







在java基础部分13.7学习HashMap中,没有很明白散列表的意义。今天再次学习发现,啊!!原来就是这样 懂了~
在JAVA中,散列表用链表数组实现。每个列表被称为桶,查找表中位置时,先计算元素的散列码,然后与桶的总数取余,得到的结果就是保存这个元素的桶的索引。
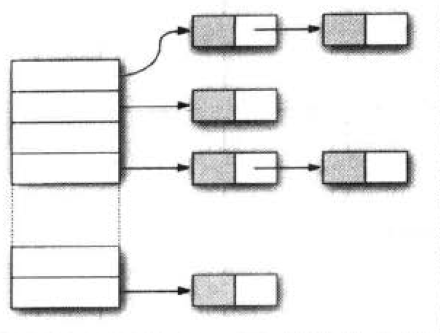
这个机制和cache-memory组相联映射机制很像:地址 = 主存块号 % 分组数。
在散列表中: 索引 = 散列码 % 桶数
如果散列表要装满了,就需要再散列,创建一个桶更多的表,并把所有旧元素插入到新表中,丢弃原来的表。装填因子决定何时对散列表进行再散列(默认为0.75)。














 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









