







 本文介绍了一个基于地理标记图像的空间聚类算法,用于高效地标发现。系统利用Flickr上的照片识别热门旅游景点,通过DBSCAN算法结合R树索引优化聚类过程,实现自动化旅行推荐。
本文介绍了一个基于地理标记图像的空间聚类算法,用于高效地标发现。系统利用Flickr上的照片识别热门旅游景点,通过DBSCAN算法结合R树索引优化聚类过程,实现自动化旅行推荐。
目录
II. BACKGROUND AND RELATED WORK
项目地址https://github.com/ashrithhc/TravelRouteRecommendation
之前找好久找不到,都绝望了。这回又找到相似的了,又得开始搭了,搭了一会儿又缺数据用不了啊
The details of the project is published here : 这是个paper
A web application that suggests an optimal route between A and B such that multiple tourist attractions are present on the journey from A to B, finding a middle ground between shortest route and a route which includes maximum tourist attractions. 一个 Web 应用程序,它建议 A 和 B 之间的最佳路线,这样在从 A 到 B 的旅程中都存在多个旅游景点,在最短路线和包含最大旅游景点的路线之间找到一个中间地带。
Install :
gensim - requires numpy and scipy
Rtree - requires libspatial index
imposm.parser
overpy
overpass
networkx
scikit
| conda install scikit-learn |
nltk
- postgresql
sudo apt-get install postgresql-9.3
- pgrouting
sudo add-apt-repository ppa:georepublic/pgrouting
sudo apt-get update
sudo apt-get install postgresql-9.3-pgrouting
- postgis
sudo apt-get install postgresql-9.3-postgis-2.1 postgresql-contrib pgadmin3
sudo su -m postgres
psql
CREATE USER deeksha SUPERUSER;
\q
su deeksha
createdb flickr
psql -d flickr
CREATE EXTENSION postgis;
CREATE EXTENSION postgis_topology;
CREATE EXTENSION fuzzystrmatch;
CREATE EXTENSION postgis_tiger_geocoder;
CREATE EXTENSION pgrouting;
- osm2pgrouting
sudo apt-get install cmake
sudo apt-get install libpq-dev
cmake -H. -Bbuild
cd build/
make
make install
System overview :

Paper翻译
Paper导出Deeksha S D, Ashrith H C, R. Bansode and Sowmya Kamath S, "A spatial clustering approach for efficient landmark discovery using geo-tagged photos," 2015 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, 2015, pp. 1-6.
doi: 10.1109/CONECCT.2015.7383901
