






 本文综述了迁移学习在机器学习领域的应用,特别是分类、回归和聚类问题。介绍了迁移学习的基本概念、历史和发展,以及其与传统机器学习的区别。文章还讨论了迁移学习的分类及其在实际场景中的应用。
本文综述了迁移学习在机器学习领域的应用,特别是分类、回归和聚类问题。介绍了迁移学习的基本概念、历史和发展,以及其与传统机器学习的区别。文章还讨论了迁移学习的分类及其在实际场景中的应用。
本文是A Survey on Transfer Learning的译文。着重翻译了论文前半部分的概念部分,后半部分公式推导部分暂时未翻译。
本文成文时间较早,讲述机器学习背景下的迁移学习。
摘要—在大量机器学习和数据挖掘算法中一个重要假设是训练和未来数据必须在相同的特征空间,并且有相同分布。然而,在现实世界应用中,这个假设难以维持。例如,我们有时候在一个兴趣域有一个分类任务,但我们只有另一个兴趣域内的有效训练数据。然而后者兴趣域内的数据可能处于一个不同的特征空间或遵循一个不同的数据分布。这种情况下,知识迁移如果做的好的话就可以在避免昂贵的数据标注成本的情况下取得极大的性能提升。近年来,迁移学习已经逐渐整合成了一个解决这类问题的框架。本篇survey着重于categorize和review当前迁移学习在分类、回归、聚类问题上的进展。本篇survey中我们会讨论迁移学习与其他机器学习方法如domain adaptation、multitask learning和sample selection bias和covariate shift的联系。我们也会探索迁移学习研究中将来潜在的方法。
1 INTRODUCTION
数据挖掘和机器学习技术早已在许多工程领域实现了巨大成功,如分类、回归和聚类。然而,大量机器学习方法都有一个共有假设:训练和测试数据必须从相同的特征空间去取得,且具有相同分布。当分布发生改变时,统计模型必须用新的训练数据重构。在许多现实运用中,重新收集需要的训练数据或重构模型可能代价非常高昂甚至不可能。如果能够减轻重新收集训练数据的需求就会十分可爱。因此,任务域间的知识迁移或者迁移学习就十分令人向往。
许多knowledeg engineering领域的问题都可以从迁移学习中受益。一个例子就是Web-document classification,这个任务的目标是将一个给定的Web-document分到几个之前定义的目录中。作为一个例子,在Web-document classification领域中,一个被标注的样例可能是根据之前手工标注的样本学到的分类信息而分类的大学网页。对于另一个分类新创建的网页的任务,数据特征和分布可能不同,这就存在已标注的训练数据缺失的问题。存在的问题就是我们不能直接将之前的网页分类器运用到当前任务中。这种情况下,如果能将之前的分类知识运用到新域就会十分可爱。
当数据会十分容易过时时,迁移学习的需要就会出现。这种情况下,前阶段获得的已标注数据可能与之后阶段的数据遵循不同分布。例如,室内wifi定位问题,目的是基于之前收集到的wifi数据探测用户的当前位置。在大尺度环境中根据测定的wifi数据去建立定位模型是一项十分昂贵而不美丽的工作,因为一个用户需要在每个位置标注大量收集到的wifi信号数据。然而,wifi强度数据可能是一个时间、设备或其他动态因素的函数。在一个时间或一个设备上训练的模型可能或导致另一个时间或设备上位置估计的性能降低。为减小再校准成本,我们或许可以将在一个时间段内训练(the source domain)的位置模型适配到另一个新的时间段(the target domain),或者将在一个设备上训练(the source domain)的位置模型适配到另一个新的设备(the target domain)。
第三个例子,情感分类balabalabala不想翻译了。
本文中,我们将对迁移学习在机器学习和数据挖掘领域中分类、回归、聚类中的应用做一个综合概述。迁移学习在机器学习领域中的强化学习方面已经有大量文献。然而,本文中我们只聚焦于迁移学习在分类、归回、聚类方面的应用,因为这些方面与数据挖掘联系更加紧密。通过做这个survey,我们希望能为数据挖掘和机器学习社区提供一个更易用的资源。
