







十八、Conditional Generation by RNN & Attention
- Generation
- Attention
- Tips for Generation
- Pointer Network
(一)Generation
产生有structure的object,假设可以拆成很多component,使用RNN把这个component一个一个产生出来。
举例来说,怎么让machine产生句子,一个句子由word或者character组成,使用RNN把character或word一个一个产生出来。
一开始丢一个token到RNN,就会得到一个character的distribution,从这个character distribution做sample,接下来再把这个sample出来的character丢到RNN,RNN就会告诉你要接的character的distribution,再做sample,一直反复…

不仅仅是文章可以generate,image也可以,image是由pixel所构成,用RNN来generate pixel,把一张image看成sentence,下图可以看成由9个“词汇”组成的sentence:

同以上词汇的RNN的train的过程,image的generate的过程如下:

如果产生pixel的过程如下图,那就没有考虑pixel和pixel之间的几何关系:
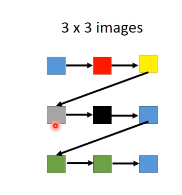
考虑pixel和pixel之间的几何关系的过程如下图:
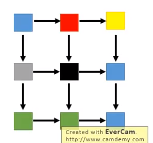
怎么实现这个几何关系?input3组数据,output3组数据,详情可看原视频:

光是使用RNN来generate是不够的,machine产生句子必须根据某些condition。
举例来说,我们怎么让machine看一个image就说一句话来说明这个image,即希望这个image可以影响RNN所产生的句子,做法:把image通过一个实现train好的CNN,然后把它变成一个vector,然后把这个vector当作RNN的input,这样RNN产生output时就会被image影响。如果担心,只是在第一个时间点把vector丢进去影响不够大,所以就在所有时间点都丢这个vector,RNN就可以反复复习。

同样的方法可以做很多其它的事情,比如机器翻译:现在有一个generator,它可以拿来产生英文的句子,但是现在的中文“机器学习”和这个generator是没有关系的,要把中文的input和这个generator牵扯在一起,做法:把中文的“机器学习”表示成一个vector,然后就可以和之前的图片处理一样。变成vector的方法:把中文的character一个一个丢到一个RNN里面,把RNN最后一个时间点的output抽出来,这个output可能就包含了这个句子的所有的information。

前面把input变成一个vector,然后丢给generator这个事情叫做Encoder(编码器);后面根据code产生句子的事情称为Decoder(译码器)。
Encoder和Decoder可以Jointly train(联合训练)这件事情称为Sequence-to-sequence learning。
(二)Attention
attention:动态的conditional generation。
刚才说过encoder的output在每一个时间点都接给decoder,但是可以做得更好,我们可以让这个decoder在每一个时间点看到的information都不一样,这样的好处是encoder可能没办法把input整个sentence变成一个code,如果input的information没办法用一个vector来表示,每次decoder看到的都是一样的,那就没办法得到好的结果。另一个好处是可以让decoder考虑需要的information。

拿机器翻译作为例子实现Attention:
1、
Attention-based model
input一个句子,这个句子会用RNN做一番处理,每个时间点每个词汇都可以用一个vector来表示,接下来有一个初始的vector z 0 z_0 z0,把它当作network的参数,把 h 1 h^1 h1(如下图)和 z 0 z_0 z0丢进match函数得到 α 0 1 \alpha ^1_0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2115
2115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