keywords: {geophysical image processing;social networking (online);spatial clustering approach;landmark discovery;geo-tagged photo;image sharing social network;landmark discovery system;Flickr;Clustering algorithms;Cities and towns;Metadata;Planning;Media;Mathematical model;landmark ranking;spatial clustering;indexing;recommendation systems},
URL: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7383901&isnumber=7383851
I. INTRODUCTION
地理标记的照片使人们可以通过图片共享社交网络(如 Flickr)在访问各个度假胜地时分享个人体验。地理标签信息为捕获旅行者行为、趋势、观点和兴趣的其他信息提供了丰富的信息。本文提出了一个具有里程碑意义的发现系统,旨在发现一个城市的热门旅游景点,假设一个旅游景点的受欢迎程度正依赖于游客统计数据和游客上传照片的数量点击了网站。众所周知,上传至 Flickr 的地理标记照片较多的地方,经常被社交媒体精明的游客访问,他们根据他人的经验来规划行程。我们建议使用从 Flickr 收集的地理标记照片来识别特定城市中最受欢迎的旅游景点,并向客户推荐相同的照片。本文介绍了地理标记图像的空间聚类方法,并分析了识别地标的算法性能及其普及程度。
随着数码相机和手机相机的发展和增加,Instagram 和 Flickr 等在线照片共享服务越来越受欢迎。在 Web 2.0 时代,社交媒体是一个蓬勃发展的平台,用户通过它相互交流或为网络上的信息内容做出贡献。自愿地理信息 [1] 是包含地理内容并由用户共享的信息。VGI 已用于旅游、灾难与危机管理、交通、个性化和快速等各个领域的数据分析和知识发现研究。VGIontheWeb今天最常见的来源是社交网站,如Flickr,OpenStreetMap,推特,Facebook,YouTube,维基地图,四方形等。这些服务允许用户共享图片,并将每张照片与标签相关联,因此,有大量众包和带标签的照片可供使用。用户可以决定将地理标记附加到上传的照片,以指示其点击位置。大多数现代数码相机通过内置的 GPS 设备自动捕获位置信息,该设备可以自动作为地理信息提供,或者由用户自己指定。地理标记是将空间信息注入 Web 应用程序非常有用的元数据格式。
Flickr是一个在线照片共享服务,允许用户上传他们的照片。这些照片与元数据相关联,例如拍摄照片的地理位置、点击照片的时间、大小、用于单击照片的相机、标题、描述照片的文本、用于描述照片的关键字标记等等。此元数据有助于分析 Flickr 用户的活动。这些图像在地图上绘制时可以揭示游客参观过的各个地方。利用图像中的空间模式,可以发现游客的热门目的地。通常,我们的目标是从地理标记的 Flickr 照片数据中发现此信息,以开发高效的旅行推荐系统,为用户提供最有趣的(流行)地标
proposed工作背后的主要动机是,在阻碍休假之前收集信息仍是一项主要侧重于研究和阅读在线文章的手动任务。当人们不得不前往他们从未去过的地方时,他们会有几个关于计划旅行的问题。阅读各种旅游杂志或在社交媒体上分享他们的问题,可以获得一些帮助。这个过程不是非常有效,需要大量的手工工作。对于他们来说,阅读几个游记并总结评论是一个耗时的繁琐任务。咨询旅游杂志的另一个缺点是,它们的语言不同,使得用户很难翻译和解释信息。因此,需要一个自动化的行程规划服务,可以定制用户的兴趣。这项服务还应包含以前的访客知识。
