








2.迁移综述
A Survey on Transfer Learning
https://www.cse.ust.hk/~qyang/Docs/2009/tkde_transfer_learning.pdf
翻译参考:
A Survey on Transfer Learning_神奇的腿的博客-CSDN博客
本文的目的是迁移写作的英文语料积累
Inductive和transductive的迁移都有基于样本的和基于特征的, 它们有什么区别吗
但基于参数的和基于关系的只在Inductive存在
目录
1. inductive transfer learning
2. transductive transfer learning
3.1 Transferring Knowledge of Instances
3.2 Transferring Knowledge of Feature Representations
3.2.1 Supervised Feature Construction
3.2.2 Unsupervised Feature Construction
4 TRANSDUCTIVE TRANSFER LEARNING
4.1 Transferring the Knowledge of Instances
4.2 Transferring Knowledge of Feature Representations
摘要
在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据,一定要在相同的特征空间并且具有相同的分布。然而,在许多现实的应用案例中,这个假设可能不会成立。
A major assumption in many machine learning and data mining algorithms is that the training and future data must be in the same feature space and have the same distribution.
However, in many real-world applications, this assumption may not hold.
比如,我们有时候在某个感兴趣的领域有个分类任务,但是我们只有另一个感兴趣领域的足够训练数据,并且后者的数据可能处于与之前领域不同的特征空间或者遵循不同的数据分布。
For example, we sometimes have a classification task in one domain of interest, but we only have sufficient training data in another domain of interest, where the latter data may be in a different feature space or follow a different data distribution.
这类情况下,如果知识的迁移做的成功,我们将会通过避免花费大量昂贵的标记样本数据的代价,使得学习性能取得显著的提升。
In such cases, knowledge transfer, if done successfully, would greatly improve the performance of learning by avoiding much expensive data labeling efforts.
近年来,为了解决这类问题,迁移学习作为一个新的学习框架出现在人们面前。这篇综述主要聚焦于当前迁移学习对于分类、回归和聚类问题的梳理和回顾。
在这篇综述中,我们主要讨论了其他的机器学习算法,比如领域适应、多任务学习、样本选择偏差以及协方差转变等和迁移学习之间的关系。
我们也探索了一些迁移学习在未来的潜在方法的研究。
关键词
迁移学习;综述;机器学习;数据挖掘
1 引言
数据挖掘和机器学习已经在许多知识工程领域实现了巨大成功,比如分类、回归和聚类。
然而,许多机器学习方法仅在一个共同的假设的前提下:训练数据和测试数据必须从同一特种空间中获得,并且需要具有相同的分布。
However, many machine learning methods work well only under a common assumption: the training and test data are drawn from the same feature space and the same distribution.
当分布情况改变时,大多数的统计模型需要使用新收集的训练样本进行重建。
在许多现实的应用中,重新收集所需要的训练数据来对模型进行重建,是需要花费很大代价或者是不可能的。
In many real world applications, it is expensive or impossible to re-collect the needed training data and rebuild the models.
如果降低重新收集训练数据的需求和代价,那将是非常不错的。在这些情况下,在任务领域之间进行知识的迁移或者迁移学习,将会变得十分有必要。
许多知识工程领域的例子,都能够从迁移学习中真正获益。举一个网页文件分类的例子。我们的目的是把给定的网页文件分类到几个之前定义的目录里。作为一个例子,在网页文件分类中,可能是根据之前手工标注的样本,与之关联的分类信息,而进行分类的大学网页。对于一个新建网页的分类任务,其中,数据特征或数据分布可能不同,因此就出现了已标注训练样本的缺失问题。因此,我们将不能直接把之前在大学网页上的分类器用到新的网页中进行分类。在这类情况下,如果我们能够把分类知识迁移到新的领域中是非常有帮助的。
For a classification task on a newly created Web site where the data features or data distributions may be different, there may be a lack of labeled training data.
