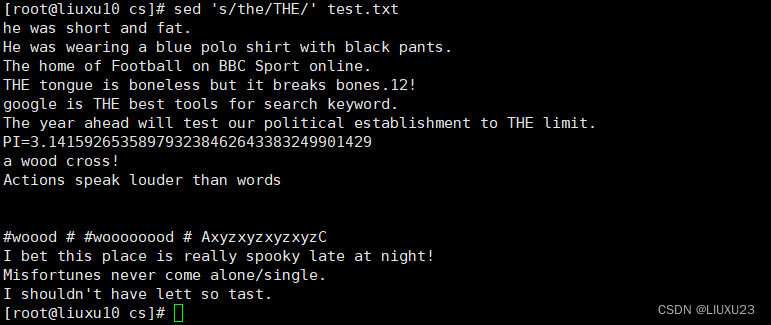
sed 's/the/THE/' test.txt 将每行中的第一个the替换为THE
sed 's/l/L/2' test.txt 将每行中的第2 个l替换为L
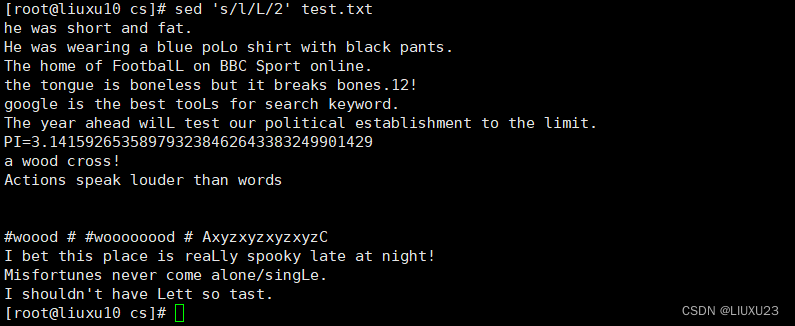
sed 's/the/THE/g' test.txt 将文件中的所有the替换为THE
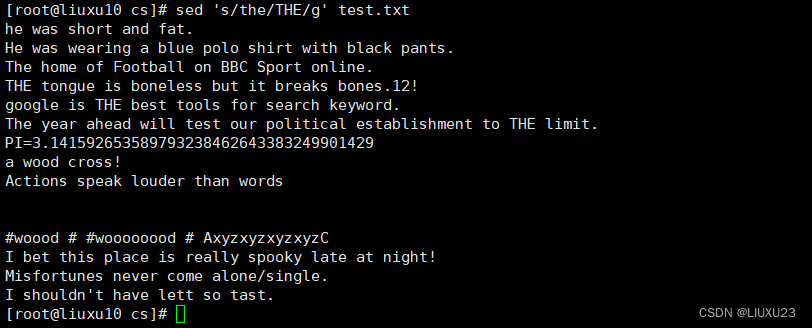
sed 's/o//g' test.txt 将文件中的所有o 删除(替换为空串)
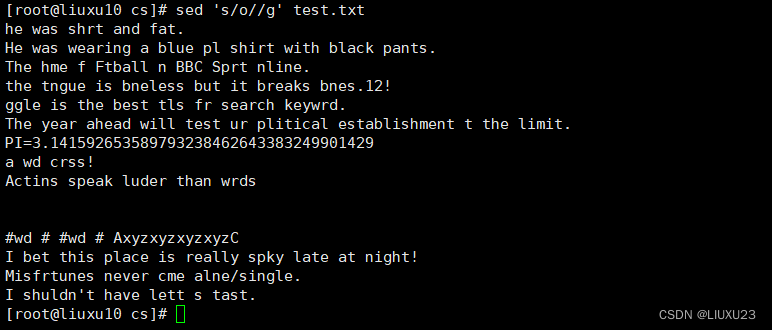
sed 's/^/#/' test.txt 在每行行首插入#号