目前有几个在线旅游指南,一些流行的是WikiTravel[1]和雅虎旅游指南[2]。WikiTravel 为用户提供了目的地的气候、该地区的热门地标、该地区购物场所、好餐馆、不同种类的食物等信息,以及有关如何到达那里的信息。一个主要缺点是,如果 WikiTravellers 不添加有关任何特定目的地的信息,其他用户将不会找到有关该目的地的信息。虽然维基旅行依赖于用户分享信息,雅虎旅游指南提供信息领域明智。对于每个国家,该国所有受欢迎的城市都列出。此外,信息是由编辑提供的,而不是那些去过这些地方的游客。该系统的主要缺点是它只提供有关某些城市的信息。实际上,自动旅行推荐是一项艰巨的任务,取决于旅游者的个人兴趣、旅行成本、持续时间、旅行日期、用户所需的舒适程度等多种因素。在建议的系统中,我们针对旅行规划的两个属性 - 位置(城市)和旅游景点。空间聚类算法可用于从地理参考图像中提取常用地标。第二节使用地理参考照片审查有关旅行建议的工作。第三节提出了拟议的旅行建议办法。第四节提供所完成工作的结果和分析。第五节给出了项目的结论,并给出了项目的未来工作。
II. BACKGROUND AND RELATED WORK
推荐系统,用于音乐、书籍、电影等领域的资源发现和指导,以及基于用户偏好的个性化是一个活跃的研究兴趣领域。Sun 等人 [2] 提出了一个系统,其中地理标记信息用于通过查找标记相关性来开发标记建议工具。这些生成的标记以及地理标记用于其他目的,如挖掘事件和趋势。在与旅游研究相关的其他作品中,收集地理标记图像和 GPS 历史数据用于识别热点和地标、地雷轨迹和运动,并规划行程和推荐行程 [3],[4]。然而,在自动化旅游或旅行规划过程方面,几乎没有什么工作。Kori等人[5]建议使用当地博客并生成旅行指南,但用户偏好没有考虑,以自动规划旅行。
Ji等人[6]提出了一种使用图形模型从博客中提取流行地标的方法,而郑等人[7]和Jaffe等人[8]则侧重于使用地理参考图像来可视化、识别和描述地标。肯尼迪等人[9]利用网络上的富媒体为地标生成具有代表性的图像集。Gao等人[10]建议只使用与图像相关的标签,以便提取潜在的地标,并根据它们在游客中的受欢迎程度进行排名。
岩田等人[11]使用聚类技术发现子轨迹,郑等人(12)提出了基于HITS(超文本诱导主题搜索)的模型,利用GPS轨迹挖掘有趣的位置和旅行模式,并考虑这种关系在用户和位置之间。Sun 等人 [2] 讨论了路线建议,其中 DBSCAN 聚类技术首先用于从地理标记图像集合中确定地标,然后在提取的地标之间提供基于道路的旅行路线。
DBSCAN 群集是一种基于密度的聚类方法,计算群集需要大量时间,尤其是在数据非常密集时,Flickr 数据就是如此。我们的方法是使用带有 R 树索引的增强 DBSCAN 算法,从而获得更好的性能和准确性。我们还采用有效的降噪技术,从收集中过滤掉不相关的照片,识别非游客(当地人)上传的照片,然后将所得数据集中,以发现六大热门游客参观的热门地标世界各地的城市。我们还提供聚类数据的可视化效果,以突出显示和验证地标的受欢迎程度,正如我们的算法所发现的那样
III. PROPOSED SYSTEM
在本节中,我们将详细讨论建议方法的各种过程。系统工作流如图 1 所示。
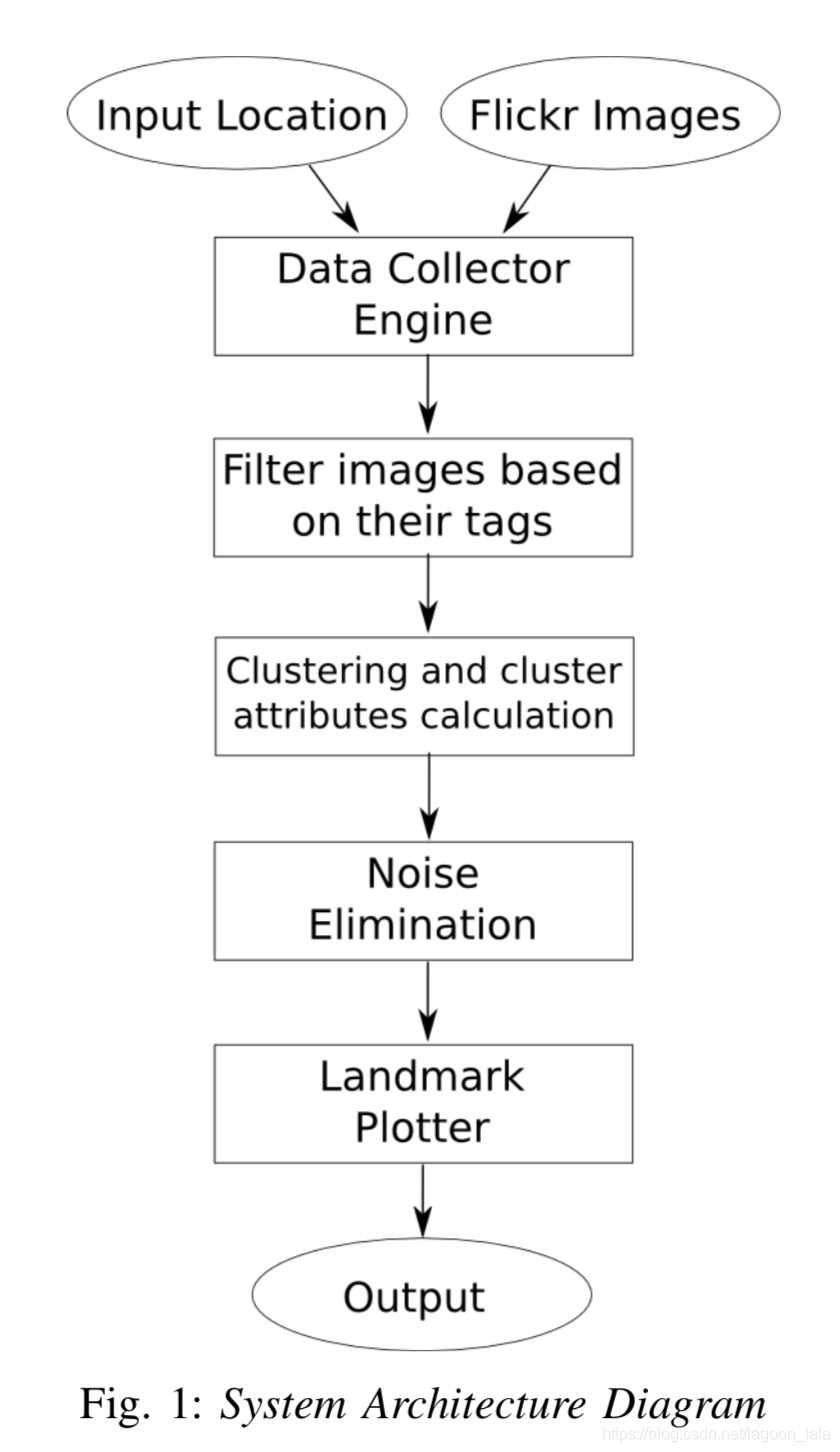
A. 从 Flickr 收集地理标记图像 我们工作的第一个要求是收集游客在旅途中访问各种地标时张贴在 Flickr 上的照片。我们使用 Flickr 提供的某些 API,它支持数量有限的操作,如获取联系人、发布照片、获取收藏夹列表、从图库获取照片等。Flickr 提供的服务之一是 flickr.photos.search,可用于获取公开获得的地理标记照片。除了照片,还可以获取与照片关联的标记和一些元数据。元数据包括有关照片所有者、照片拍摄日期、拍摄照片的确切位置(地理标记)等信息。这构成了我们的初始数据集,获得相关的只归于游客的标记照片,,
B. 图像相关标记的数据集筛选 标记的主要功能是描述照片内容,是向图像提供其他元数据的最简单方法。这些标签为我们提供了有关照片的信息,如它是什么样的地标,地标上的街道的名称等等。如果没有标记,可能需要使用计算密集型图像处理方法来确定图像的内容。然而,社交媒体用户所做的标记的缺点是,标签在性质上往往非常通用,如"我的夏天"、"我的旅行"、"假期"等。此类标记不提供有关照片内容的任何信息,需要从数据集中标识和删除。问题是,数以千计的用户上传,每个城市可用的公共照片在Flickr,并因此,这些通用标签的识别不能手动完成。