当数据很容易就过时的时候,对于迁移学习的需求将会大大提高。在这种情况下,一个时期所获得的被标记的数据将不会服从另一个时期的分布。例如室内wifi定位问题,它旨在基于之前wifi用户的数据来查明用户当前的位置。在大规模的环境中,为了建立位置模型来校正wifi数据,代价是非常昂贵的。因为用户需要在每一个位置收集和标记大量的wifi信号数据。然而,wifi的信号强度可能是一个时间、设备或者其他类型的动态因素函数。在一个时间或一台设备上训练的模型可能导致另一个时间或设备上位置估计的性能降低。为了减少再校正的代价,我们可能会把在一个时间段(源域)内建立的位置模型适配到另一个时间段(目标域),或者把在一台设备(源域)上训练的位置模型适配到另一台设备(目标域)上。
To reduce the re-calibration effort, we might wish to adapt the localization model trained in one time period (the source domain) for a new time period (the target domain), or to adapt the localization model trained on a mobile device (the source domain) for a new mobile device (the target domain), as done in [7].
对于第三个例子,关于情感分类的问题。我们的任务是自动将产品(例如相机品牌)上的评论分类为正面和负面意见。对于这些分类任务,我们需要首先收集大量的关于本产品和相关产品的评论。然后我们需要在与它们相关标记的评论上,训练分类器。因此,关于不同产品牌的评论分布将会变得十分不一样。为了达到良好的分类效果,我们需要收集大量的带标记的数据来对某一产品进行情感分类。然而,标记数据的过程可能会付出昂贵的代价。为了降低对不同的产品进行情感标记的注释,我们将会训练在某一个产品上的情感分类模型,并把它适配到其它产品上去。在这种情况下,迁移学习将会节省大量的标记成本。
在这篇文章中,我们给出了在机器学习和数据挖掘领域,迁移学习在分类、回归和聚类方面的发展。同时,也有在机器学习方面的文献中,大量的迁移学习对强化学习的工作。然而,在这篇文章中,我们更多的关注于在数据挖掘及其相近的领域,关于迁移学习对分类、回归和聚类方面的问题。通过这篇综述,我们希望对于数据挖掘和机器学习的团体能够提供一些有用的帮助。
接下来本文的组织结构如下:在接下来的四个环节,我们先给出了一个总体的全览,并且定义了一些接下来用到的标记。
The rest of the survey is organized as follows. In the next four sections, we first give a general overview and define some notations we will use later.
然后,我们简短概括一下迁移学习的发展历程,同时给出迁移学习的统一定义,并将迁移学习分为三种不同的设置(在图2和表2中给出)。我们对于每一种设置回顾了不同的方法,在表3中给出。之后,在第6节,我们回顾了一些当前关于“负迁移”这一话题的研究,即那些发生在对知识迁移的过程中,产生负面影响的时候。在第7节,我们介绍了迁移学习的一些成功的应用,并且列举了一些已经发布的关于迁移学习数据集和工具包。最后在结论中,我们展望了迁移学习的发展前景。
