






rabbitmq是高性能的异步通信
异步与同步的区别
同步:发送一个确认一个,实时,无法与多个进行联系
异步:随机发送随机确认,非实时,可以与多个进行联系
异步的实际例子:微服务之间的同步调用就是利用openfeign进行调用,openfeign是同步的,当其他没有服务的时候会进入阻塞状态
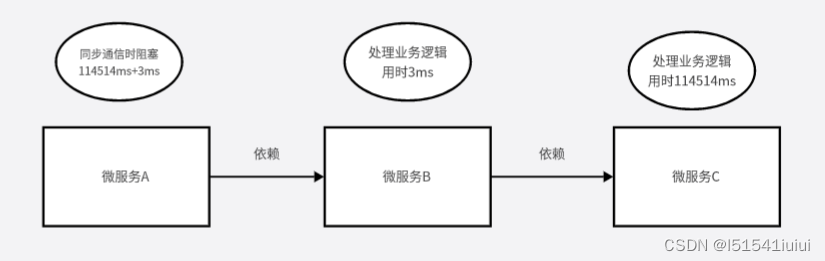
同步例子:当应对高并发的时候,b依赖于a,c依赖于b(a是登陆,其他微服务都依赖于登陆,c服务功能无关紧要),如果c阻塞时间过长,a也会跟着阻塞,导致等待时间过长,导致a阻塞时间过长,就像下图一样:
同步调用的优点:
有些业务不得不同步调用,可能存在原子性问题,同步可以保证原子性
时效性强,可以及时等到结果(查询商品的时候,需要找到产品才能进行下一步)
同步调用的缺点:
各个微服务之间耦合严重,拓展性差
由于等待是占用,在等待的时候也在占用cpu,性能较差
可能存在级联失败问题(一个微服务错误导致全部应用崩盘,错误会在微服务之间传递)
异步例子在高并发场景中,不着急去做b,c,而是需要快速的让a完成,这时引用消息队列(Massage Queue,mq)这个mq是消息代理,接受消息发送者(发送消息的人)的消息传递给消息接收者(需要处理消息的人),让a发一个消息给b,之后在做别的,就剩取了其他的阻塞对a的影响
如下图所示
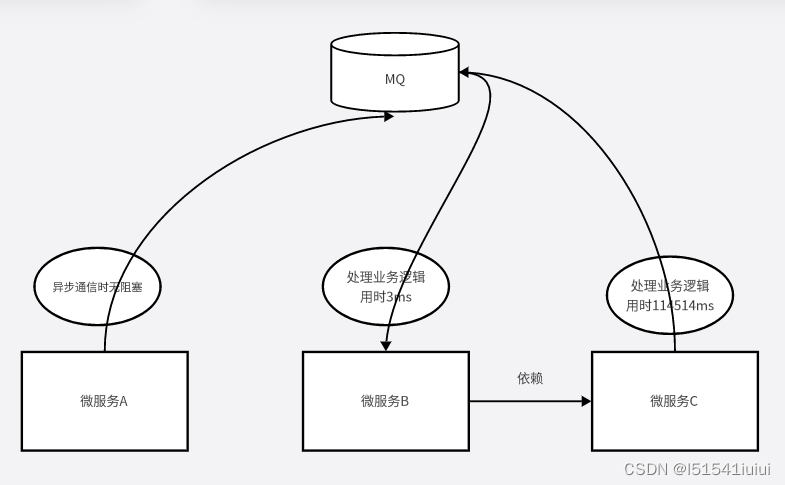
导致并发工程中,并发特别快(适用于对后续成功和失败不太关心的场景,调用链超长的场景)
异步调用的优点:
接触耦合高拓展:对消息进行解耦(送外卖于送快递的区别),比如bcd都需要接受a的消息,在同步需要每个都发送,但是在异步里可以使用消息广播的方式解耦
无需等待性能好:把不太重要,不需要原子性的业务抽离出来,防止这些无关紧要的业务阻塞影响重要业务的性能
故障隔离:其他微服务发成故障时不会传递给主要为服务,解决了故障传递的问题
缓存消息,防止过多的消息同时涌入导致服务崩盘(把庞大的业务慢慢解决)
异步调用的缺点:
不能立刻得到结果,时效性差
不确定下游业务是否执行成功
业务的安全过分依赖于代理(brocker)的可靠性
当我们用到异步调用的时候,就需要找到一个消息代理(brocker),所以进引用了MQ技术
MQ技术选型
MQ(MessageQueue),中文是消息队列,字面意思就是存放消息的队列,也就是异步调用(上文)中的brocker,我们给出几个常见的MQ

erlang是面向并发的语言
安装启动mq
直接启动rabbitmq 我们访问网站进入管理界面(默认密码初始密码guest,guest)
我们访问网站进入管理界面(默认密码初始密码guest,guest)
进入rabbitmq的管理界面
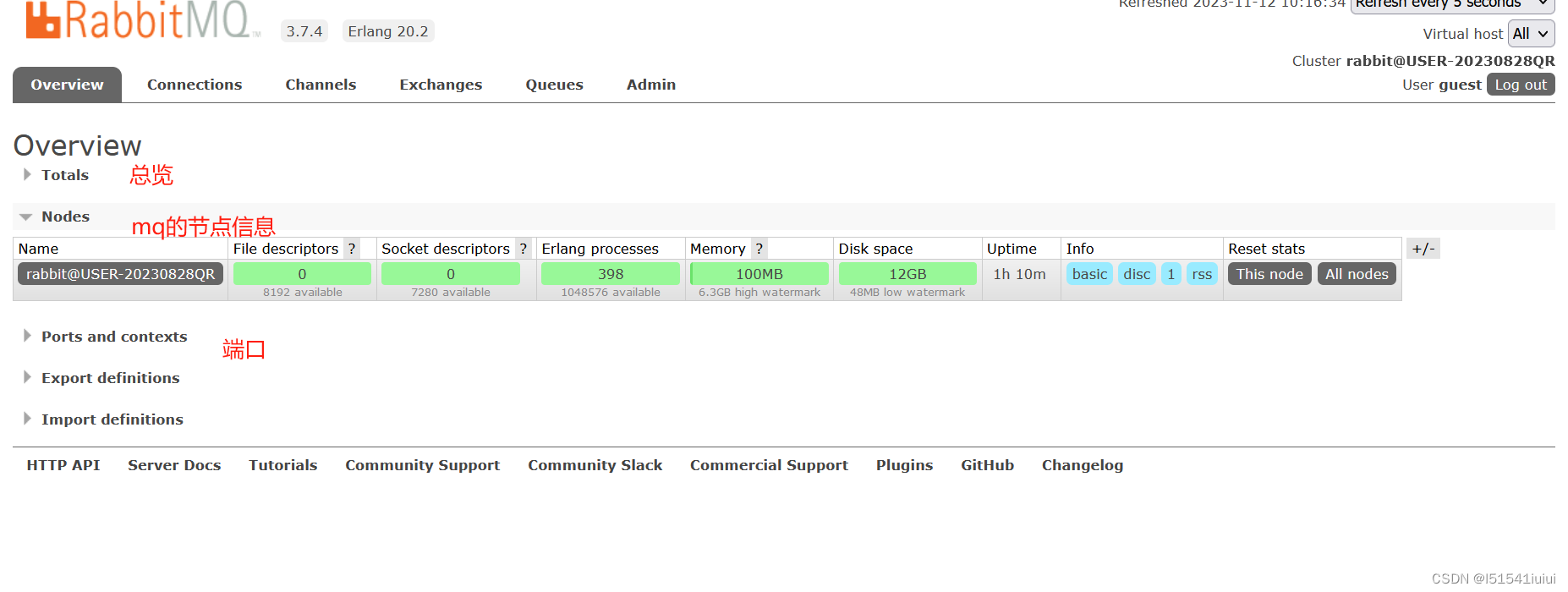
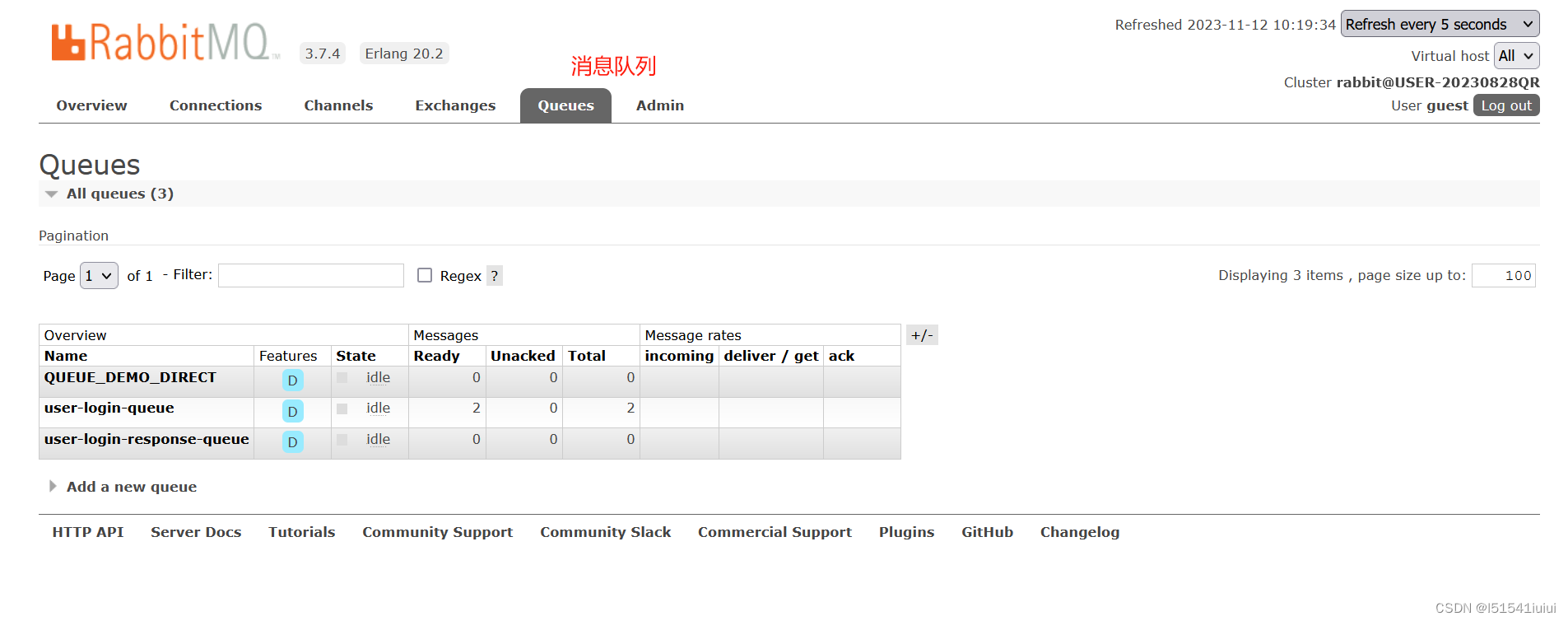
这里我们介绍一下rabbitmq的核心知识点概念
rabbitmq核心概念及其架构
1.publisher:消息的发送者
2.consumer:消息的消费者
3.queue:队列,用来存储消息
4.exchange :路由,用来负责路由消息