为了找到这些通用标记的照片并从数据集中消除它们,我们建议使用一种称为 Tf-idf 的自然语言处理 (NLP) 技术(术语频率反向文档频率)。此技术是一种统计方法,用于确定单词在单词集合、文档或文档集合中的重要性。删除每张照片的所有不重要的标记后,剩余的标记可用于提取有关群集过程后提取的地标的信息。在这里,我们将照片视为文档,并将每张照片的标签视为文档中的单词。Tf-idf 计算在方程 (1) 中给出。
Tf-idf(tagi) = tf(tagi)×idf(tagi) (1)
术语频率计算为 1 或 0。如果照片中存在标记,则为 1;如果不存在标记,则为 0。使用公式 (2) 计算反向文档频率。
idf(tagi) = log2(1 +D/doc freq{i}) (2)
其中 tagi 表示标记下考虑,D 表示照片的总数,文档 freq_i= 表示标记中出现的照片数。
C. 聚类属性的聚类和计算空间聚类算法 DBSCAN 用于根据图像的地理标记将图像分组到聚类中。DBSCAN 算法需要两个参数 - 邻域距离和最小点数。通过反复试验,将100米的距离用作邻域距离,将20米作为最小点数。由于我们还不知道单击两个不同图像的位置之间的距离,我们使用图像的地理位置来计算它们之间的大圆距离。haversine 公式可用于使用经度和纬度信息 [13] 获取球体(地球)表面两个点(地标)之间的最短距离,称为大圆距离。
使用此信息,我们对图像数据执行 DBSCAN 聚类。算法 1 显示了数据聚类 [14] 的过程。使用群集属性进一步筛选获取的群集,这些属性是群集属性、用户数、每个用户内容的权重以及群集的总内容权重。这些聚类属性是利用高等人提出的[10]的方法计算出来的,下面给出了。
Numberofusers (Nuser) -Foreachcluster, (Nuser) gives the number of users whose images are in that cluster. Greater the number of users, greater is the popularity of the region. • Content weight for each user (CWuser) - This describes how much content each user provides to the cluster. Let CWuser(k) denote the content score for kth user and Nphoto(k) denote the number of photos provided by the kth user. CWuser(k) is calculated using the equation (3).
CWuser(k) = log(Nphoto(k) + 1) (3)
• Total content weight for the cluster TW) - This describes the overall content provided by all users in the cluster. It is the sum of all CWuser values from all the users. It is given by the equation (4).
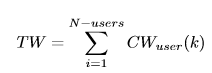
D. 聚类索引数据 由于需要群集的图像数量很大,DBSCAN 完成群集过程所需的时间较长。这是因为对数据集中的所有图像执行范围查询。调用范围查询以返回特定图像的特定范围内的所有图像。如果图像未根据其地理位置编制索引,则正常范围查询将要求程序遍历所有图像,计算相对于给定图像的距离,并返回满足最大半径条件的距离。因此,没有索引数据的 DBSCAN 的运行时间复杂性为 O(n2)。使用适当的数据结构来存储多维数据将减少聚类的时间,但空间复杂性可能更高,这不是主要问题。由于对每个点执行一个范围查询,而对 n 点进行聚类,因此使用高效的索引机制可降低总体运行时间复杂性。通过根据图像的地理位置对图像进行索引,可以改进聚类过程。但是,我们发现常见的 1 维索引和哈希值并不适合我们的数据,它基本上是二维的。在本文中,我们探讨了两种空间数据索引的方法:R树索引和MongoDB的二dsphere索引。
