









目录
1.2 Delving into the LLVM internal design
3.The LLVM Intermediate Representation
3.2 Introducing the LLVM IR in-memory model
3.3 Optimizing at the IR level
3.4 Understanding the pass API
1.Tools and Design
The LLVM project consists of several libraries and tools that, together, make a large compiler infrastructure. Throughout, LLVM emphasizes the philosophy that everything is a library,leaving a relatively small amount of code that is not immediately reusable and is exclusive of a particular tool.
Today, a central aspect of the design of LLVM is its IR. It uses Single-Static Assignments (SSA), with two important characteristics:
- Code is organized as three-address instructions
- It has an infinite number of registers
LLVM employs the following additional data structures across different compilation stages:
- When translating C or C++ to the LLVM IR, Clang will represent the program in the memory by using an Abstract Syntax Tree (AST) structure (the TranslationUnitDecl class)
- When translating the LLVM IR to a machine-specific assembly language, LLVM will first convert the program to a Directed Acyclic Graph (DAG) form to allow easy instruction selection (the SelectionDAG class) and then it will convert it back to a three-address representation to allow the instruction scheduling to happen (the MachineFunction class)
- To implement assemblers and linkers, LLVM uses a fourth intermediary data structure (the MCModule class) to hold the program representation in the context of object files
Besides other forms of program representation in LLVM, the LLVM IR is the most important one.
It has the particularity of being not only an in-memory representation, but also being stored on disk. In this philosophy, the compiler goes beyond applying optimizations at compile time, exploring optimization opportunities at the installation time, runtime, and idle time (when the program is not running). In this way, the optimization happens throughout its entire life, thereby explaining the name of this concept. For example, when the user is not running the program and the computer is idle, the operating system can launch a compiler daemon to process the profiling data collected during runtime to reoptimize the program for the specific use cases of this user.
As a compiler IR, the two basic principles of the LLVM IR that guided the development of the core libraries are the following:
- SSA representation and infinite registers that allow fast optimizations
- Easy link-time optimizations by storing entire programs in an on-disk IR representation

In order to decouple the compiler into several tools, the LLVM design typically enforces component interaction to happen at a high level of abstraction. It segregates different components into separate libraries; it is written in C++ using object-oriented paradigms and a pluggable pass interface is available, allowing easy integration of transformations and optimizations throughout the compilation pipeline.
1.1 Using standalone tools
- : This is a tool that is aimed at optimizing a program at the IR level. The input must be an LLVM bitcode file (encoded LLVM IR) and the generated output file must have the same type.
- : This is a tool that converts the LLVM bitcode to a target-machine assembly language file or object file via a specific backend. You can pass arguments to select an optimization level, to turn on debugging options, and to enable or disable target-specific optimizations.
- : This tool is able to assemble instructions and generate object files for several object formats such as ELF, MachO, and PE. It can also disassemble the same objects, dumping the equivalent assembly information and the internal LLVM machine instruction data structures for such instructions.
- : This tool implements both an interpreter and a JIT compiler for the LLVM IR.
- : This tool links together several LLVM bitcodes to produce a single LLVM bitcode that encompasses all inputs.
- : This tool transforms human-readable LLVM IR files, called LLVM assemblies, into LLVM bitcodes.
- : This tool decodes LLVM bitcodes into LLVM assemblies.
1.2 Delving into the LLVM internal design
The LLVM and Clang logic is carefully organized into the following libraries:




A pass is a transformation analysis or optimization. LLVM APIs allow you to easily register any pass during different parts of the program compilation lifetime, which is an appreciated point of the LLVM design. A pass manager is used to register, schedule, and declare dependencies between passes. Hence, instances of the PassManager class are available throughout different compiler stages.