In Section 7, we introduce some successful applications of transfer learning and list some published data sets and software toolkits for transfer learning research.
2005年,the Broad Agency Announcement (BAA) 05-29 of Defense Advanced Research Projects Agency (DARPA)’s Information Processing Technology Office (IPTO)给了迁移学习一个新使命:一个系统要能够去识别、学习之前任务,并将学到的知识、能力运用到新任务中。在这个定义中,迁移学习致力于从一个或多个源任务提取知识,并将这些知识运用于目标任务。不同于多任务学习,迁移学习更关心目标任务而不是均等地学习目标任务和源任务。源任务和目标任务的角色在迁移学习中不再对等。
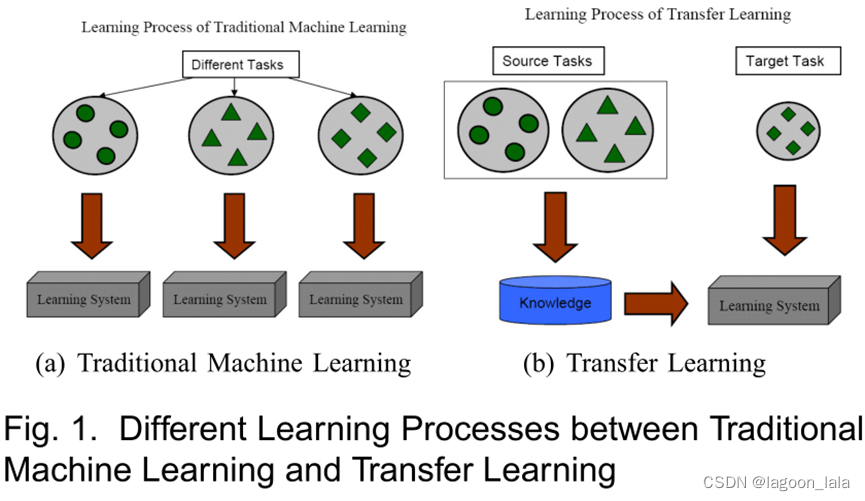
Fig. 1展示了传统学习和迁移学习的不同。就如我们看到的,传统机器学习试图去从头学习每个任务,而迁移学习尝试在当前任务缺乏高质量训练数据时,将之前任务中学到的知识应用到当前任务中。
2.3 迁移学习分类
迁移学习主要有以下三个研究问题:1)迁移什么,2)如何迁移,3)何时迁移。
“迁移什么”提出了迁移哪部分知识的问题。
“何时迁移”提出了哪种情况下迁移手段应当被运用。当源域和目标域无关时,强行迁移可能并不会提高目标域上算法的性能,甚至会损害性能。这种情况称为negative transfer。当前大部分关于迁移学习的工作关注于“迁移什么”和“如何迁移”,隐含着一个假设:源域和目标域彼此相关。然而,如何避免negative transfer是一个很重要的问题。
1. inductive transfer learning
目标任务和源任务不同,无论目标域与源域是否相同。
这种情况下,要用目标域中的一些已标注数据生成一个客观预测模型以应用到目标域中。除此之外,根据源域中已标注和未标注数据的不同情况,可以进一步将inductive transfer learning分为两种情况:
- 源域中大量已标注数据可用。这种情况下inductive transfer learning和multitask learning类似。然而,inductive transfer learning只关注于通过从源任务中迁移知识以便在目标任务中获得更高性能,然而multitask learning尝试同时学习源任务和目标任务。
- 源域中无已标注数据可用。这种情况下inductive transfer learning和self-taught learning相似。self-taught learning中,源域和目标域间的特征空间(原文为label spaces)可能不同,这意味着源域中的边缘信息不能直接使用。因此当源域中无已标注数据可用时这两种学习方法相似。
2. transductive transfer learning