1) DBSCAN 与 R 树索引:R 树或矩形树是用于索引多维数据(如地理坐标)的数据结构。Rtree 的基本工作是,附近的数据对象被分组在一起,并在树的下一个较高级别 [15] 中的最小边界矩形中表示。因此,树的每个叶也是矩形,并代表单个数据对象。Rtree 是检索信息的最有效效率最高的。它们支持边界框检索、最近邻居搜索和包含查询。
边界框查询在我们的上下文中很有用,因为它们不需要遍历整个树。根据边界框,如果子树不位于边界框中,则绕过这些子树移动到下一个子树。为在图像的地理标记上对图像进行索引的每个城市创建了一个索引。这些索引已针对持久存储进行序列化,以便在执行范围查询时可以反序列化并加以使用。为了获得位于特定图像固定半径内的所有图像,给定图像的地理坐标与半径一起使用以获得边界框坐标。然后,这些坐标用于对索引执行交集查询,其中仅返回位于边界框矩形内的图像。因此,使用 R 树对 Flickr 图像进行索引,使聚类速度加快。这是因为群集期间的大部分时间都花在执行范围查询上,与传统的 DBSCAN 相比,索引使范围内的查询运行得更快。
2) MongoDB 2dsphere 索引:MongoDB 提供各种索引方案,包括多维数据的索引。其中一个索引是 2dsphere 索引,它支持涉及球体计算的查询。它支持所有类型的地理空间查询,如范围、边界框和最近的邻域查询 [16]。使用此索引方案给出了有趣的结果,因为聚类比传统的 DBSCAN 在没有任何索引的情况下所花的时间要多。这是因为与其他类型的查询相比,MongoDB 执行 2dsphere 索引查询所需的时间更长。
E. 消除居民照片 获得的照片组可能包含由该位置的居民而不是游客拍摄和上传的照片。此类照片必须从数据集中删除,才能获得准确结果。这是使用熵过滤方法,这是基于一个事实,游客留在城市很短的时间,并上传的照片,拍摄的时间跨度内,而居民可以上传的图像,已经采取了通过一年。使用这种方法,居民可以区分游客在图像集的用户。
F. 确定群集重要性 使用计算的群集属性,群集可以保留为地标或不。只有当群集具有高重要性因素时,才能将其视为地标。TCW 是用于确定群集是否为地标的阈值。如果聚类满足方程 (5) 表示的条件,则认为它是一个地标。
TW(集群) = TCW (5)
G. 绘制地标群集 使用聚类属性消除所有嘈杂的群集后,计算每个群集中所有照片的中位数以查找地标的地理位置。这在世界地图和城市地图上绘制,以便提供聚类结果的可视化效果。
IV. RESULTS AND ANALYSIS
A. 调查数据集 Flickr 查询了 6 个不同热门旅游景点的所有公共照片 - 悉尼、巴黎、伦敦、新加坡、纽约和旧金山。共收集了46 160张照片。在这46,160张照片中,有1,865张照片被居民淘汰为照片。下面给出了我们工作中使用的所有六个位置的照片数据集的统计信息。
• Total number of locations: 6 • Total number of photos: 46,160 • Total number of users: 4,324 • Total number of tourists: 4,301 • Total number of residents: 23 • Total number of photos taken by residents: 1,865 • Total number of photos taken by tourists: 44,295
为了区分游客和居民,采用了前所述熵过滤方法。熵使用阈值 1.5。如果计算熵大于此阈值,则用户将标记为驻留用户。然后,使用 Tf-idf 使用阈值 2 来消除常见标记。因此,所有出现在总照片中超过四分之一的标记都将被丢弃,因为这些标记将是通用标记。基于标记分析删除照片后,DBSCAN 算法用于将照片分组到群集中,并计算了聚类属性。用于消除嘈杂群集的群集的阈值内容分数为 8。表 I 显示了每个步骤后产生的照片数量的详细统计信息。与表二中表格中表格中的非索引数据聚类相比,两种聚类索引方案产生了不同的结果。
