







堆排序(Heap Sort)是由J.Williams在1964年提出的,它是在选择排序的基础上发展起来的,比选择排序的效率要高,因此也可以说堆排序是选择排序的升级版。堆排序除了是一种排序方法外,还涉及到方法之外的一些概念:堆和完全二叉树。这里主要说说什么是堆?
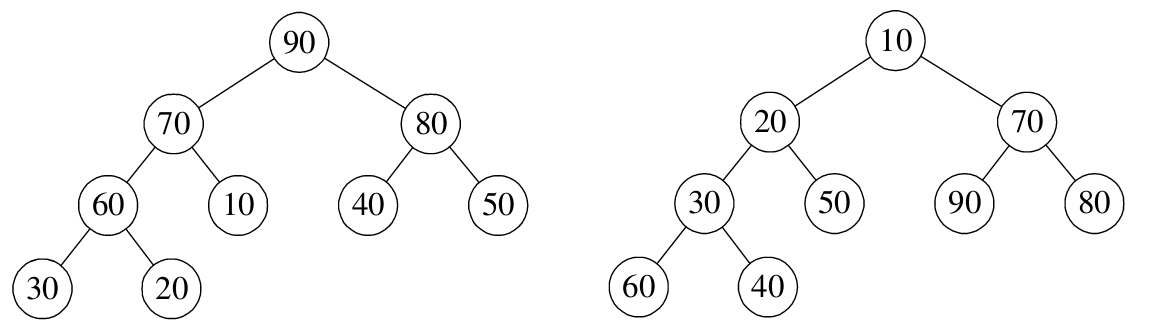
如果将堆看成一棵完全二叉树,则这棵完全二叉树中的每个非叶子节点的值均不大于(或不小于)其左、右孩子节点的值。由此可知,若一棵完全二叉树是堆,则根节点一定是这棵树的所有节点的最小元素或最大元素。非叶子节点的值大于其左、右孩子节点的值的堆称为大根堆,反之则称为下小根堆,如下图所示。
如果按照层序遍历的方式给结点从1开始编号,则结点之间满足如下关系:
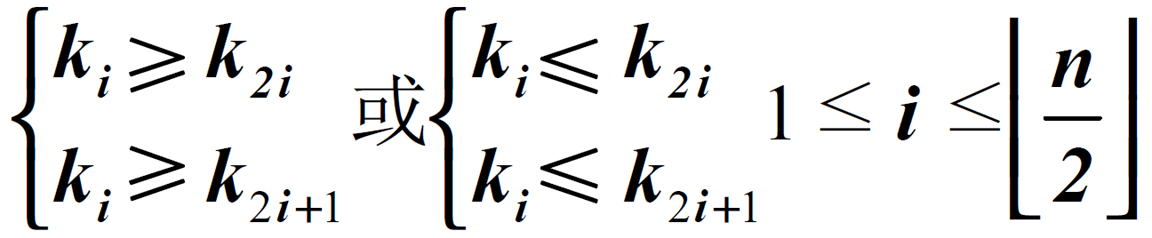
(1)基本思想
堆排序的基本思想是:首先将待排序的记录序列构造为一个堆,此时选择堆中所有记录的最小记录或最大记录,然后将它从堆中移出,并将剩余的记录再调整成堆,这样就又找到了次大(或次小)的记录。以此类推,直到堆中只有一个记录为止,每个记录出堆的顺序就是一个有序序列。
(2)处理步骤
堆排序的处理步骤如下:
①设堆中元素个数为n,先取i=n/2-1,将以i节点为根的子树调整成堆,然后令i=i-1。再将以i节点为根的子树调整成堆,如此反复,直到i=0为止,即完成初始堆的创建过程;
②首先输出堆顶元素,将堆中最后一个元素上移到原堆顶位置,这样可能会破坏原有堆的特性,这时需要重复步骤①的操作来恢复堆;
③重复执行步骤②,直到输出全部元素为止。按输出元素的前后次序排列起来,就是一个有序序列,从而也就完成了对排序操作。
假设待排序序列为(3,6,5,9,7,1,8,2,4),那么根据此序列创建大根堆的过程如下:
①将(3,6,5,9,7,1,8,2,4)按照二叉树的顺序存储结构转换为如下图所示的完全二叉树;