可以看下面的图片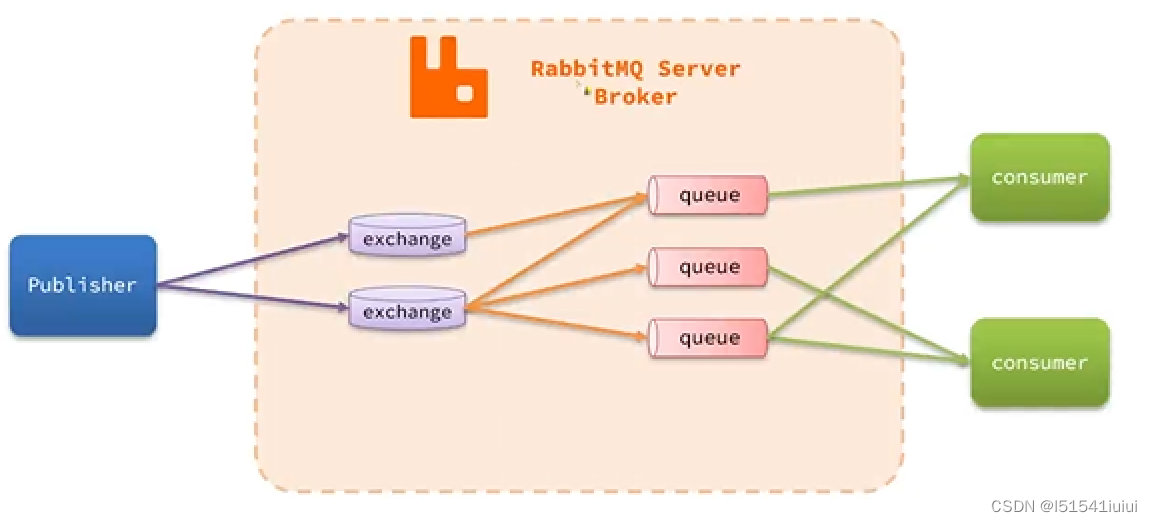
java rabbitmq的使用demo1,helloworld
1.创建队列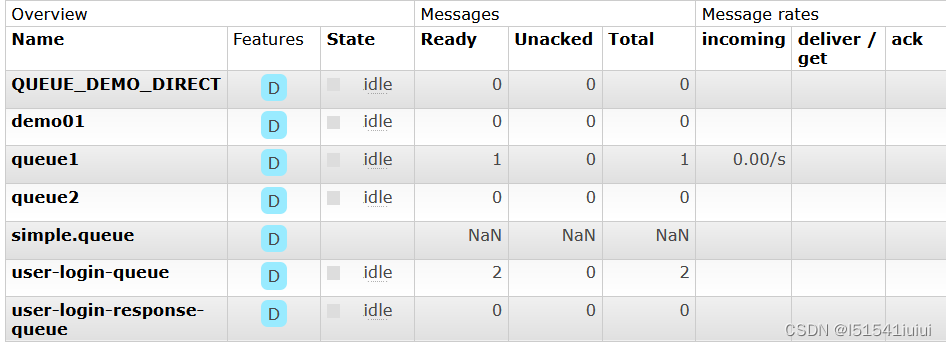 2.发送消息
2.发送消息
写出如下代码:
 首先访问对应requestmapping
首先访问对应requestmapping
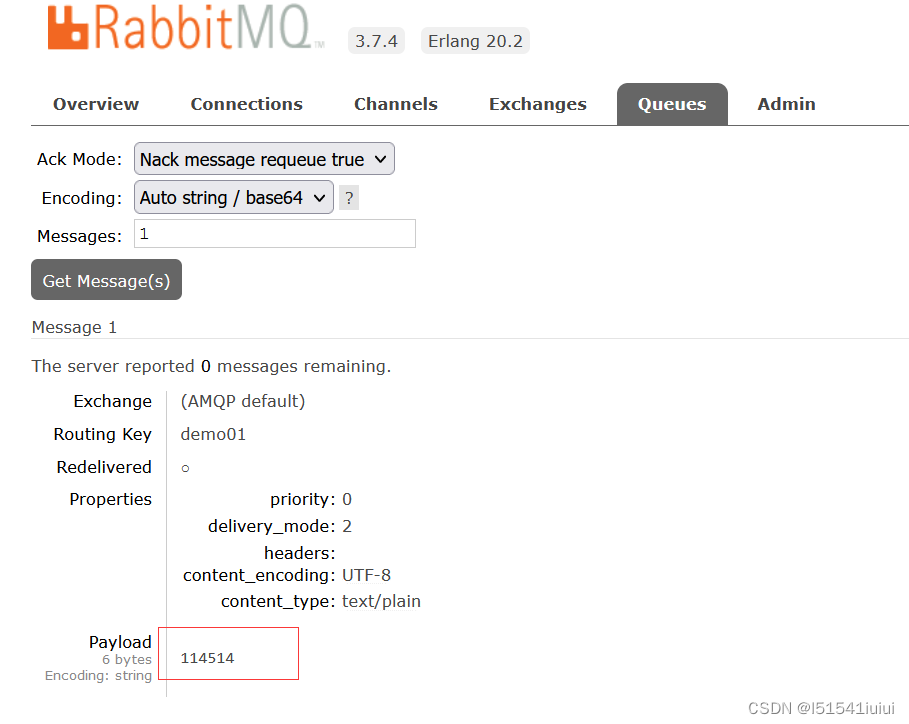
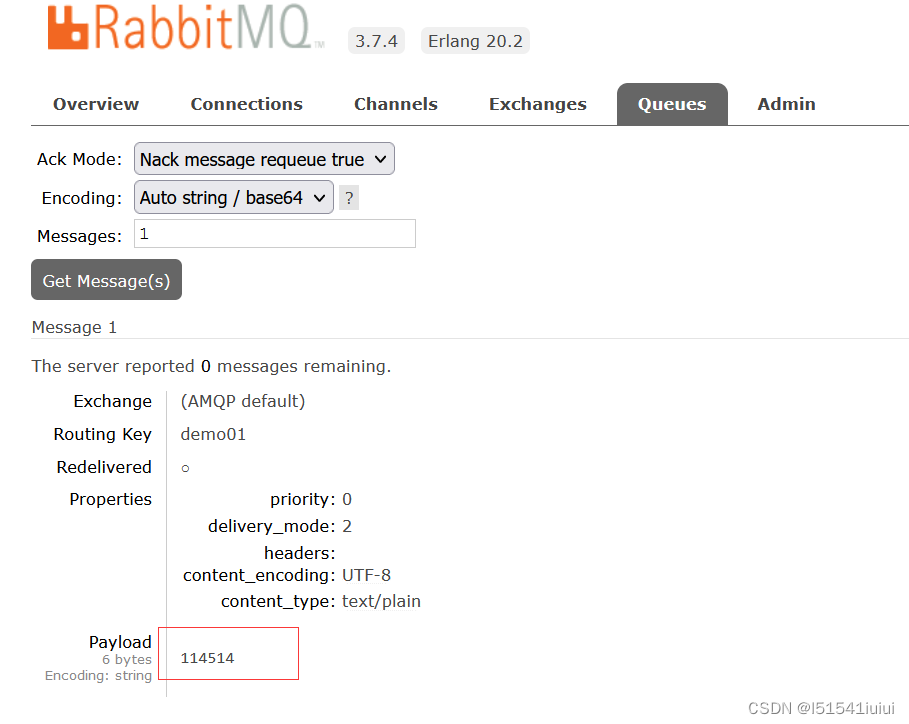
 可以看到成功处理业务罗技,接下来我们访问我们的管理界面,可以看到队列中有一条消息
可以看到成功处理业务罗技,接下来我们访问我们的管理界面,可以看到队列中有一条消息
 添加监听者
添加监听者
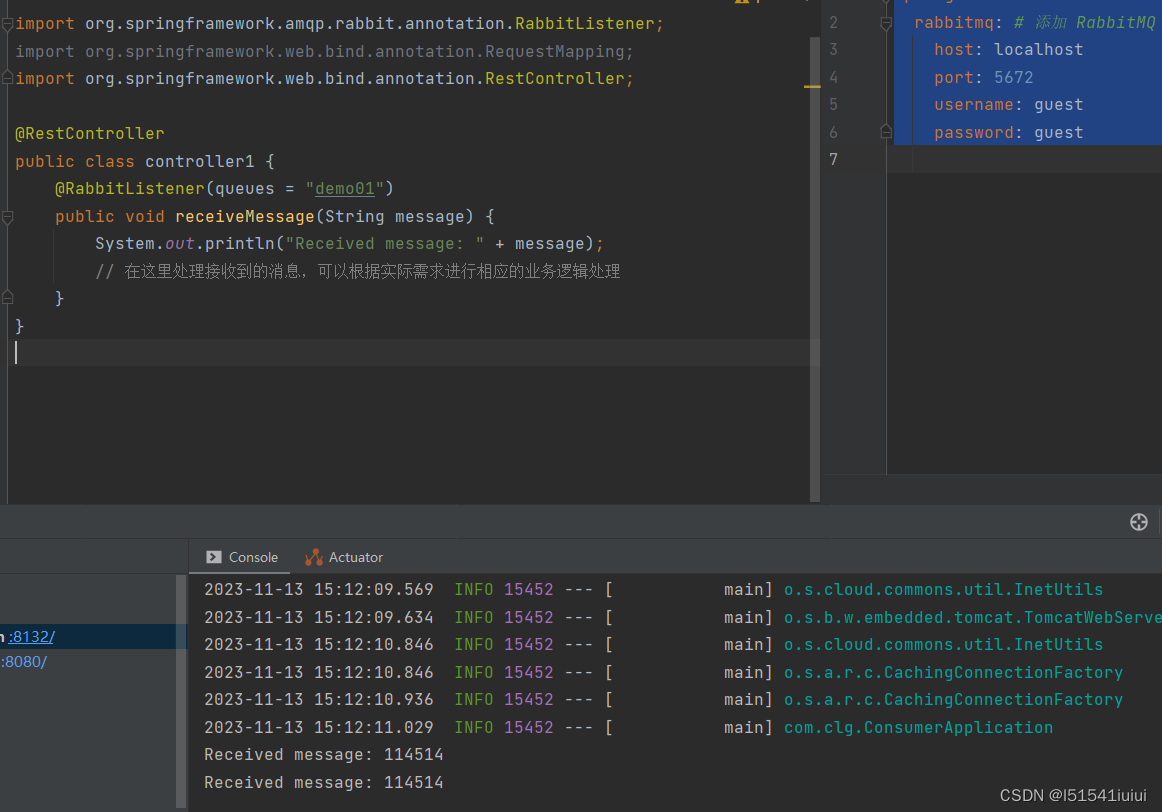 可以看到接收到了信息
可以看到接收到了信息
java rabbitmq的使用demo2,在微服务之间调用rabbitmq实现消息的传递
业务分析:
当用户调用微服务sys时,微服务sys通过rabbitmq将当前用户信息交给微服务record进行处理,
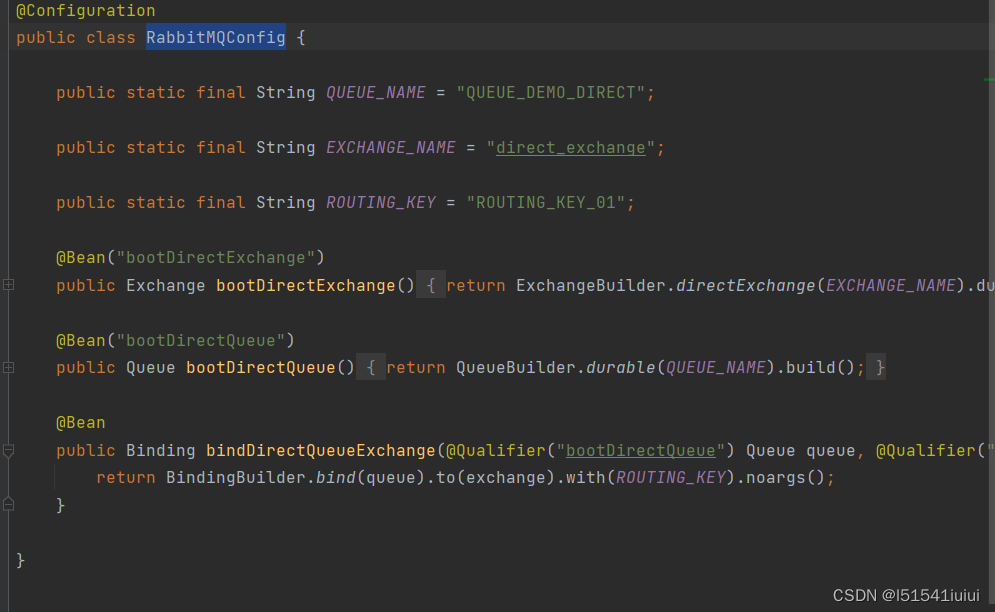
 在RabbitMQConfig利用configuration于bean定义了自定义了自己的config文件
在RabbitMQConfig利用configuration于bean定义了自定义了自己的config文件
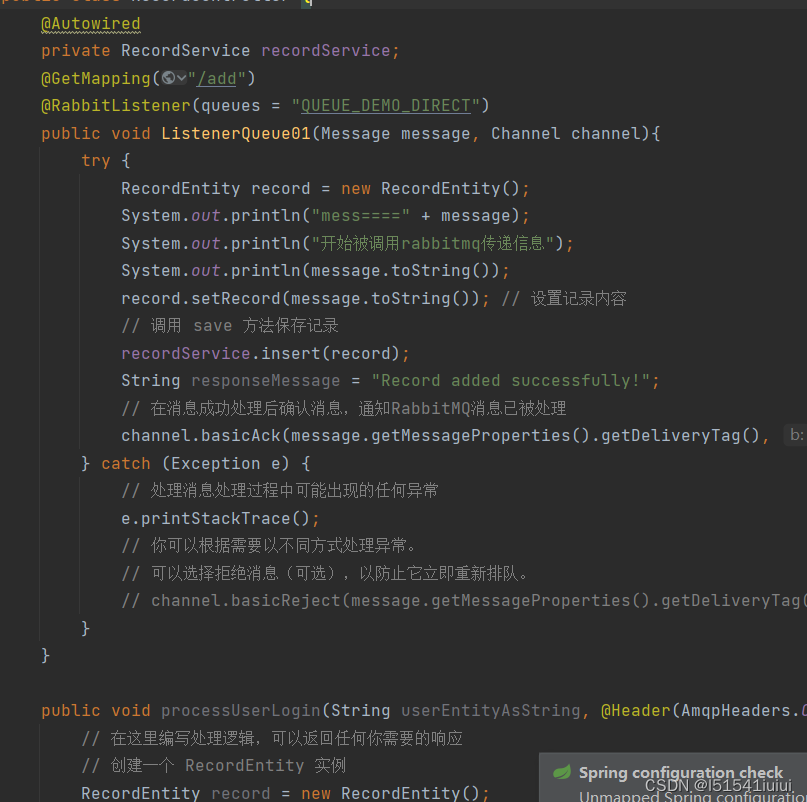
 在record中进行接受
在record中进行接受
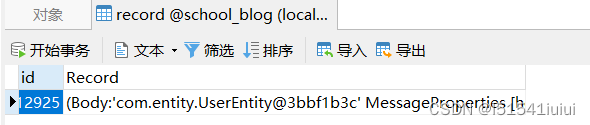
 ,查看数据库,可以看到成功保存了信息
,查看数据库,可以看到成功保存了信息
RabbitMQ交换机概念
上面的demo1,使用的队列直接交换信息,这可能会导致一个问题:
问题一:没有交换机的情况下,消息的路由方式将受限于生产者直接将消息发送到特定的队列。这样可能导致消息只能按照一种固定的方式进行路由,缺乏灵活性(消息只能走固定的队列或者路径)
问题二:在没有交换机的情况下,系统的拓展可能会受到限制,因为生产者和消费者的关系比较紧密,系统的修改和升级可能会变得更加困难(先前的队列路径消息都是定义好的,没有方法拓展)
因此,rabbitmq引入了交换机的概念,交换机有如下好处
解耦生产者和消费者: 通过引入交换机,生产者可以将消息发送到交换机,而不直接发送到特定的队列。这使得生产者和消费者之间的关系更为灵活,它们可以独立演进,而不需要了解对方的存在。这种解耦使得系统更容易扩展和维护。
消息路由: 交换机允许定义消息的路由规则,可以根据不同的条件将消息发送到一个或多个队列。这种能力使得系统能够更灵活地根据消息的内容、属性或其他标准进行分发。
消息分发: 不同类型的消费者可能对同一消息有不同的处理方式。交换机可以根据消息的类型将其分发给相应的队列,从而确保消息被正确处理。
在引入了交换机之后,信息交换的模型就变成了下面这种