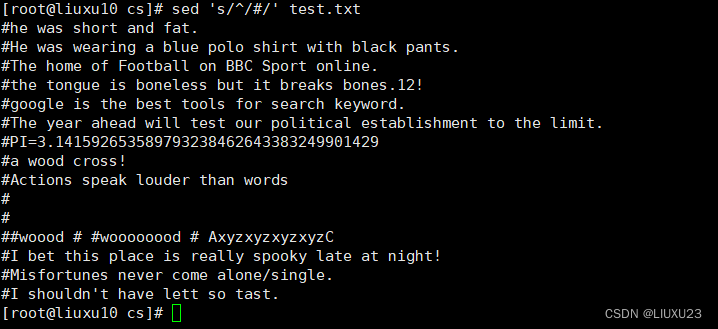
sed '/the/s/^/#/' test.txt 在包含the的每行行首插入#号
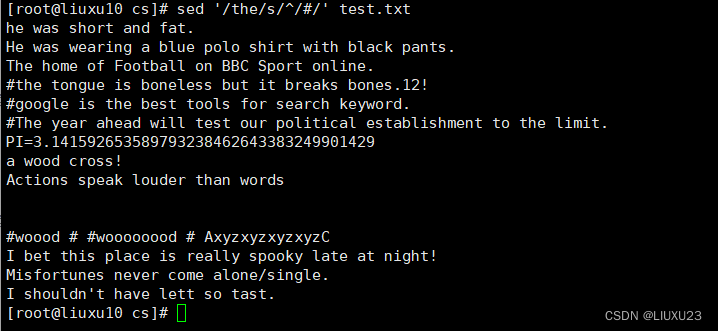
sed 's/$/EOF/' test.txt 在每行行尾插入字符串EOF
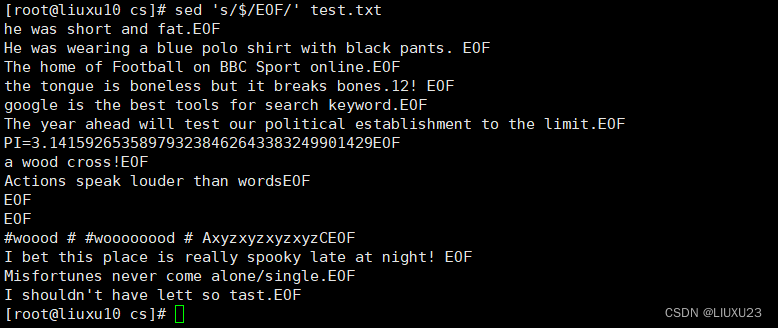
sed '3,5s/the/THE/g' test.txt 将第3~5行中的所有the替换为THE
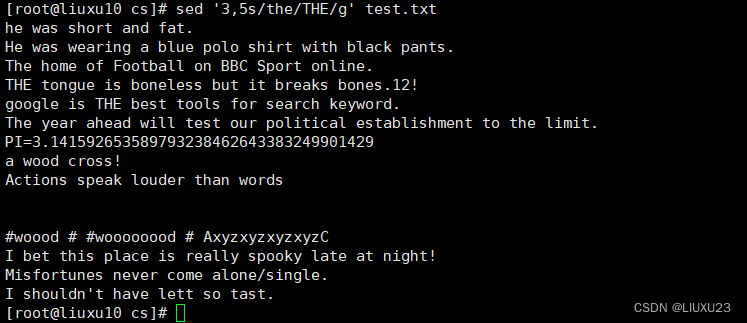
sed '/the/s/o/O/g' test.txt 将包含the 的所有行中的o 都替换为 O
迁移符合条件的文本
H,复制到剪贴板;g、G,将剪贴板中的数据覆盖/追加至指定行;w,保存为文件;r,读取指定文件;a,追加指定内容。