从表二可以看出,要聚集的照片数量越多,聚类时间越大。对于照片数量相似的城市,如果集群数量较多,传统 DBSCAN 所用的时间就更多。因此,我们可以得出结论,聚类时间取决于数据集的大小和可以形成的聚类数量。发现 R 树是我们数据集最有效的索引方法。图 2 显示了使用不同方法的聚类时间图。
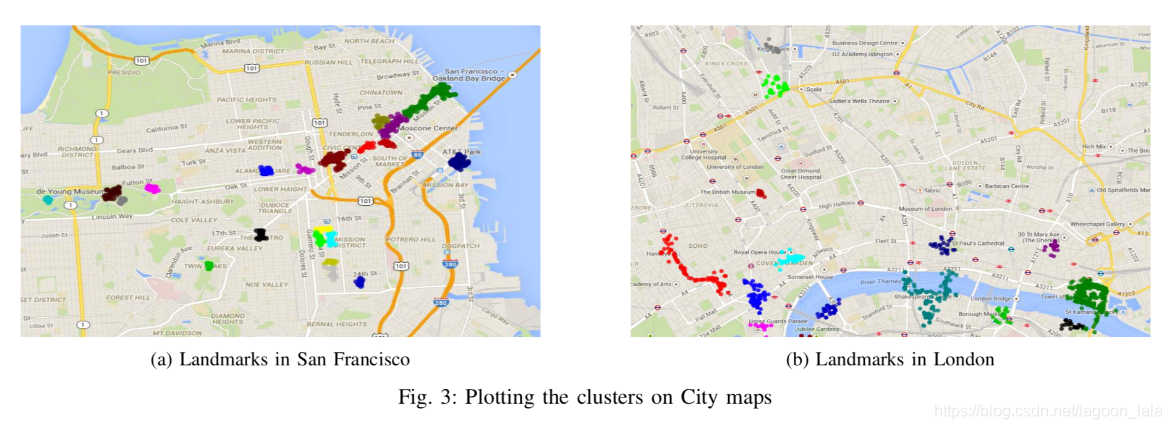
6个地点的所有地标都绘制在世界地图上,如图4所示。然后,在相应的城市地图上绘制了六个城市的筛选群集,再次使用 Google 地图 API 绘制。图 3a 和 3b 显示了分别为旧金山和伦敦绘制的群集。根据地理标记照片中提供的固有信息(而不是未明确提供的信息)推荐使用地标。由于数据集的这一限制,没有统计数据,如每个地标的访问者数量。
本文介绍了一种利用R树索引从地理标记图像中进行地标性发现的有效空间聚类算法。我们从 Flickr 收集了六个不同城市的公开照片及其元数据。为了区分游客和居民,这些照片被分析为噪音而被丢弃。然后使用 Tf-idf 分析其余照片的标签,以消除大多数照片中发生的更通用的标签。然后,使用 R 树索引对 DBSCAN 聚类应用到其余照片,并为每个群集计算群集属性。使用 R 树优化了聚类过程,因为数据点检索速度更快。满足最低要求的群集被视为地标,并使用 Google 地图 API 在位置地图上绘制。作为未来工作的一部分,我们打算采用增量群集方法,以避免冗余群集,以便在 Flickr 提供新的公共照片时,框架可以轻松扩展。
尝试搭建
在scopes-->misc中看到版本Python 2.7.5+
| activate travelRoute cd /d D:\anacondaProject\TravelRouteRecommendation python manage.py migrate python manage.py runserver |
报错
| 'Did you install mysqlclient or MySQL-python?' % e django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module: No module named MySQLdb. Did you install mysqlclient or MySQL-python? |
| pip install mysql-python pip install pymysql pip install mysqlclient 安装失败,尝试较低版本https://www.jianshu.com/p/b8edcafacae6 pip install mysqlclient==1.3.4 |
报错:
| django.db.utils.OperationalError: (1045, "Access denied for user 'root'@'localhost' (using password: YES)") |
Setting.py中数据库信息:
| DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'flickr', 'USER': 'root', 'PASSWORD': 'password', 'HOST': '127.0.0.1', 'PORT': '', } } |
在backup\sql backup中找到sql
报错:
| ImportError: cannot import name patterns |
http://30daydo.com/article/363
官方上说的1.8之后不建议使用,所以应该降级到1.8才可以。
降级命令:
pip install django==1.8
即可。
Migrate没有问题了。
run运行报错
| No module named pymongo |
下拉列表没有东西
点击get landmarks按钮也只报错没return东西
| The view route_recommendation.views.extract_landmarks didn't return an HttpResponse object. It returned None instead. |
看到下拉列表中是遍历cities的值,view.py中