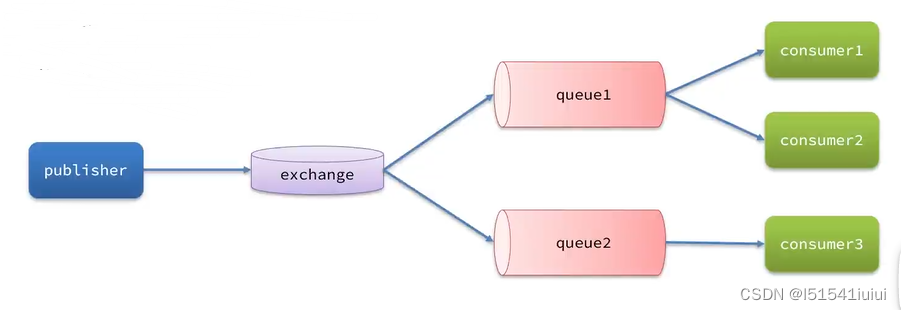 不用管怎么到达consumer的,只需要指定consumer,寻址路由交给交换机进行
不用管怎么到达consumer的,只需要指定consumer,寻址路由交给交换机进行
rabbit的三种交换机
1.fanout交换机
广播交换机,广报到每一个与此交换机连接的queue,但是fanout交换机存在消息过于冗余,无法按条件过滤消息,不支持灵活的消息路由规则,性能考虑
2.Direct交换机
根据规则指定路由到指定queue
其中,规则为
1.每一个queue都与交换机设置一个bindingkey,
2.发布者发布消息是,指定routingkey
3.交换机比较两个key,发送到bindingkey==rountingkey的队列
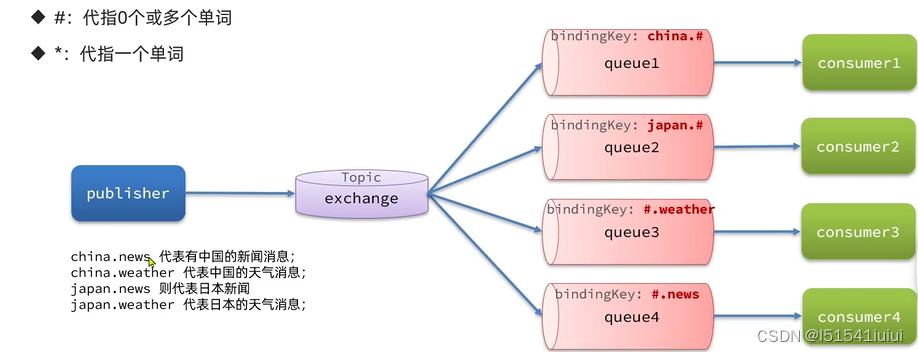
3.Topic交换机
与direct交换机类似,但是topic交换机的routingkey可以是多个单词的列表,并且以。分割
例如下图
用java声明队列与交换机(queue,exchanges)
传统意义下用控制台生成队列和交换机,不太可能,因为后来的实际生产环境交换机和队列往往数量过大,不利于维护,因此可以把需要的交换机在代码中生名,防止其他人员运行这个环境的时候出错
springAMQP提供了几个类,用来声明队列,交换机及其绑定关系
| 类型 | 对应工厂类 | 关系 |
|---|---|---|
| queue | queuebuilder | 声明队列 |
| exchange | exchangebuilder | 声明交换机 |
| binding | bindingbuilder | 声明交换机与队列的绑定关系 |
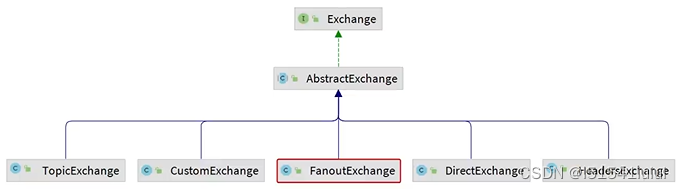
如下图,我们可以看到,这些交换机都是来自于exchange接口,继承了exchange的抽象类
对于交换机,队列,绑定, 我们往往采用configuration与bean注解来声明他们,如下面的代码所示(注意,声明往往都是在消费者端声明的)
@Configuration
public class FanoutConfig {
// 声明 FanoutExchange 交换机 Bean
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("hmall.fanout");
}
// 声明第1个队列 Bean
@Bean
public Queue fanoutQueue1() {
return new Queue("fanout.queue1");
}
// 绑定队列和交换机 Bean
@Bean
public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
// ...略,以相同方式声明第2个队列,并完成绑定
}
上面的代码也不够灵活,应为需要声明多个dircetexchange的时候往往需要写多个bean,因此提出了依赖注解进行开发的下一种方式
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue1(String msg) {