sed '/the/{H;d};$G' test.txt 将包含the的行迁移至文件末尾,{;}用于多个操作
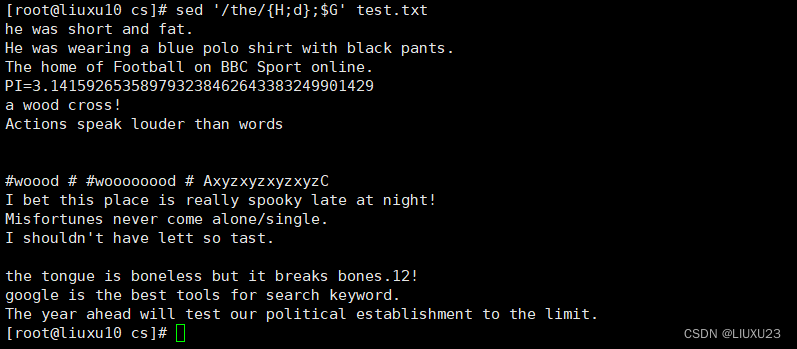
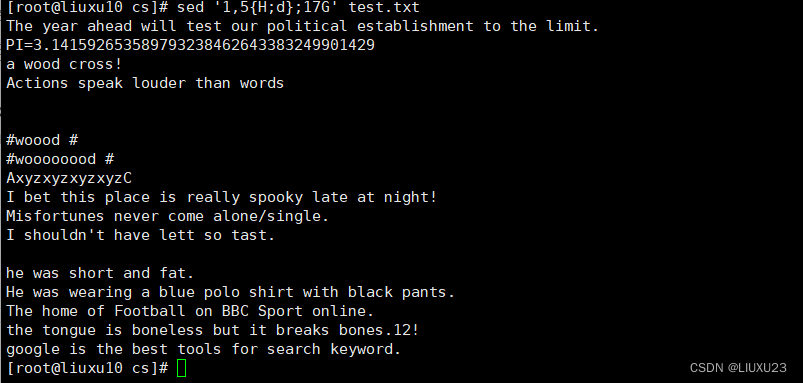
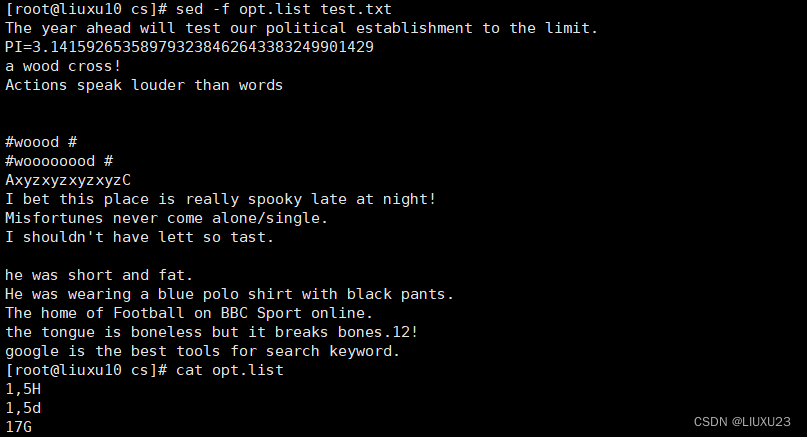
sed '1,5{H;d};17G' test.txt 将第1~5行内容转移至第17行后
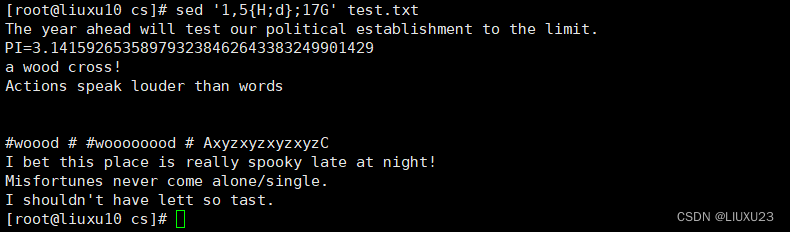
sed '/the/wout.file' test.txt 将包含the的行另存为文件out.file
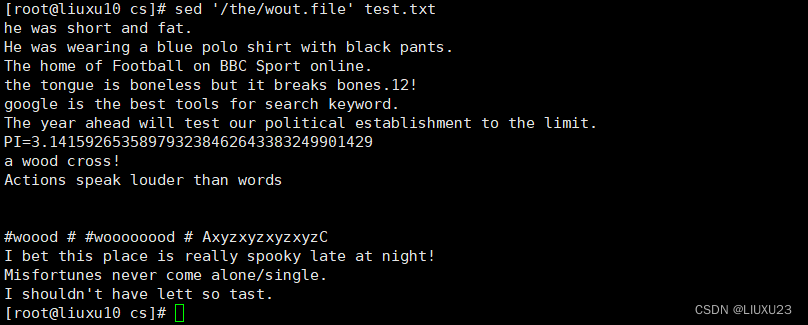

