






上个学期到现在陆陆续续研究了一下主题模型(topic model)这个东东。何谓“主题”呢?望文生义就知道是什么意思了,就是诸如一篇文章、一段话、一个句子所表达的中心思想。不过从统计模型的角度来说, 我们是用一个特定的词频分布来刻画主题的,并认为一篇文章、一段话、一个句子是从一个概率模型中生成的。
D. M. Blei在2003年(准确地说应该是2002年)提出的LDA(Latent Dirichlet Allocation)模型(翻译成中文就是——潜在狄利克雷分配模型)让主题模型火了起来, 今年3月份我居然还发现了一个专门的LDA的R软件包(7月份有更新),可见主题模型方兴未艾呀。主题模型是一种语言模型,是对自然语言进行建模,这个在信息检索中很有用。
LDA主题模型涉及到贝叶斯理论、Dirichlet分布、多项分布、图模型、变分推断、EM算法、Gibbs抽样等知识,不是很好懂,LDA那篇30 页的文章我看了四、五遍才基本弄明白是咋回事。那篇文章其实有点老了,但是很经典,从它衍生出来的文章现在已经有n多n多了。主题模型其实也不只是LDA 了,LDA之前也有主题模型,它是之前的一个突破,它之后也有很多对它进行改进的主题模型。需要注意的是,LDA也是有名的Linear Discriminant Analysis(线性判别分析)的缩写。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。由于 Dirichlet分布随机向量各分量间的弱相关性(之所以还有点“相关”,是因为各分量之和必须为1),使得我们假想的潜在主题之间也几乎是不相关的,这与很多实际问题并不相符,从而造成了LDA的又一个遗留问题。
对于语料库中的每篇文档,LDA定义了如下生成过程(generative process):
对每一篇文档,从主题分布中抽取一个主题;
从上述被抽到的主题所对应的单词分布中抽取一个单词;
重复上述过程直至遍历文档中的每一个单词。
更形式化一点说,语料库中的每一篇文档与
T
(通过反复试验等方法事先给定)个主题的一个多项分布相对应,将该多项分布记为
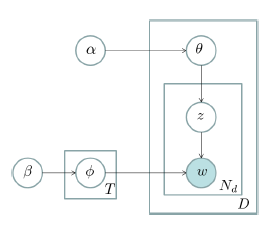
这个图模型表示法也称作“盘子表示法”(plate notation)。图中的阴影圆圈表示可观测变量(observed variable),非阴影圆圈表示潜在变量(latent variable),箭头表示两变量间的条件依赖性(conditional dependency),方框表示重复抽样,重复次数在方框的右下角。
该模型有两个参数需要推断(infer):一个是“文档-主题”分布
LDA模型现在已经成为了主题建模中的一个标准。如前所述,LDA模型自从诞生之后有了蓬勃的扩展,特别是在社会网络和社会媒体研究领域最为常见。
$【分隔】
先把问题描述一下:
如果我们已知了topic内的每个词的词频,比如下图中topic1 中money 2 次,loan 3次…那么任意给一个文档我们可以对里面每一个词算一个产生这个词的概率即 P(w=wi|t=tj)
如下图,doc1 中的money 百分之百的来自于topic1 。doc2 中的词用topic1 无法全部解释,必须借助topic2 。
但现在问题是,如果我们只有一堆文档,Doc1,Doc2,Doc3,且拍脑袋的大概知道会有2个topic,那么怎么产生着两个topic才能最好的解释这三个文档呢?

因此我们要计算一个概率,即文档中的这个词活脱脱的呈现在我们面前的概率P(wi),我们尽可能想办法让这个概率最大。就好像XX厂长成功了,我们要罗织功劳,让XX厂长成功这件事,最可信。
那么这个概率计算的方法如下图,简单来说就是 P(wi) = P(wi|topic) * P(topic|doc)*p(doc),我们省略p(doc)【求解没有意义】于是得到下面公式。

现在问题又来了,如果给定一个文档di的一个词wi,他最大可能是来自哪个topic呢?
即 求解P(topic|(di,wi))?
我们知道,P(topic|(wi,di))和P((wi,di)|topic)有关系,那么P((wi,di)|topic)=P(wi|topic)P(doc|topic),即我们要使得P(wi|topic)P(doc|topic) 这两个东东的liklyhood最大。
也就是论文中的CWT和CDT,而下图公式左边 (CWT+β)/(∑CWT+Wβ) 表示的含义就是P(wi|topic),即topic产生wi的能力。后面一个是P(doc|topici)。

为了验证有效性,我对论文中的这个例子做了实验,很遗憾没有做到他的结果,但我感觉应该是对的,其中α,大家可以调大调小了试试看,调大了的结果是每个文档接近同一个topic,即让p(wi|topici)发挥的作用小,这样p(di|topici)发挥的作用就大。 其中的β,调大的结果是让p(di|topici)发挥的作用变下,而让p(wi|topici)发挥的作用变大,体现在每个topic更集中在几个词汇上面,或者而每个词汇都尽可能的百分百概率转移到一个topic上。
大家可以看下论文,用我的代码实际感觉下数据的变化。
以下to @老师木 @王威廉 @李沐mu @等高手:
我觉得论文中的结果也很奇怪,如果在更新wi的类标号的时候,比如更新第一个doc的第二词,money,money出现了6次(2黑,4白),如果第一个更新为白,后面怎么可能更新为黑呢?如果不可能,为什么论文作者在64次迭代后,会有一些文档同一个word会打上不同的类标签,比如doc2,的bank,打了4黑1白?
我尝试过update放在每个更新之后,发现也做不到,很神奇,也许论文作者原始文档的term出现顺序不是我写的那样。
代码和论文地址:
https://github.com/pennyliang/MachineLearning-C—code/tree/master/gibbs_sampling
转自:pennyliang-浅谈gibbs sampling(LDA实验)















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