System.out.println("消费者1接收到Direct消息:["+meg+";");
}
MQ的可靠性问题
在使用了mq的场景,如果场景出现问题,可能会出现如下状况
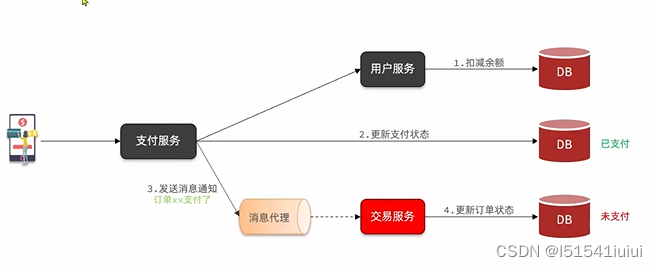 当如下场景,支付服务完成,就发出一个更新订单状态的mq,但是这个mq挂掉了,明明付了钱,却没有更新订单装态(支付失败),因此需要保证mq的可靠性问题(保证消息发出以后至少被消费一次)
当如下场景,支付服务完成,就发出一个更新订单状态的mq,但是这个mq挂掉了,明明付了钱,却没有更新订单装态(支付失败),因此需要保证mq的可靠性问题(保证消息发出以后至少被消费一次)
完成整个逻辑,至少要保证三个可靠
可靠1:发送者发送信息必须是可靠的(我得保证我一直发送,不能说你失败了我就不发了)
可靠2:消息队列mq必须是可靠的
可靠3:消费者服务必须是可靠的(我得保证我及时给你一个我处理成没成功的确认,不然你都不知道我成没成功)
当三个方案都失败了,只能启用服务降级(延迟消息)
发送者(消息生产者)可靠性保证
有时由于网络波动问题,可能会出现客户端连接mq出现失败的情况,(即mq无法接受生产者发来的msg),
这种情况下,可以通过配置生产者定时重连机制,办证生产者可靠性(连接失败的重试)
当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试(卡在那里的不停等待),也就是说多次重试等待的过程中,当前线程是被阻塞的,会影响业务性能。
如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
配置重连机制需要配置对应springboot的yml文件
spring:
rabbitmq:
connection-timeout: 1s # 设置AQ的连接超时时间
template:
retry:
enabled: true # 开启超时重试机制
initial-interval: 1000ms # 失败后的初始等待时间
multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长= initial-interval * multiplier
max-attempts: 3 # 最大重试次数
生产者发送消息失败的判定:确认机制
生产者是如何知道自己发送消息失败了呢,rabbitmq提出了确认机制(confirm和return)
对于投递成功的场景,分为三种(两种不需要重传):
mq会给生产者发送一个确认信息(ack)
1.发送持久化消息,成功入队并且完成持久化返回ack,
2.发送非持久化消息,成功入队,返回ack
3.publisher return机制:
消息传递到mq,但是mq后续的路由失败了,需要生产者再次发出一次消息(调用重传机制),这时候publisher return返回路由异常原因,并且返回ack,告知这次消息投递成功(只不过后续的路由失败了,重传是我路由的问题,不是我的问题,我把问题告诉你)(基本不会出现,要么是代码有问题,或者binding有问题)
其他情况,都会返回nack(如,磁盘爆满,内存爆满),进行消息重传
生产者重传机制的实现:回调函数