sed '/the/r /etc/hostname' test.txt 将文件/etc/hostname的内容添加到包含the 的每行以后
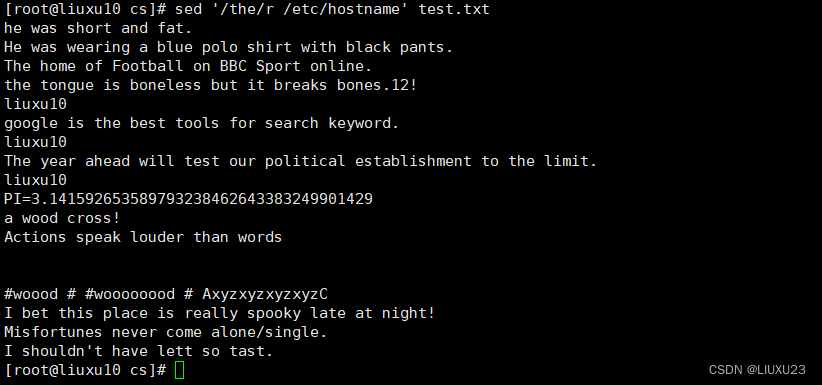
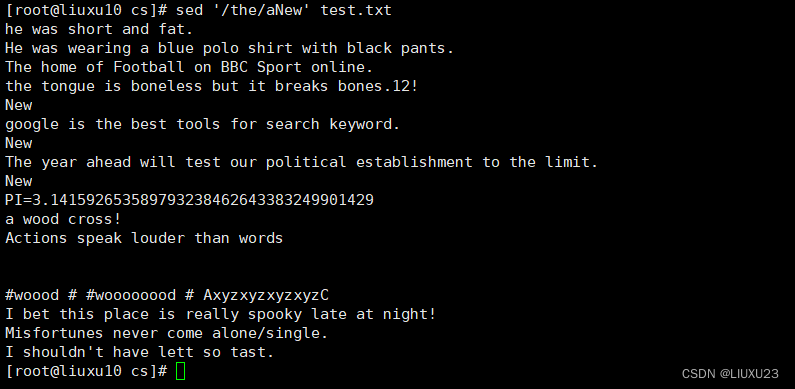
sed '3aNew' test.txt 在第3行后插入一个新行,内容为New
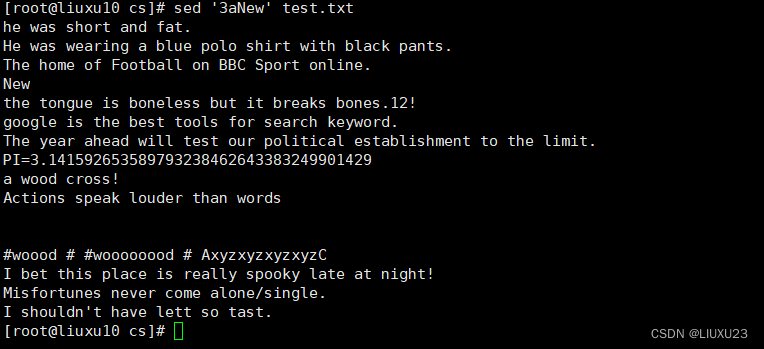
sed '/the/aNew' test.txt 在包含the的每行后插入一个新行,内容为New
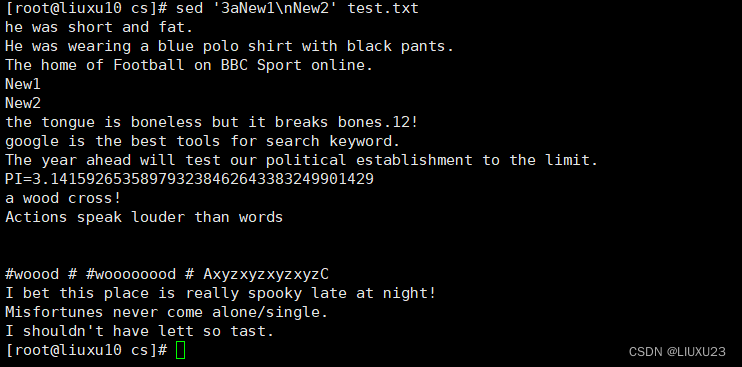
sed '3aNew1\nNew2' test.txt 在第3行后插入多行内容,中间的\n表示换行
使用脚本编辑文件
使用sed脚本,将多个编辑指令存放到文件中(每行一条编辑指令),通过“-f”选项来调用。
sed '1,5{H;d};17G' test.txt 将第 1~5 行内容转移至第 17 行后
以上操作可以改用脚本文件方式:
sed -f opt.list test.txt
echo 123abcxyz |sed -r 's/(123)(abc)(xyz)/\1/'
##分组 s//代表查找替换 ()代表分组 \1 代表留下的组123
echo 123xyzabc |sed -r 's/(123)(xyz)(abc)/\1\2/'