源任务和目标任务相同,源域和目标域不同。这种情况下,目标域中无已标注数据可用,源域中有大量已标注数据可用。除此之外,根据源域和目标域中的不同状况,可以进一步将transductive transfer learning分为两类:
- 源域和目标域中的特征空间不同,即;
- 源域和目标域间的特征空间相同,但输入数据的边缘概率分布不同,即.
transductive transfer learning中的后一种情况与domain adaptation相关,因为文本分类、sample selection bias, covaritate shift的知识迁移都有相似的假设。
3. unsupervised transfer learning
与inductive transfer learning相似,目标任务与源任务不同但相关。然而,unsupervised transfer learning专注于解决目标域中的无监督学习问题,如聚类、降维、密度估计。这种情况下,训练中源域和目标域都无已标注数据可用。
迁移学习中不同分类的联系及相关领域被总结在Table2和Fig2中。
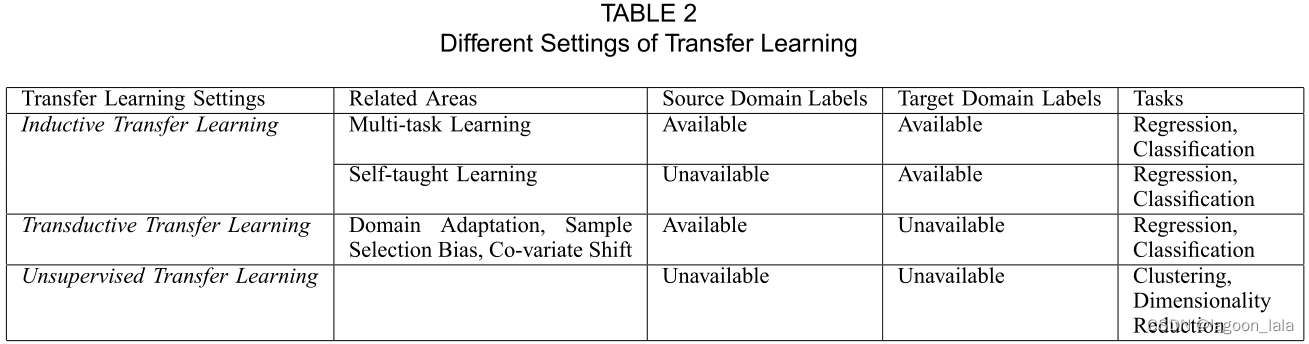
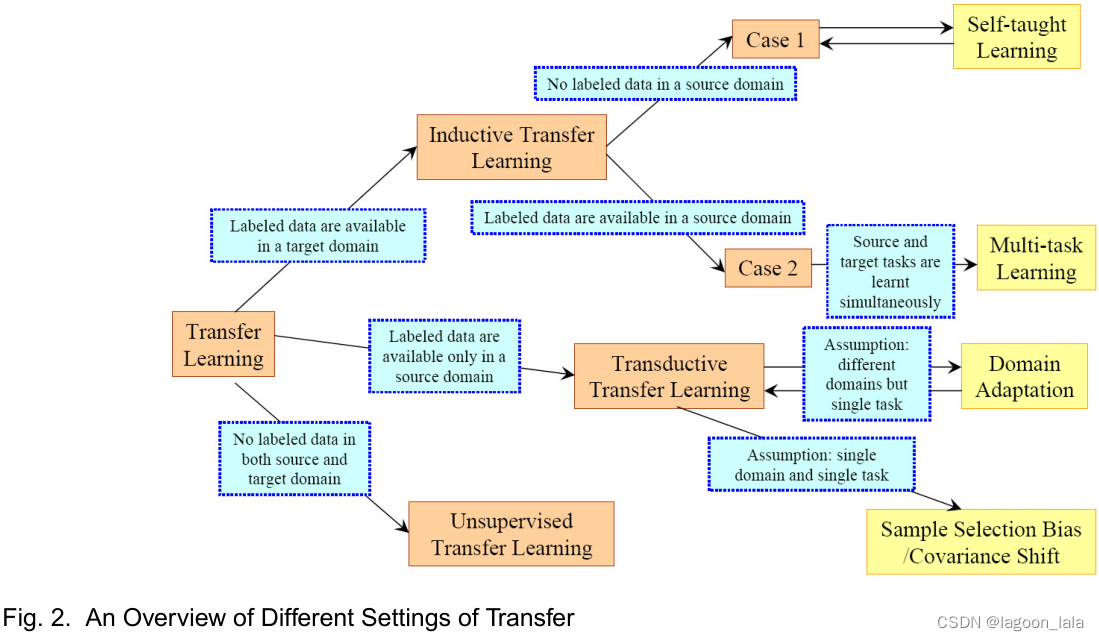
上述三种迁移学习可以基于“迁移什么”被分为四种情况,如Table3所示。

Table 4展示了不同迁移学习分类应用到的不同方法。

3 INDUCTIVE TRANSFER LEARNING
Definition 2 (Inductive Transfer Learning) Given a source domain DS and a learning task T_S, a target domain DT and a learning task T_T , inductive transfer learning aims to help improve the learning of the target predictive function f_T(·) in DT using the knowledge in DS and TS, where TS ≠ TT
定义2(推导迁移学习)给定源域DS和学习任务T_S、目标域DT和学习任务T_T,推导迁移学习旨在利用DS和TS中的知识来帮助改进DT中目标预测函数f_T(·)的学习,其中TS≠TT。
基于上述归纳迁移学习设置的定义,需要目标域中的几个标记数据作为训练数据来推导目标预测函数。如第2.3节所述,此设置有两种情况:(1)源域中的已标记数据可用;(2)源域中的已标记数据不可用,而源域中的未标记数据可用。在这种情况下,大多数迁移学习方法都集中在前一种情况。
3.1 Transferring Knowledge of Instances
推导迁移学习情况的实例迁移方法很直观:尽管源域数据不能直接重用,但目标域中仍有某些数据部分可以与少数标记数据一起重用。