我们在代码中,首先开启重传机制
对于return callback,可以写出如下的唯一代码:
在configuration中继承applicationcontextaware(spring容器的通知方法:当容器完成了加载这个configuration)生成一个配置类,利用applicationcontext获取rabbittemplate的单例bean或者autowired直接注入推荐,重写其中的setreturncallbanck机制,编写回调函数,如下代码
@Configuration
public class CommonConfig implements ApplicationContextAware {
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
log.info("消息发送失败,应答码[{}], 原因[{}], 交换机[{}], 路由键[{}], 消息[{}]",
replyCode, replyText, exchange, routingKey, message.toString());
});
}
}
对于confirmcallback,需要对每一个发送消息的方法一 一指定(在方法内新建correlationdata对象,通过掉哦那个addcallback进行重传,如下图所示)
@Test
void testPublisherConfirm() throws InterruptedException {
// 卫.创ICorrelationDota
CorrelationData cd = new CorrelationData(;;e人//2给Future添加Confirmcollback
cd.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() {
@Override
public void onFailure(Throwable ex) {
// 2.1.Future发生异常时的处理逻却,基本不会触发
log.error("handle message ack fail", ex);
}
@Override
public void onSuccess(CorrelationData.Confirm result) {
// 2.2.Future投收到每执的处理逻辑,参数中的result就是函执内容
if (result.isAck()) {
// result.isAck(), boolean类型, true代表ack回执,false代表nock回执
log.debug("发送消息成功,收到ack!");
} else {
// result.getReason(), String类型。返闯hack时的异常擂述
log.error("发送消息失败,收到nack,reason: (" + result.getReason() + ")");
}
}
});
// 3.发送漪息
rabbitTemplate.convertAndSend("hmall.direct", "red1", "hello", cd);
}
MQ的可靠性
mq可能会发生数据丢失(mq默认吧数据保存到内存当中,好处是性能好,坏处是容易出现消息丢失)