调用变量来改文件
name=root
sed -nr "/$name/p" passwd
#使用双引号
sed -nr '/'$name'/p' /etc/passwd
#变量上家上单引号


awk
概述
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作
数据可以来自标准输入也可以是管道或文件
工作原理:
当读到第一行时,匹配条件,然后执行指定动作,再接着读取第二行数据处理,不会默认输出。
如果没有定义匹配条件默认是匹配所有数据行,awk隐含循环,条件匹配多少次动作就会执行多少次。
逐行读取输入文本,并根据指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互的情况下实现相当复杂的文本操作。
sed命令常用于一整行的处理,而awk比较倾向于将一行分为多个"字段"然后再进行处理,awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示,
在使用awk命令的过程中,可以使用逻辑操作符"&&“表示"与”、“||“表示"或”、”!“表示"非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
选项
awk [选项] ‘模式条件{操作}’ 文件1 文件2....
awk -f|-v 脚本文件 文件1 文件2.....
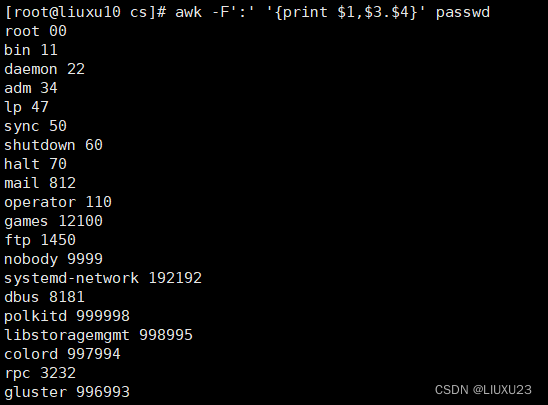
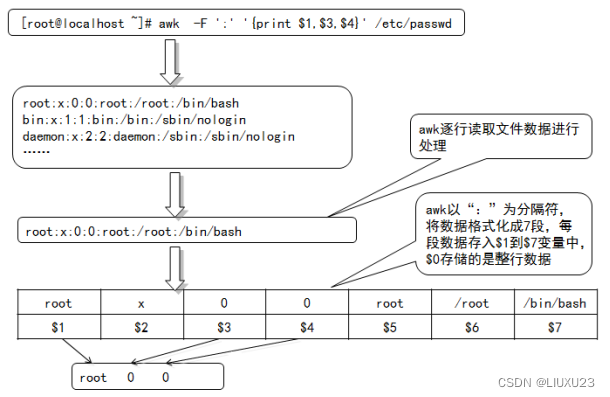
查找出/etc/passwd 的用户名、用户 ID、组 ID 等列
工作原理
内置变量
- FS:指定每行文本的字段分隔符,缺省为空格或制表位(tab)
- OFS:输入字段的分割符(默认是空格)
- NF:当前处理的行的字段个数
- NR:当前处理的行的行号(序数)
- FNR:读取文件的记录行号(从1开始,若读取新的文件依旧是从1开始)
- ORS:输出行的分割符,默认为换行符
- RS:行分隔符,根据RS的定义把资料切割成许多条记录
- $0:当前处理的行的整行内容
- $n:当前处理行的第n个字段(第n列)
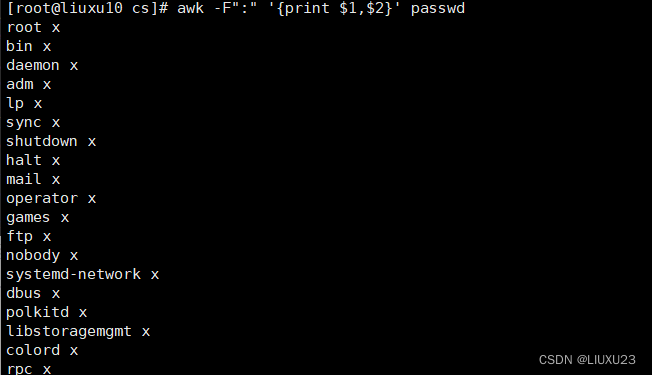
awk -F":" '{print $1" "$2}' passwd
显示一个空格,空格需要用双引号引用起来,如果不用引号,默认以变量看待,如果是常量就需要双引号引起来
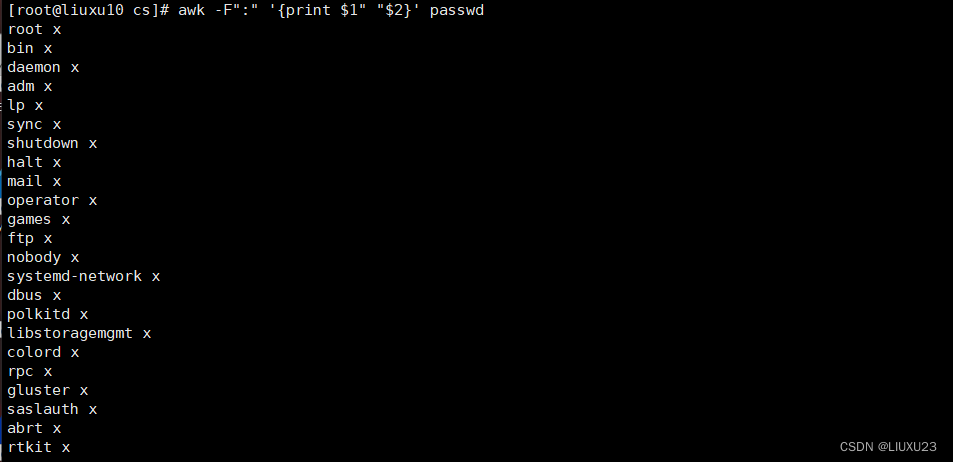
awk -F":" '{print $1,$2}' passwd
逗号有空格效果
包含root的行打印出来

