







 本文介绍了Java Collection框架中的Set集合,包括List子类ArrayList、Vector、LinkedList的特点以及Set子类HashSet和TreeSet的特性。HashSet基于哈希结构,保证元素唯一性,而TreeSet采用二叉树结构,可以进行排序。文章通过实例演示了如何在HashSet和TreeSet中添加元素,以及如何保证自定义对象在HashSet中的唯一性。同时,讲解了TreeSet的两种排序方式:实现Comparable接口和使用Comparator。最后,提到了Collections工具类的一些常用方法,如排序、反转和随机置换,并展示了其在模拟斗地主发牌中的应用。
本文介绍了Java Collection框架中的Set集合,包括List子类ArrayList、Vector、LinkedList的特点以及Set子类HashSet和TreeSet的特性。HashSet基于哈希结构,保证元素唯一性,而TreeSet采用二叉树结构,可以进行排序。文章通过实例演示了如何在HashSet和TreeSet中添加元素,以及如何保证自定义对象在HashSet中的唯一性。同时,讲解了TreeSet的两种排序方式:实现Comparable接口和使用Comparator。最后,提到了Collections工具类的一些常用方法,如排序、反转和随机置换,并展示了其在模拟斗地主发牌中的应用。
Collection体系:
|–List——特点:元素有序(指的是元素的存入和取出的顺序一致),元素可重复
–||–ArrayList——特点:底层是数组结构,查询快,增删慢;线程不同步,效率高
–||–Vector——特点:底层是数组结构,查询快,增删慢;线程同步,效率低(基本上已经被ArrayList替代)
–||–LinkedList——特点:底层是链表结构,增删快,查询慢;线程不同步,效率高
|–Set——特点:元素无序(指的是元素的存入和取出的顺序有可能不一致),元素唯一
–||–HashSet——特点:底层是哈希结构,线程不同步,无序,高效
–||–TreeSet——特点:底层是二叉树结构,线程不同步,可以对Set集合中的元素进行指定顺序的排序。(自然顺序或自定义排序)
前面已经学过了Collection体系中的List的实现子类了,今天将学习到的Set的实现子类以及一些重要的知识点总结一下
学习集合体系的标准:学习顶层,使用底层
在Set体系中,有两个实现子类:HashSet和TreeSet
首先,来学习一下Set这个顶层所具备的功能
通过查询API,我发现,Set体系中定义的功能完全和Collection中定义的功能一致,因此,就不在这里赘述了,直接使用:
学习Set集合无非是学习:
1、创建一个集合
2、创建元素对象
3、往集合里添加元素
4、遍历
A:迭代器
B:增强for
创建一个Set集合的方法,由于Set是一个接口,不能通过new来新建对象,我们可以通过下面三种方式来创建一个Set集合
// 创建集合对象
Collection<String> c = new HashSet<String>();
Set<String> set = new HashSet<String>();
HashSet<String> hs = new HashSet<String>();以上三种方法,都可以创建一个Set的集合
由于,set体系中的方法和Collection中定义的方法一样,那么我们现在直接来走一遍学习集合的流程
创建集合、创建元素、添加元素、遍历
代码如下:
public class SetDemo {
public static void main(String[] args) {
// 创建集合对象
Set<String> set = new HashSet<String>();
// 创建并添加元素
set.add("hello");
set.add("world");
set.add("java");
set.add("world");
// 迭代器遍历
Iterator<String> it = set.iterator();
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
System.out.println("--------------");
//增强for遍历
for (String s : set) {
System.out.println(s);
}
}
}结果:
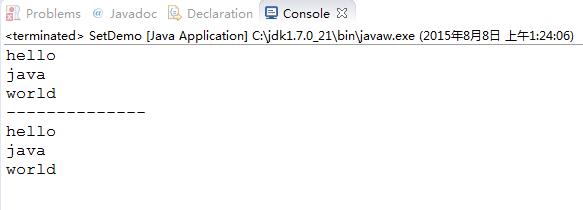
从结果可以看出,1、我们存储元素的顺序和取出来的顺序是不同的,这就印证了Set体系中的集合的元素是无序的
2、在程序中,我们添加了两个“world”字符串,但是在遍历的时候却没有两个“world”,这印证了Set集合中的元
素是唯一的。后面学习的HashSet和TreeSet会详细分析保证元素唯一是如何实现的。
HashSet是Set体系中的一个子实现类
特点:特点:底层是哈希结构,线程不同步,无序,高效
HashSet集合保证元素唯一性:通过元素的hashCode方法,和equals方法完成的。
当元素的hashCode值相同时,才继续判断元素的equals是否为true。
如果为true,那么视为相同元素,不存。如果为false,那么存储。
如果hashCode值不同,那么不判断equals,从而提高对象比较的速度。
HashSet存储字符串并遍历
public class HashSetDemo {
public static void main(String[] args) {
// 创建集合对象
HashSet<String> hs = new HashSet<String>();
// 创建并添加元素
hs.add("hello");
hs.add("world");
hs.add("java");
hs.add("java");
// 遍历
for (String s : hs) {
System.out.println(s);
}
}
}结果:
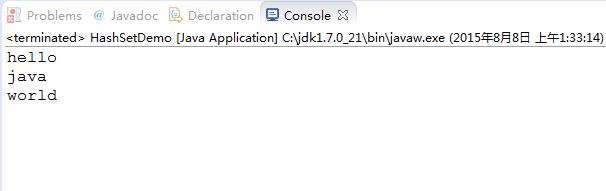
分析:
在HashSet中添加了两个“java”元素,但是输出来只有1个,是因为String类实现了hashCode()和equals()方法。
那么,现在问题来了,当我们要存储自定义的对象时,该如何保证HashSet中元素的唯一性呢?
我们都知道,当我们new出来多个对象时,往HashSet中添加时,每个对象的地址值都是不同的,那么就算我们有两个属性一模一样
的对象,HashSet仍然认为是两个不同的对象,但是现实生活中,我们就认为这是同一个对象,其中一个不应该添加进HashSet集合中。
图解HashSet保证元素唯一性:

上面我们说过,在HashSet里面,是通过元素(也就是我们现在的对象)hashCode()和equals()方法来保证元素的唯一性。那么我们该如何来实现这两个方法呢?
通过观看原码,我们发现这是一个相当复杂的过程,但是IDE给我们提供了最大的方便,可以一键生成hashCode()和equals()方法。在开发中,我们只需要自动生成就好了。
那么现在,我们现在来看一下,在没有实现这两个方法的时候,HashSet是不能保证元素唯一的情况
Student.java
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
HashSetDemo.java
public class HashSetDemo2 {
public static void main(String[] args) {
// 创建集合对象
HashSet<Student> hs = new HashSet<Student>();
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