②首先,因为n=9,所以i=n/2-1=3,即调整以节点9为根的子树,由于节点9均大于它的孩子节点2和4,所以不需要交换;最后,i=i-1=2。
③当i=2时,即调整以节点5为根的子树,由于节点5小于它的右孩子8,所以5需要与8交换;最后,i=i-1=1。
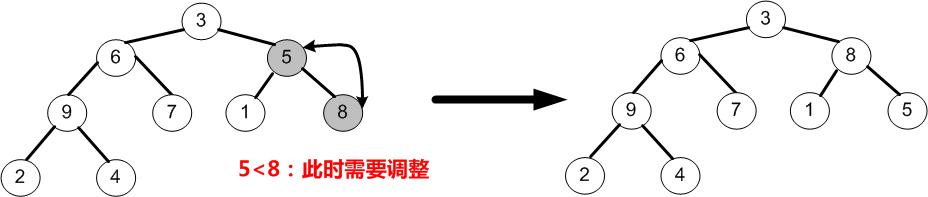
④当i=1时,即调整以节点6为根的子树,由于节点6均小于它的左、右孩子9和7,故节点6需要与较大的左孩子9交换;最后i=i-1=0。
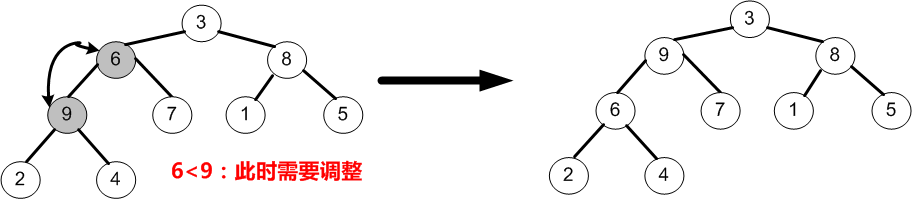
⑤当i=0时,即调整以3为根的子树,由于节点3均小于它的左、右孩子9和8,故节点3需要与较大的左孩子9交换;交换之后又因为节点3小于它的左、右孩子节点6和7,于是需要与较大的右孩子7交换。
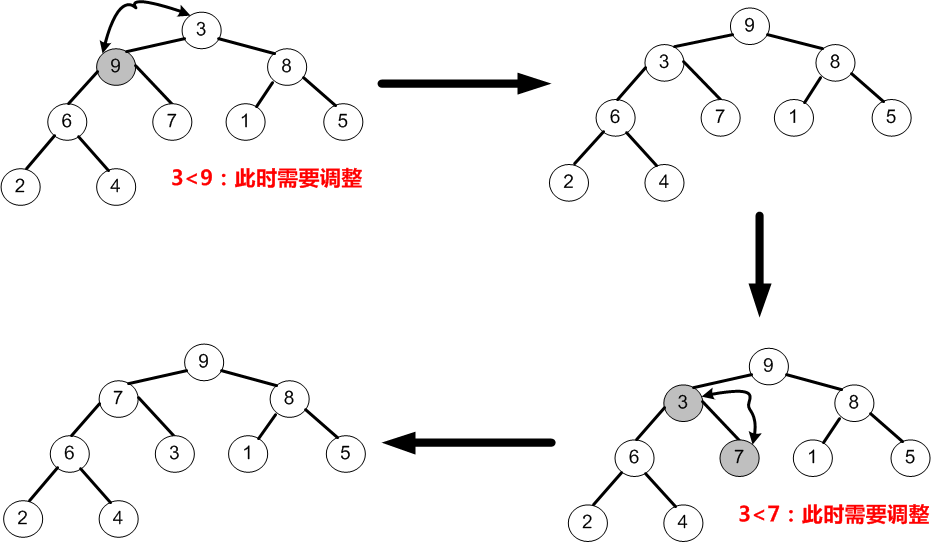
⑥如上图所示,至此就完成了初始堆的创建,待排序序列变为(9,7,8,6,3,1,5,2,4)。
(3)代码实现
①主入口:首先递归创建初始堆,其次递归调整大根堆;

public static void HeapSort(T[] arr)
{ int n = arr.Length; // 获取序列的长度 // 构造初始堆
for (int i = n / 2 - 1; i >= 0; i--)
{
Sift(arr, i, n - 1);
} // 进行堆排序 T temp; for (int i = n - 1; i >= 1; i--)
{
temp = arr[0]; // 获取堆顶元素
arr[0] = arr[i]; // 将堆中最后一个元素移动到堆顶
arr[i] = temp; // 最大元素归位,下一次不会再参与计算
Sift(arr, 0, i - 1); // 重新递归调整堆 }
}
②核心:创建堆的过程;
private static void Sift(T[] arr, int low, int high)
{ // i为欲调整子树的根节点索引号,j为这个节点的左孩子
int i = low, j = 2 * i + 1; // temp记录根节点的值
T temp = arr[i]; while (j <= high)
{ // 如果左孩子小于右孩子,则将要交换的孩子节点指向右孩子
if (j < high && arr[j].CompareTo(arr[j + 1]) < 0)
{
j++;
} // 如果根节点小于它的孩子节点
if (temp.CompareTo(arr[j]) < 0)
{
arr[i] = arr[j]; // 交换根节点与其孩子节点
i = j; // 以交换后的孩子节点作为根节点继续调整其子树
j = 2 * i + 1; // j指向交换后的孩子节点的左孩子 } else
{ // 调整完毕,可以直接退出
break;
}
} // 使最初被调整的节点存入正确的位置
arr[i] = temp;
}
在10000个随机数的数组中测试的性能结果如下图所示:
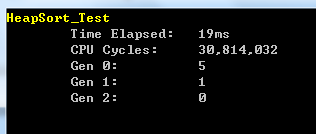
从上图可以看出,快速排序对于无序待排序数组的耗时只有19ms,比Shell排序还快了2ms,仅仅比快速排序慢了4ms,可以说跟快速排序一样快。
总结:堆排序的执行时间主要由建立初始堆和反复调整堆这两个部分的时间开销组成,由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlog2n)。这在性能上显然要远远好过于冒泡、简单选择、直接插入的O(n2)的时间复杂度了。另外,由于初始构建堆所需的比较次数较多,因此,它并不适合待排序序列个数较少的情况。















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