模糊匹配,用 ~ 表示包含,!~ 表示不包含
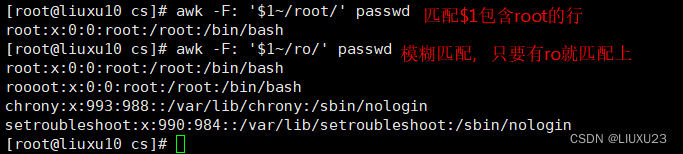
匹配root整体

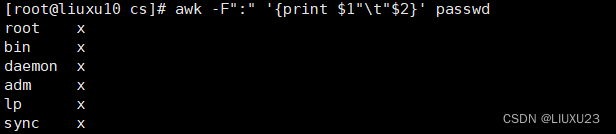
awk -F":" '{print $1"\t"$2}' passwd
用制表符作为分隔符输出
awk -F[:/] '{print $9}' passwd
[]中定义多个分隔符,只要看见其中一个都算作分隔符

awk '{print}' test.txt 输出所有内容
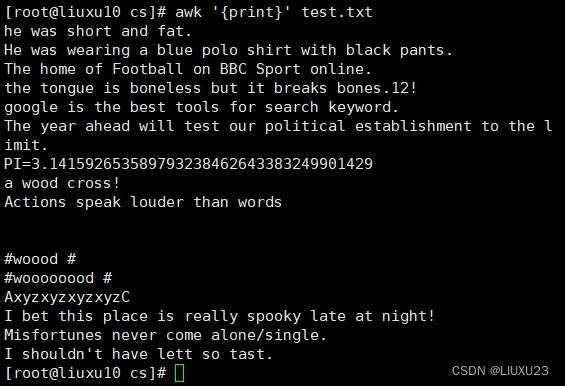
awk '{print $0}' test.txt 输出所有内容
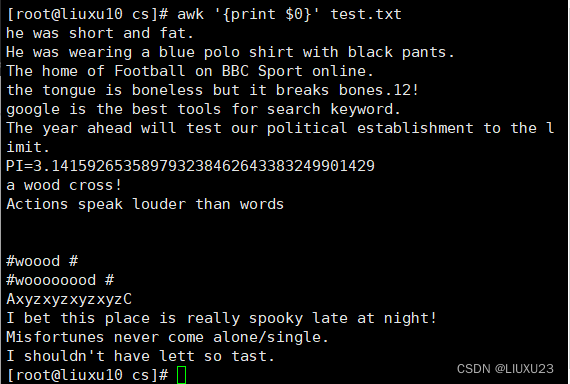
关于数组与字符串的比较
比较符号 == != <= >= < >
awk 'NR==1,NR==3{print}' test.txt 输出第 1~3 行内容

逻辑运算 && ||
awk '(NR>=1)&&(NR<=3){print}' test.txt 输出第 1~3 行内容

awk 'NR==1||NR==3{print}' test.txt 输出第 1 行、第 3 行内容

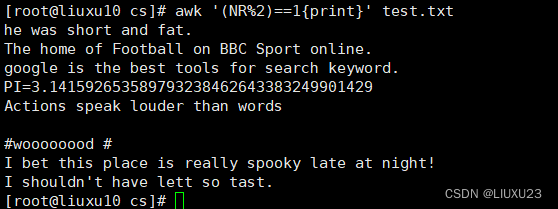
awk '(NR%2)==1{print}' test.txt 输出所有奇数行
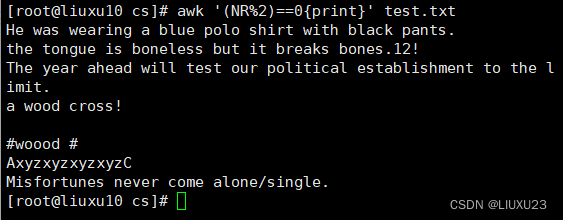
awk '(NR%2)==0{print}' test.txt 输出所有偶数行
awk 'NR==2' passwd
打印第二行,不加print也一样,默认就是打印

awk 'NR<5' passwd
打印小于五行

awk -F":" 'NR==2{print $1}' passwd
打印第二行的第一列

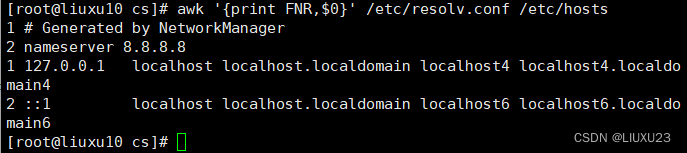
awk '{print FNR,$0}' /etc/resolv.conf /etc/hosts
FNR的行号可以追加多个文件
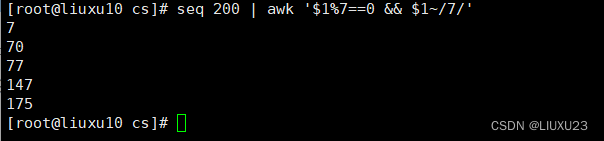
seq 200 | awk '$1%7==0 && $1~/7/'
打印1-200之间所有能被7整除的整数数字
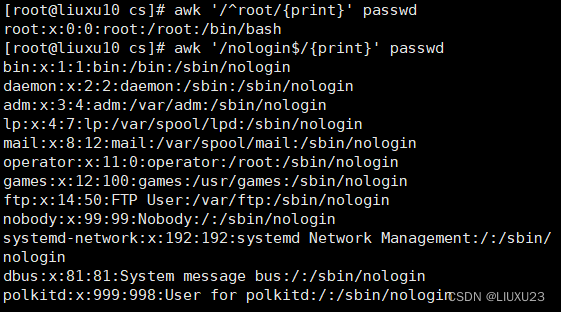
awk '/^root/{print}' passwd 输出以root开头的行