戴等人[6]针对推导迁移学习问题,提出了一种改进的Boost算法TrAdaBoost,它是AdaBoost算法的扩展。TrAdaBoost假设源和目标域数据使用完全相同的特征和标签集,但这两个域中数据的分布不同。此外,TrAdaBoost假设,由于源域和目标域之间的分布不同,一些源域数据可能有助于学习目标域,但其中一些可能不会甚至可能是有害的。它试图迭代地重新加权源域数据,以减少“坏”源数据的影响,同时鼓励“好”源数据为目标域做出更多贡献。对于每一轮迭代,TrAdaBoost在加权的源和目标数据上训练基本分类器。该误差仅计算在目标数据上。此外,TrAdaBoost使用与AdaBoost相同的策略来更新目标域中错误分类的样本,而使用与AdaBoost不同的策略来更新源域中错误分类的源示例。文[6]中也给出了TrAdaBoost的理论分析。
姜和翟伟[30]提出了一种基于条件概率P(Yt|Xt)和P(Ys|Xs)之间的差异的启发式方法,从源域中去除“误导性”的训练样本。廖等人。[31]提出了一种新的主动学习方法,利用源域数据选择待标注的目标域中的未标注数据。为了提高分类性能,Wu和Dietterich[53]集成了源域(辅助)数据的支持向量机框架。
3.2 Transferring Knowledge of Feature Representations
推导迁移学习问题的特征表示迁移方法旨在找到“好的”特征表示,以最小化领域差异和分类或回归模型误差。对于不同类型的源域数据,找到“好的”特征表示的策略是不同的。如果源域中有大量的标记数据可用,则可以使用监督学习方法来构造特征表示。这类似于多任务学习领域的常见特征学习[40]。如果源域中没有可用的标记数据,则提出无监督学习方法来构造特征表示。
3.2.1 Supervised Feature Construction
推导迁移学习环境下的有监督特征构建方法类似于多任务学习中使用的方法。基本思想是学习在相关任务中共享的低维表示法。此外,学习到的新表示还可以减少每个任务的分类或回归模型错误。Argyriou等人。[40]提出了一种用于多任务学习的稀疏特征学习方法。在推导迁移学习设置中,可以通过解决如下给出的优化问题来学习共同特征。
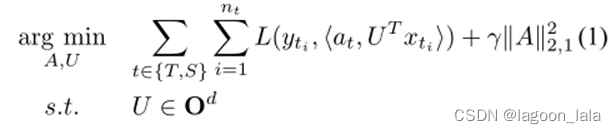
在这个等式中看起来复杂, 其实就是一个主要优化目标和一个正则项组成的.
优化目标同时考虑源域和目标域的Loss, 输入不再是x, 而是经过映射转换的<a,U^T x>, 再加上一个对参数a组成的矩阵A的正则项.
优化问题(1)可进一步转化为等价的凸优化形式,并可有效地求解。在后续工作中,Argyriou等人。[41]提出了一种用于多任务结构学习的矩阵谱正则化框架。
提出了一种凸优化算法,用于从一系列相关预测任务中同时学习元先验和特征权重。元优先级可以在不同的任务之间转移。Jebara[43]提出用支持向量机选择特征进行多任务学习。Ruckert等人。[54]设计了一种基于核的推导迁移方法,旨在为目标数据找到合适的核.
3.2.2 Unsupervised Feature Construction
在[22]中,Raina et al.提出将稀疏编码[55]这一无监督的特征构造方法应用于迁移学习的高层特征学习。这种方法的基本思想由两个步骤组成。
在第一步中,较高级别的基向量b={b1,b2,…,bs}通过如下所示解决优化问题(2)来在源域数据上学习,
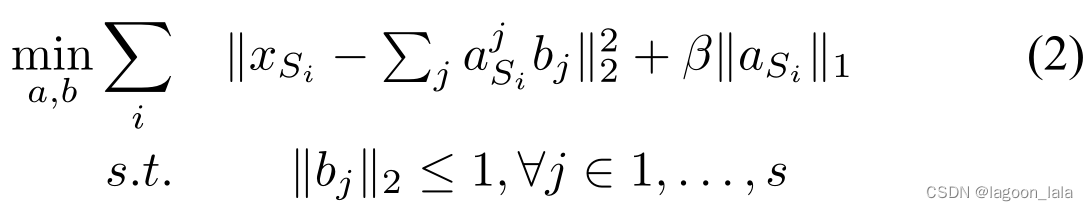
其中, a是x在基b上的新表示, 后面一项是特征的正则项. 这个优化是让新构建的更少的特征尽可能描述源域数据.