| def index(request): client = MongoClient() db = client.flickr seed_location = db.seed_location
cities = [] locations = seed_location.find()
for loc in locations: cities.append({'id': loc['location_id'], 'name': loc['name']})
return render(request, 'home.html', {'cities': cities}) |
貌似是存在mongodb中
看介绍osm_data文件夹是Implemented Rtree indexing; Shifted db to mongodb; statistics for db,但里面只有两个csv。 backup\json backup比较有可能
新建collection,insert
文档中两个Json中间又逗号,用robo插入时校验不通过,把所有逗号删除即可
导入mongo之后下拉列表有东西了,

但是点击get landmarks还是一样报错
| The view route_recommendation.views.extract_landmarks didn't return an HttpResponse object. It returned None instead. |
查看view中extract_landmarks源码
| 正常返回 return render(request, 'landmarks.html', {'clusters': clusters, 'map_center': map_center, 'location': location}) |
| 异常返回 clustersCollection = db.clusters photosCollection = db.photos reviewsCollection = db.reviews
pattern = "^" + str(location) + ".*$" regex = re.compile(pattern) _clusters = clustersCollection.find({"rank": {"$exists": True}, "cluster_id": regex, "poi_id": {"$ne": None}}) if _clusters.count() == 0: return |
查看collection中所有数据
| all=mycol.find() # all=mycol.find({'age':21}) print(all) for doc in all: print(doc) |
| 查看一条 # one=mycol.find_one() # one=mycol.find_one({'age':21}) # print(one) |
确认了集合里有东西
| clustersCollection: {u'content_score': 62.4600226873, u'longitude': 151.21199635, u'IC_user': u'110267597@N03=1.09861228867;109577680@N03=0.69314718056;87199669@N00=1.09861228867;112929486@N06=0.69314718056;39887633@N07=0.69314718056;95920855@N06=0.69314718056;71589551@N00=0.69314718056;36398420@N04=0.69314718056;41059842@N03=0.69314718056;126987475@N06=0.69314718056;102237062@N02=1.09861228867;50037366@N08=0.69314718056;76104379@N00=0.69314718056;7363441@N07=2.19722457734;127201661@N02=0.69314718056;128357730@N02=0.69314