awk '/nologin$/{print}' passwd 输出以 nologin 结尾的行
网卡的IP、流量
ifconfig ens33 | awk '/netmask/{print "本机的ip地址是"$2}'
ifconfig ens33 | awk 'RX p/{print $5"字节"}'

根分区的可用量
df -h | awk 'NR==2{print $4}'

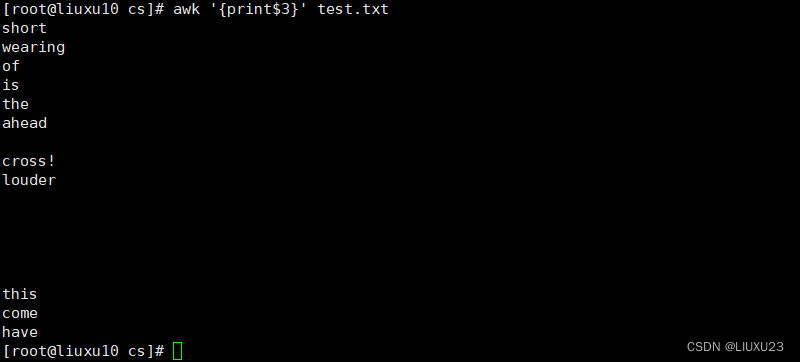
awk '{print$3}' test.txt 输出每行中(以空格或制表位分隔)的第3个字段
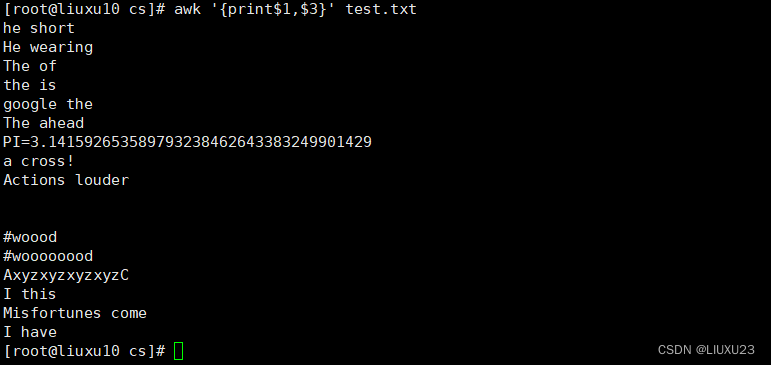
awk '{print$1,$3}' test.txt 输出每行中的第1、3个字段
BEGIN、END模块
逐行执行开始之前执行什么任务,结束之后再执行什么任务,用BEGIN、END
- BEGIN一般用来做初始化操作,仅在读取数据记录之前执行一次
- END一般用来做汇总操作,仅在读取完数据记录之后执行一次
awk的运算
awk 'BEGIN{x=10;print x}'
如果不用引号awk就当作一个变量来输出了,所有不需要加$了