●libclangLex:该库用于预处理和词法分析,处理宏、令牌和pragma构造。
●libclangAST: 该库为构建、操作和遍历抽象语法树(AST)增加了其他功能。
●libclangParse: 该库用于使用词法分析阶段的结果进行逻辑解析。
●libclangSema:该库用于语义分析,语义分析为AST验证提供操作。
●libclangCodeGen:该库使用编译目标的信息来生成LLVM IR代码。
●libclangAnalysis:该库包含用于静态分析的资源。
●libclangRewrite: 该库用于支持代码重写,并为构建代码重构工具提供基础架构
●libclangBasic:该库提供一组实用程序,包括内存分配抽象、源代码位置和诊
2.The Frontend
Clang is designed to be modular and is composed of several libraries. The libclang (http://clang.llvm.org/doxygen/group__CINDEX.html) is one of the most important interfaces for external Clang users and provides extensive frontend functionality through a C API. It includes several Clang libraries, which can also be used individually and linked together into your projects. A list of the most relevant libraries for this chapter follows:
- : This library is used for preprocessing and lexical analysis, handling macros, tokens, and pragma constructions
- : This library adds functionality to build, manipulate, and traverse Abstract Syntax Trees
- : This library is used for parsing logic using the results from the lexical phase
- : This library is used for semantic analysis, which provides actions for AST verification
- : This library handles LLVM IR code generation using target-specific information
- : This library contains the resources for static analysis
- : This library allows support for code rewriting and providing an infrastructure to build code-refactoring tools (more details in Chapter 10, Clang Tools with LibTooling)
- : This library provides a set of utilities – memory allocation abstractions, source locations, and diagnostics, among others.
3.The LLVM Intermediate Representation
The choice of the compiler IR is a very important decision. It determines how much information the optimizations will have to make the code run faster. On one hand, a very high-level IR allows optimizers to extract the original source code intent with ease. On the other hand, a low-level IR allows the compiler to generate code tuned for a particular hardware more easily. The more information you have about the target machine, the more opportunities you have to explore machine idiosyncrasies. Moreover, the task at lower levels must be done with care. As the compiler translates the program to a representation that is closer to machine instructions, it becomes increasingly difficult to map program fragments to the original source code. Furthermore, if the compiler design is exaggerated using a representation that represents a specific target machine very closely, it becomes awkward to generate code for other machines that have different constructs.
The key to minimizing the effort to build a retargetable compiler lies in using a common IR, the point where different backends share the same understanding about the source program to translate it to a divergent set of machines. Using a common IR, it is possible to share a set of target-independent optimizations among multiple backends.
The LLVM project started as a set of tools that orbit around the LLVM IR, which justifies the maturity of the optimizers and the number of optimizers that act at this level. This IR has three equivalent forms:
- in-memory representation (the Instruction class, among others)
- on-disk representation that is encoded in a space-efficient form (the bitcode files)
- on-disk representation in a human-readable text form (the LLVM assembly files)
LLVM provides tools and libraries that allow you to manipulate and handle the IR in all forms. Hence, these tools can transform the IR back and forth, from memory to disk as well as apply optimizations, as illustrated in the following diagram:
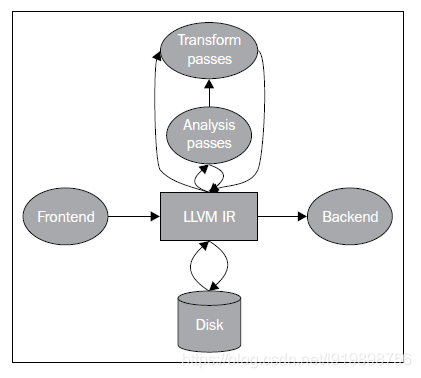
3.1 Introducing the LLVM IR
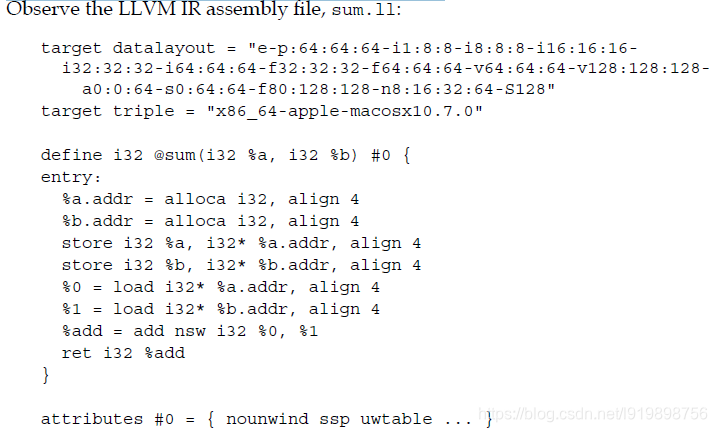
LLVM local values are the analogs of the registers in the assembly language and can have any name that starts with the % symbol. Thus, %add = add nsw i32 %0, %1 will add the local value %0 to %1 and put the result in the new local value, %add. You are free to give any name to the values, but if you are short on creativity, you can just use numbers. In this short example, we can already see how LLVM expresses its fundamental properties:
It uses the Static Single Assignment (SSA) form. Note that there is no value that is reassigned; each value has only a single assignment that defines it. Each use of a value can immediately be traced back to the sole instruction responsible for its definition. This has an immense value to simplify optimizations, owing to the trivial use-def chains that the SSA form creates, that is, the list of definitions that reaches a user. If LLVM had not used the SSA form, we would need to run a separate data flow analysis to compute the use-def chains, which are mandatory for classical optimizations such as constant propagation and common subexpression elimination.