718056;62146351@N00=0.69314718056;123542856@N05=0.69314718056;59303791@N00=0.69314718056;52133484@N02=0.69314718056;76705972@N00=1.09861228867;55899488@N00=0.69314718056;62801660@N00=0.69314718056;73422502@N08=0.69314718056;58768853@N00=1.09861228867;98942020@N00=3.98898404656;123533110@N02=0.69314718056;52633947@N00=1.38629436112;18143440@N02=0.69314718056;19308933@N00=0.69314718056;53721792@N07=0.69314718056;24732508@N04=0.69314718056;23682063@N08=2.83321334406;45940663@N08=0.69314718056;24147900@N06=0.69314718056;22349613@N08=1.38629436112;67169154@N08=0.69314718056;25781112@N05=0.69314718056;51073972@N02=0.69314718056;8056980@N08=1.09861228867;26116471@N03=0.69314718056;46062220@N06=0.69314718056;71946503@N05=0.69314718056;85686961@N00=0.69314718056;9376953@N07=0.69314718056;43463556@N07=0.69314718056;72172829@N00=0.69314718056;13538874@N04=0.69314718056;9301358@N06=0.69314718056;93693000@N02=0.69314718056;57688684@N02=0.69314718056;89617809@N07=0.69314718056;24958117@N07=0.69314718056;64238591@N05=0.69314718056;21397036@N02=0.69314718056;43672813@N00=1.94591014906;32625786@N04=0.69314718056;126579434@N05=0.69314718056;62637674@N00=2.07944154168;57848406@N04=0.69314718056;25677708@N04=0.69314718056;30079014@N03=3.09104245336;76534421@N03=0.69314718056;89165847@N00=2.99573227355;', u'N_user': 64, u'cluster_id': u'11', u'address': u'Cahill Walk, N, The Rocks, Sydney City, New South Wales, AU, 2001', u'latitude': -33.8593735787, u'_id': ObjectId('5d78fc52e6e7c6e7e8cf9fa8')} |
有cluster_id属性,无poi_id,无rank
Exists操作符
| $exists语法: { field: { $exists: <boolean> } } 1.当boolean为true,$exists匹配包含字段的文档,包括字段值为null的文档。 2.当boolean为false,$exists返回不包含对应字段的文档。 既存在rank属性的document |
导入的json中也没有rank属性,poi也是两个csv中单独的
找不到数据,感觉没救了,留个issue死马当活蚂蚁
弃坑


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