awk 'BEGIN{print x+1}'
不指定初始值、初始值就为0、如果是字符串 、则默认为空

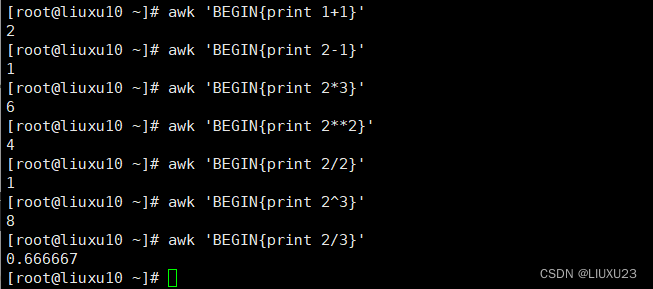
awk的运算还支持小数

awk 'BEGIN {x=0} ; /\/bin\/bash$/{x++};END {print x}' passwd 统计以/bin/bash 结尾的行数

awk 'BEGIN{RS=""};END{print NR}' test.txt 统计以空行分隔的文本段落数

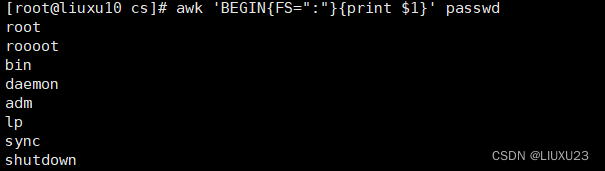
awk 'BEGIN{FS=":"}{print $1}' passwd
在打印之前定义字段分隔符为冒号
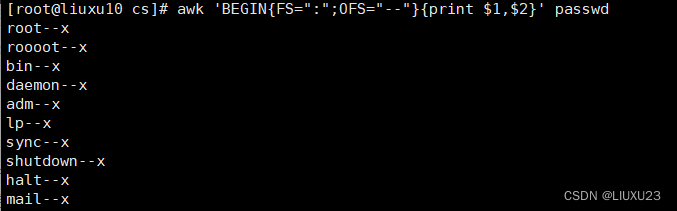
awk 'BEGIN{FS=":";OFS="--"}{print $1,$2}' passwd
OFS定义了输出时以什么为分隔,$1$2中间要同逗号分隔,因为逗号默认被映射为OFS变量,而这个变量默认是空格
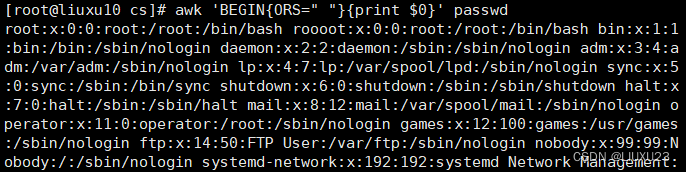
awk 'BEGIN{ORS=" "}{print $0}' passwd
把多行合并成一行输出,输出的时候自定义以空格分隔每行,本来默认是回车键
awk高级用法
定义引用变量
a=100
awk -v b="$a" 'BEGIN{print b}'
将系统的变量a,在awk里赋值为变量b,然后调用变量b
awk 'BEGIN{print "'$a'"}'
直接调用的话需要先用双引号再用单引号

awk -vc=1 'BEGIN{print c}'
awk直接定义变量并引用

调用函数getline,读取一行数据的时候并不是等到当前行而是当前行的下一行
seq 10 |awk '{getline;print $0}'

if语句:awk的if语句也分为单分支,双分支和多分支
- 单分支为if ( ) { }
- 双分支为if ( ) { }else{ }
- 多分支为if ( ) { }else if ( ) { }else{ }
单分支 awk -F: '{if(条件判断){执行的指令操作}}‘ 处理对象(文件、管道、标准输入)
双分支 awk -F: '{if(条件判断){执行的指令操作}else{执行的操作指令}}‘ 处理对象(文件、管道、标准输入)
多分支 awk -F: '{if(条件判断){执行的指令操作}else if(条件表达式2){操作指令}else{其他的操作指令}}‘ 处理对象(文件、管道、标准输入)
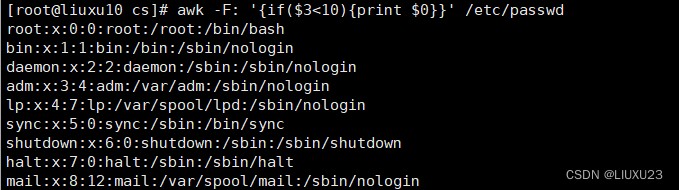
awk -F: '{if($3<10){print $0}}' /etc/passwd
第三列小于10的打印整行
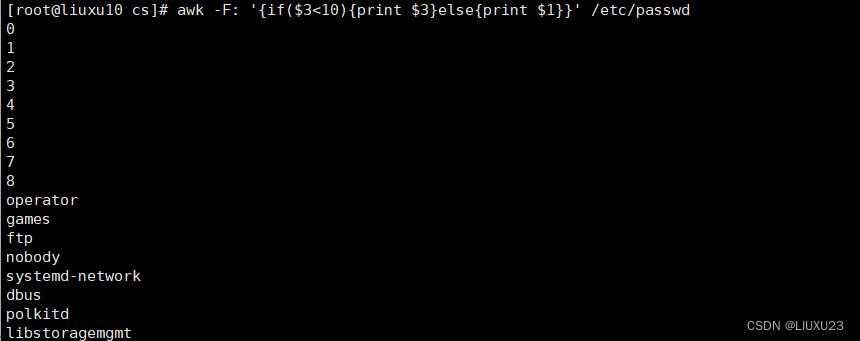
awk -F: '{if($3<10){print $3}else{print $1}}' /etc/passwd
第三列小于10的打印第三列,否则打印第一列
awk还支持for循环、while循环、函数、数组等
其他
awk 'BEGIN{x=0};/\/bin\/bash$/ {x++;print x,$0};END {print x}' /etc/passwd
统计以/bin/bash结尾的行数,等同于grep -c "/bin/bash$" /etc/passwd
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中的动作;
awk再处理指定的文本,之后再执行ENG模式中指定的动作,ENG{ }语句块中,往往会放入打印结果等语句















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