Code is organized as three-address instructions. Data processing instructions have two source operands and place the result in a distinct destination operand.
`It has an infinite number of registers. Note how LLVM local values can be any name that starts with the % symbol, including numbers that start at zero, such as %0, %1, and so on, that have no restriction on the maximum number of distinct values.
3.2 Introducing the LLVM IR in-memory model
The in-memory representation closely models the LLVM language syntax that we just presented. The header files for the C++ classes that represent the IR are located at include/llvm/IR. The following is a list of the most important classes:
- Module class aggregates all of the data used in the entire translation unit, which is a synonym for "module" in LLVM terminology. It declares the Module::iterator typedef as an easy way to iterate across the functions inside this module. You can obtain these iterators via the begin() and end() methods. View its full interface at http://llvm.org/docs/doxygen/html/ classllvm_1_1Module.html.
- Function class contains all objects related to a function definition or declaration. In the case of a declaration (use the isDeclaration() method to check whether it is a declaration), it contains only the function prototype. In both cases, it contains a list of the function parameters accessible via the getArgumentList() method or the pair of arg_begin() and arg_end(). You can iterate through them using the Function::arg_iterator typedef. If your Function object represents a function definition, and you iterate through its contents via the for (Function::iterator i = function. begin(), e = function.end(); i != e; ++i) idiom, you will iterate across its basic blocks. View its full interface at http://llvm.org/docs/ doxygen/html/classllvm_1_1Function.html.
- BasicBlock class encapsulates a sequence of LLVM instructions, accessible via the begin()/end() idiom. You can directly access its last instruction using the getTerminator() method, and you also have a few helper methods to navigate the CFG, such as accessing predecessor basic blocks via getSinglePredecessor(), when the basic block has a single predecessor. However, if it does not have a single predecessor, you need to work out the list of predecessors yourself, which is also not difficult if you iterate through basic blocks and check the target of their terminator instructions. View its full interface at http://llvm.org/docs/doxygen/ html/classllvm_1_1BasicBlock.html.
- Instruction class represents an atom of computation in the LLVM IR, a single instruction. It has some methods to access high-level predicates, such as isAssociative(), isCommutative(), isIdempotent(), or isTerminator(), but its exact functionality can be retrieved with getOpcode(), which returns a member of the llvm::Instruction enumeration, which represents the LLVM IR opcodes. You can access its operands via the op_begin() and op_end() pair of methods, which are inherited from the User superclass that we will present shortly. View its full interface at http://llvm.org/docs/doxygen/ html/classllvm_1_1Instruction.html.
3.3 Optimizing at the IR level
Once translated to the LLVM IR, a program is subject to a variety of target-independent code optimizations. The optimizations can work, for example, on one function at a time or on one module at a time. The latter is used when the optimizations are interprocedural. To intensify the impact of the interprocedural optimizations, the user can use the llvm-link tool to link several LLVM modules together into a single one. This enables optimizations to work on a larger scope; these are sometimes called link-time optimizations because they are only possible in a compiler that optimizes beyond the translation-unit boundary. An LLVM user has access to all of these optimizations and can individually invoke them using the opt tool.