在学习基向量b之后,在第二步骤中,对目标域数据应用优化算法(3),以基于基向量b学习更高级别的特征。
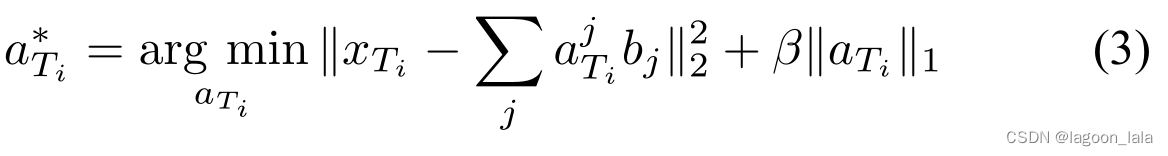
此时的b已经固定, 优化目标是用已知的b尽可能描述目标域数据
最后,可将判别算法应用于具有相应标签的新特征值a上,以训练分类或回归模型以用于目标领域。这种方法的一个缺点是,在优化问题(2)中在源域上学习的所谓的更高级别的基向量可能不适合在目标域中使用。
近年来,多种学习方法被引入到迁移学习中。在[44]中,Wang和Mahadean提出了一种基于Prorustes分析的无对应流形对齐方法,该方法可以通过对齐的流形来跨域传递知识。
4 TRANSDUCTIVE TRANSFER LEARNING
直推式迁移学习(Transductive Transfer Learning)一词最早是由Arnold等人提出的。[58]它们要求源任务和目标任务相同,尽管域可以不同。在这些条件之上,他们进一步要求目标域中的所有未标记数据在训练时都是可用的,但我们认为这一条件可以放宽;相反,在我们对直推式迁移学习设置的定义中,我们只要求在训练时看到部分未标记目标数据,以获得目标数据的边际概率。
请注意,“Transductive”一词有多种含义。
1.在传统的机器学习设置中,Transductive- Learning [59]指的是这样一种情况,即要求在训练时看到所有测试数据,并且所学习的模型不能重复用于未来的数据。因此,当一些新的测试数据到达时,它们必须与所有现有数据一起分类。
2.但是,在我们对迁移学习的分类中,我们使用直推式这一术语来强调这样一个概念,在这种类型的迁移学习中,任务必须是相同的,并且在目标领域中必须有一些未标记的数据可用。
定义3(直推式迁移学习)给定源域D_S和对应的学习任务T_S、测试域D_T和对应的学习任务T_T,直推式迁移学习的目的是利用D_S和T_S中的知识改进目标预测函数F_T(·)在D_T中的学习,其中D_S≠D_T且T_S=T_T。此外,一些未标记的目标域数据必须在训练时可用。
这一定义涵盖了Arnold等人的工作。[58]因为后者考虑了领域适应,其中源数据和目标数据的边际概率分布之间存在差异;即任务相同但领域不同。
This definition covers the work of Arnold et al. [58], since the latter considered domain adaptation, where the difference lies between the marginal probability distributions of source and target data; i.e., the tasks are the same but the domains are different.
类似于传统的直推式学习环境,目的是充分利用未标记的测试数据进行学习,在直推式迁移下的分类方案中, 我们还假设给出了一些目标域的未标记数据.
在上面的直推式迁移学习定义中,源任务和目标任务是相同的,这意味着人们可以通过一些未标记的目标域数据来调整在源域中学习的预测函数,以便在目标域中使用。如第2.3节所述,该设置可以分为两种情况:
(A)源域和目标域之间的特征空间不同,Xs≠Xt,
以及(B)域之间的特征空间相同,Xs=Xt,但输入数据的边际概率分布不同,P(Xs)≠P(Xt)。这类似于领域适应和样本选择偏差的要求。以下各节所述的大多数办法都与上述情况(b)有关。
4.1 Transferring the Knowledge of Instances
在直推式性迁移学习环境中,大多数实例迁移方法都是基于重要性抽样的。为了了解基于重要性抽样的方法如何在这种情况下有所帮助,我们首先回顾经验风险最小化(ERM)问题[60]。通常,我们可能希望通过最小化期望风险来学习模型的最优参数θ∗,