内存有限,可能导致内存堆积,这时候mq会自动执行数据迁移(page out ,将一些信息放入硬盘之中,这个过程是阻塞的),在迁移的过程中可能发生数据丢失
解决方案
数据持久化
1.在配置队列,交换机的时候,可以选择将属性设置为transient,保证持久化(在spring中创建的队列交换机,默认都是持久化的)
2.消息持久化:发送的消息修改为持久化(发送消息,2默认为持久,1默认为临时),在代码中可以设置发送消息的delivermode为persistent,代码如下所示
void testPageout() {
Message message = MessageBuilder
.withBody("hello".getBytes(StandardCharsets.UTF_8))
.setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT)
.build();
rabbitTemplate.convertAndSend("simple.queue", message);
}
但是当发生数据迁移的过程中,可能发生性能下降
2.改变队列结构(lazy queue)
惰性队列:特征如下
1.接收消息不是直接保存在内存,而是先保存在磁盘,在从磁盘中读取到内存
(内存只中保留2048条),速度在大多数情况没有影响,只有在大量数据时才会降低一点点,最新版本默认都是lazyqueue模式
2.支持大量数据进入队列
要设置一个队列为惰性队列,只需要在生命队列时,指定xqueuemode为lazy即可
在代码中,可以在构建队列时添加方法,实例如下所示
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.QueueBuilder;
public class MyQueueBean {
public Queue lazyQueue() {
return QueueBuilder
.durable("lazy.queue")
.lazy()
.build();
}
}
或
aRabbitListener(queuesToDeclare = @Queue(
name = "lazy.queue" ,
durable = "true",
arguments = @Argument(name = "x-queue-mode",value = "lazy")
)
public void listenLazyQueue(String msg){
log.info("接收到lazy.queue的消息:{",msg);
消费者的可靠性
消费者的确认机制
既然消费者可以传回回执,说明消费者已经返回了一个处理装态,对于消费者返回的确认信息,一共有三种
1.ack:说明消息处理成功,mq可以从队列中删除该消息了
2.nack:说明消息处理失败,mq需要重新发送消息(具体失败在哪里不管,你就是得给我重传消息)
3.reject:消息处理失败并拒绝该消息,mq删除该消息(这消息我用不上,有问题,别给我发了,生产者收不到ack,继续发)
对于这个确认状态该怎么发送,spring框架已经集成了,如果消费者执行这个业务成功,spring调用消息处理罗技,如果罗技成功,自动返回ack,如果逻辑发生异常,发送nack,reject(按照exception进行区别)