It is also possible to apply individual passes using opt.
The phase-ordering problem states that the order used to apply optimizations to code greatly affects its performance gains and that each program has a different order that works best. Using a predefined sequence of optimizations with -Ox flags, you understand that this pipeline may not be the best for your program. If you want to run an experiment that exposes the complex interactions among optimizations, try to run opt -O3 twice in your code and see how its performance can be different (not necessarily better) in comparison with running opt -O3 only once.
The set of passes contained in a given optimization level are already self-contained, and no dependency problems emerge.
3.4 Understanding the pass API
The Pass class is the main resource to implement optimizations. However, it is never used directly, but only through well-known subclasses. When implementing a pass, you should pick the best subclass that suits the granularity that your pass will work best at, such as per function, per module, per loop, and per strongly connected component, among others. Common examples of such subclasses are as follows:
- : This is the most general pass; it allows an entire module to be analyzed at once, without any specific function order. It also does not guarantee any proprieties for its users, allowing the deletion of functions and other changes. To use it, you need to write a class that inherits from ModulePass and overload the runOnModule() method.
- : This subclass allows the handling of one function at a time, without any particular order. It is the most popular type of pass. It forbids the change of external functions, the deletion of functions, and the deletion of globals. To use it, write a subclass that overloads the runOnFunction() method.
- : This uses basic blocks as its granularity. The same modifications forbidden in a FunctionPass class are also forbidden here. It is also forbidden to change or delete external basic blocks. Users need to write a class that inherits from BasicBlockPass and overload its runOnBasicBlock() method.
The overloaded entry points runOnModule(), runOnFunction(), and runOnBasicBlock() return a bool value of false if the analyzed unit (module, function, and basic block) remains unchanged, and they return a value of true otherwise. You can find the complete documentation on Pass subclasses at http://llvm.org/docs/WritingAnLLVMPass.html.
LLVM的优势:
1.编译速度更快:在某些平台上(ARM),LLVM的编译速度要明显快于gcc。
2.占用内存更小:LLVM生成的AST所占用的内存较小。
3.模块化的设计:LLVM基于库的模块化设计,更易于二次开发,内部代码重用较为高效。
4.诊断信息可读性强:在编译过程中,LLVM会创建并保留大量详细的元数据(metadata),这将更有利于调试和错误报告。
5.设计更清晰简单,容易理解,易于扩展加强。与代码基础较为古老的gcc相比,学习曲线会显得更为平缓。
6.在作出任何优化后都可以输出一次IR,然后通过opt工具进行下一个优化,易于分析,更便于设计新的优化,而gcc只能将多种优化的结果统一显示.
7. 统一的IR与模块化。你可以很轻易的抽取LLVM的组件(以库的形式)出来用于其它领域.(如抽取LLVM的整个后端(优化与CodeGen)用于TVM这样的深度学习推理框架)
8. 快速的可定制化:在LLVM中编写优化Pass非常方便,各种API的应用非常方便,而且文档详细.
9. 使用现代C++代码编写并有良好的代码组织。LLVM使用C++11编写,代码十分清晰与规范,对于阅读并且改写非常的方便.
10. License优势.
11. LLVM has a boss ---- Apple Inc.
12.LLVM在编译程序时输出的错误信息更加详细,比gcc能更准确的显示错误的内容.
LLVM的劣势
1.支持语言不够多:GCC除了支持 C/C++/Objective-C,还支持Fortran/Pascal/Java/Ada/Go等其他语言。LLVM(clang)目前基本上只支持C/C++/Objective-C/Objective-C++这四种语言。
2.需要加强对C++的支持:clang对C++的支持依然落后于gcc,clang还需要加强对C++ 提供全方位支持。
3.支持平台不如GCC多:由于gcc流行的时间比较长,已经被广泛使用,对各种平台的支持也很完备。clang目前支持的平台有Linux/Windows/Mac OS。
4. 相比较而言,gcc更成熟,易于安装,并且是许多系统的默认编译器,在多中系统内,人们可以直接使用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