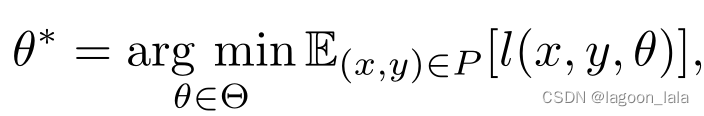
其中l(x,y,θ)是依赖于参数θ的损失函数。然而,由于概率分布P很难估计,所以我们选择最小化ERM代替P,
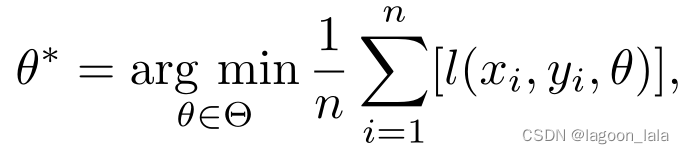
其中n是训练数据的大小。
在直推式迁移学习环境中,我们希望通过最小化期望风险来学习目标领域的最优模型,
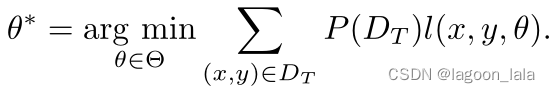
然而,由于在训练数据中没有观察到目标领域中的标记数据,所以我们必须从源域数据中学习模型。如果P(Ds)=P(Dt),则通过解决以下用于目标域的优化问题来简单地学习模型,
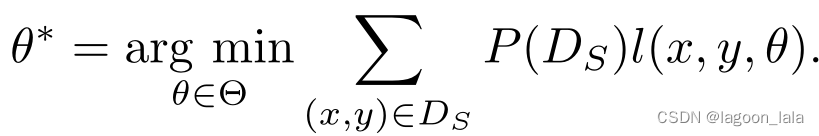
否则,当P(Ds)≠P(Dt)时,我们需要修改上述优化问题,以学习对目标领域具有高泛化能力的模型,如下所示:
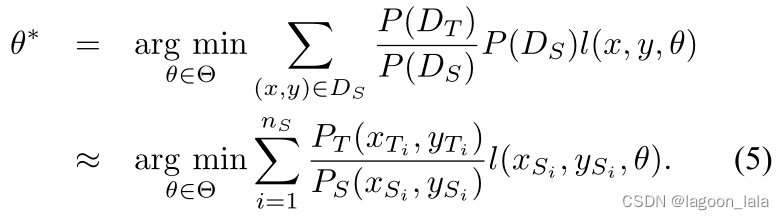
因此,通过向每个实例(x,y)添加不同的惩罚值对应的权重P_T(x,y)/P_S(x,y), 从而学习目标领域的精确模型
如果我们能够估计每个实例的P(x_{S_i})/P(x_{T_i}),我们就可以解决直推式性迁移学习问题.
P(x_{S_i}), P(x_{T_i})的估计可以通过构造简单的分类问题独立完成。
Fan等人。[35]通过使用各种分类器来估计概率比,进一步分析了存在的问题。
Huang等人的研究成果。[32]提出了一种核均值匹配(KMM)算法.
它直接通过在再生核希尔伯特空间(RKHS)中匹配源域数据和目标域数据之间的平均值来学习P(x_{S_i})/P(x_{T_i})。
KMM可以重写为以下二次规划(QP)优化问题。
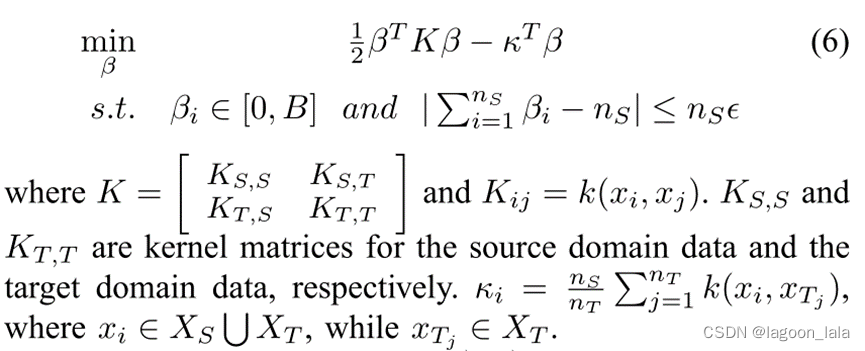
可以证明βi=P(x_{S_i})/P(x_{T_i})
它的优点是避免直接估计P(x_{S_i}), P(x_{T_i}), 当数据集的大小很小时,这是困难的
Sugiyama等人。[34]提出了一种称为Kullback-Leibler重要性估计程序(KLIEP)的算法来估计P(x_{S_i})/P(x_{T_i})
直接,基于Kullback-Leibler散度的最小化。KLIEP可以与交叉验证相结合,在两个步骤中自动执行模型选择:(1)估计源域数据的权重;(2)对重新加权的数据进行训练。
Bickel等人。[33]通过推导核-逻辑回归分类器,将这两个步骤结合在一个统一的框架中。除了样本重新加权技术外,Dai等人也提出了自己的观点。[28]扩展了一种传统的朴素贝叶斯分类器,用于转导迁移学习问题。有关协变量偏移或样本选择偏差的重要性抽样和重新加权方法的更多信息,读者可以参考Quion ero-Candela等人最近出版的一本书[29]。也可以参考Fan和Sugiyama在ICDM-08中关于样本选择偏差的教程。(Tutorial slides can be found at http://www.cs.columbia.edu/∼fan/PPT/ICDM08SampleBias.ppt现在已经找不到了)
4.2 Transferring Knowledge of Feature Representations
在直推式性迁移学习环境下,大多数特征表征迁移方法都在无监督学习框架下进行。
Blitzer等人。[38]提出了一种结构化对应学习算法(SCL),该算法扩展了[37],利用目标领域的未标记数据来提取一些相关特征,以减少两个域之间差异。SCL的第一步是在来自两个域的未标记数据上定义一组枢轴特征(枢轴特征的数量由m表示)。然后,SCL从数据中删除这些轴心特征,并将每个轴心特征视为新的标签向量。可以构造m个分类问题。通过假设每个问题可以由如下所示的线性分类器解决,