极端情况下的失败处理机制
当nack时,会把消息不断地重传到mq中,这可能会带来不必要的压力
为了应对这种情况,通常会引入一些补救措施,以确保系统在面对消息处理失败时不会无限制地重试。一些可能的补全策略包括:
重试次数限制: 设置一个最大重试次数,当消息达到该次数后,停止进一步的重试。这有助于防止无限制的重传。
延迟重试: 在每次重试之间引入延迟,逐渐增加重试间隔。这可以减轻系统压力,并给出可能导致处理失败的问题更多的时间解决。
指数退避: 采用指数退避的方式,即在每次失败后,将重试间隔乘以一个增长因子。这可以在初始阶段进行更频繁的重试,然后随着时间的推移逐渐减少重试频率。
死信队列(DLQ): 将无法成功处理的消息移动到死信队列,而不是无限制地重试。这样可以让系统管理员或开发人员检查和处理这些失败的消息。
消费者业务的幂等问题
在项目的实际生产环境中,消费者消费消息一共消费几次呢,(重试机制的存在,比如网络波动,可能存在消费者消费成功,但是我们认为没有消费成功,(投递成功,但是没有收到ack,可能进行重发))导致一个消息被投递多次,出现问题
在这种情况下,需要保证消费的幂等
幂等
幂等是一个数学概念,用函数表达式来描述是这样的:f(x)=f(f(x))。在程序开发中,则是指同一个业务,执行一次或多次对业务状态的影响是一致的。(一个函数,对他执行无限次操作,对状态不发生改变)
天生幂等的任务:
查询任务(差一次和差100次没区别)
删除任务(删一次和删100次没区别,都是把那个删除了)
非幂等任务:
下单(需要扣用户钱,减小库存并发货(前后不幂等,扣了一次钱发了多个货))
退款(需要返回商品,并且将钱退回)(前后不幂等,退了一次商品,退了多份钱)
但是,所有的任务都需要保证幂等行(同一个业务被调用多次,每一次都与每一次一样)
解决幂等的方法1:添加消息的唯一标识符
我们可以给消息加一个唯一的id,在发送消息时,携带这个id,在处理业务时,保存到消费者的自带数据库,当下次收到消息时,如果发现数据库内id存在,说明是重复消息,不进行处理
下面代码就是一个实例,在配置类里定义自动创建消息id
public MessageConverter messageConverter() {
// 1. 定义消息转换器
Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter();
// 2. 配置自动创建消息id,用于识别不同消息
// 也可以在业务中基于ID判断是否是重复消息
jjmc.setCreateMessageIds(true);
return jjmc;
}
在消费者中定义这段代码,用来检查是否添加消息的唯一标识付
@Override
public final Message toMessage(Object object,
@Nullable MessageProperties messagePropertiesArg,
@Nullable Type genericType)
throws MessageConversionException {
MessageProperties messageProperties = messagePropertiesArg;