最后,将标准的判别算法应用于增强的特征向量来建立模型。扩充的特征向量包含附加有新的共享特征θxi的所有原始特征xi。
如[38]所述,如果枢轴特征设计良好,则学习的映射θ编码来自不同领域的特征之间的对应关系。尽管Ben-David和Schuller[61]通过实验证明SCL可以缩小领域之间的差异,但如何选择枢轴特征是困难的,并且依赖于领域。在[38]中,Blitzer et al.。使用启发式方法为自然语言处理(NLP)问题(如句子标记)选择枢轴特征。在他们的后续工作中,研究人员建议使用交互信息(MI)来选择枢轴特征,而不是使用更启发式的标准[8]。MI-SCL试图找到一些对源域中的标签具有高度依赖性的轴心特征。
NLP领域中的迁移学习有时被称为领域适应。在这方面,Daumé[39]提出了一种用于NLP问题的核映射函数,该函数将来自源域和目标域的数据映射到高维特征空间,在高维特征空间中使用标准的判别学习方法来训练分类器。然而,所构造的核映射函数是领域知识驱动的。将内核映射推广到其他领域或应用程序并不容易。Blitzer等人。[62]分析了最小化来源和目标经验风险凸组合的算法的一致收敛界。
在[36]中,Dai et al.。提出了一种基于共聚类的标签信息跨域传播算法。在[63]中,Xing et al.。提出了一种桥接精化算法,将Shift-Tunware分类器预测的标签向目标分布修正,并以训练数据和测试数据的混合分布为桥梁,更好地将训练数据转换为测试数据。在[64]中,Ling et al.。提出了一种跨域迁移学习问题的谱分类框架,通过引入目标函数来寻求域内监督和域外内在结构的一致性。在[65]中,Xue et al.。提出了一种跨域文本分类算法,扩展了传统的概率潜在语义分析(PLSA)算法,将已标记的文本分类算法和基于概率潜在语义分析(PLSA)的文本分类算法相结合将来自不同但相关领域的未标记数据整合到一个统一的概率模型中。新模型称为 Topicbridged PLSA,或 TPLSA。
Pan等人最近提出了通过降维进行迁移学习。 [66]。在这项工作中,潘等人。利用最初为降维而设计的最大平均差异嵌入(MMDE)方法来学习低维空间,以减少不同域之间的分布差异,以进行直推式迁移学习。然而,MMDE 可能会受到其计算负担的影响。因此,在 [67] 中,Pan 等人。进一步提出了一种有效的特征提取算法,称为迁移分量分析(TCA),以克服 MMDE 的缺点。
7. 迁移学习的应用
APPLICATIONS OF TRANSFER LEARNING
迁移学习工具箱:加州大学伯克利分校的研究人员为迁移学习提供了MATLAB工具包13。该工具包包含迁移学习的算法和基准数据集。此外,它还为开发和测试迁移学习的新算法提供了一个标准平台。
Toolboxes for Transfer Learning: Researchers at UC Berke-ley provided a MATLAB toolkit for transfer learning 13. The toolkit contains algorithms and benchmark data sets for transfer learning. In addition, it provides a standard platform for developing and testing new algorithms for transfer learning.
只有一个MATLAB工具包, 没有python的. standard platform不知道指的是什么
这个工具包的地址:
http://multitask.cs.berkeley.edu/
但是这个网址已经打不开了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