if (messageProperties == null) {
messageProperties = new MessageProperties();
}
Message message = createMessage(object, messageProperties, genericType);
messageProperties = message.getMessageProperties();
if (this.createMessageIds && messageProperties.getMessageId() == null) {
messageProperties.setMessageId(UUID.randomUUID().toString());
}
return message;
}
使用添加消息标识符的方法可能存在一些问题,比如:由于涉及到访问业务的数据库,对业务有了侵入,访问数据库,写数据库存在时间问题等等
解决幂等的方法2:基于业务本身判断是否幂等
我们要在支付后修改订单状态为已支付,应该在修改订单状态前先查询订单状态,判断是否未支付,只有未支付的订单才需要修改,其他的状态不做处理(加一层判断)
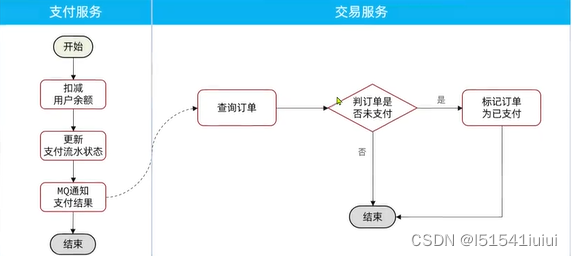 (注意:在实现判断时,可以通过数据库update语句加乐观锁的机制实现多业务之间的并发问题)
(注意:在实现判断时,可以通过数据库update语句加乐观锁的机制实现多业务之间的并发问题)
mq的延迟消息
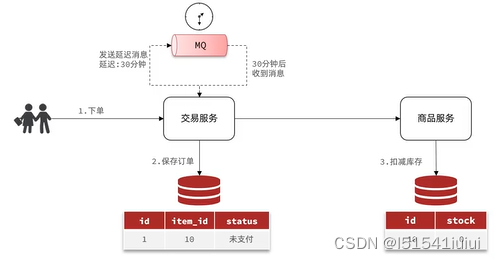
当实际生产开发中,可能存在如下的业务需求
:生产者发送消息时指定一个时间,消费者不会立即收到消息,而是指定事件之后才收到消息(下单是瞬间完成的,但是付款是延迟的,下单后的第三十分钟进行一次查询有没有调用支付,没有直接取消)
延迟消息实现了上面的功能
延迟消息的第一种实现:死信交换机
死信
当消息队列满足下列一种情况时,就会成为死信:
1.消费者使用basic.reject或者basic.nack声明这个消息消费失败了,并且此时消息的requeue参数为false
2.消息是一个过期消息,超时无人消费
3.要投递的消息队列信息堆满了,最早的消息可能变成私信
死信交换机(用来接收死信的交换机)
如果队列通过dead-lettter-excahge属性制定了一个交换机,那么队列中的死信就会投递到这个交换机中,这个交换机就叫死信交换机(DLX)
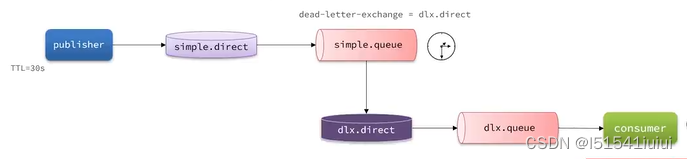 通过添加死信交换机的方式可以设置出延迟的效果(但是官方的本来目的是为了让你处理死信消息的,你却用来处理延迟消息,不好)
通过添加死信交换机的方式可以设置出延迟的效果(但是官方的本来目的是为了让你处理死信消息的,你却用来处理延迟消息,不好)
延迟消息插件
rabbitmq官方出了个插件,当发送下延迟消息的时候可以在交换机暂存一段时间,然后在投递到队列中















 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