本文剩下部分按如下思路整理:接下来的四个部分中,我们首先给出一个综述并且定义一些之后用的符号。之后,我们简短地介绍迁移学习的历史,给出一个迁移学习统一的定义,并将迁移学习分为三类(如所Table 2和Fig. 2所示)。对于每个类别,我们回顾不同的方法,具体细节如Table 3所示。之后,第六部分中我们回顾一些在“negative transfer”方面的研究,这些返生在知识迁移对target learning有负面影响。第七部分,我们介绍一些迁移学习的成功应用,并且列出一些已经发布的数据集和用作迁移学习的软件库。最后,总结全文并在第八部分提出展望。
2 OVERVIEW
2.1 迁移学习简史
传统数据挖掘和机器学习算法根据之前收集的有标记或无标记训练数据训练统计模型以根据将来数据做预测。半监督分类通过利用大量未标注数据和少量已标注数据提出了有标注数据可能太少以致不能建立一个好分类器的问题。对不完美数据集的有监督和半监督学习的不同已经有人研究过;比如,Zhu and Wu [18] 已经研究过如何处理noisy class-label problems。Yang et al. considered cost-sensitive learning [19] when additional tests can be made to future samples.然而,他们大多数都假设已标注数据和未标注数据都有相同分布。不同的是,迁移学习允许域、任务、训练集和测试集的分布不同。现实世界中我们观察到迁移学习的大量例子。例如,我们可以发现对苹果的识别可能有助与识别桃子。相同地,学习电子琴可能有助于学习钢琴。对迁移学习的研究就是由人类可以机智地利用之前所学到的知识去更快地或更好地解决新问题所激发的。
从1995年开始,顶着不同的名字,迁移学习开始越来越引起注意:learning to learn, life-long learning, knowledge transfer, inductive transfer, multitask learning, knowledge consolidation, context-sensitive learning, knowledge-based inductive bias, meta learning, and incremental/cumulative learning [20]. 在这些中,迁移学习的一个紧密联系的学习技术是multitask learning framework [21],它试图去同时学习不同任务。多任务学习的一个典型方法是去发现可以有益于单个任务的共同(潜在)特征。
2005年,the Broad Agency Announcement (BAA) 05-29 of Defense Advanced Research Projects Agency (DARPA)’s Information Processing Technology Office (IPTO)给了迁移学习一个新使命:一个系统要能够去识别、学习之前任务,并将学到的知识、能力运用到新任务中。在这个定义中,迁移学习致力于从一个或多个源任务提取知识,并将这些知识运用于目标任务。不同于多任务学习,迁移学习更关心目标任务而不是均等地学习目标任务和源任务。源任务和目标任务的角色在迁移学习中不再对等。
Fig. 1展示了传统学习和迁移学习的不同。就如我们看到的,传统机器学习试图去从头学习每个任务,而迁移学习尝试在当前任务缺乏高质量训练数据时,将之前任务中学到的知识应用到当前任务中。
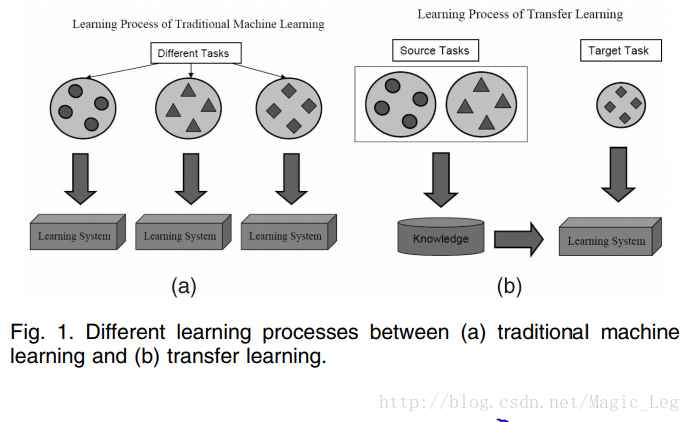
今天,迁移学习已经出现在几个顶尖场合。在我们具体给出迁移学习的不同分类前,我们首先描述本文中用到的记法。
2.2 记法和定义
domain
D
由两部分组成:一个特征空间
给定domian
D={X,P(X)}
,一个task由两部分组成:一个标签空间
Y
和一个目标预测函数
简化起见,本文中我们只考虑一个源域
DS
一个目标域
DT
。更准确点,用
DS={(xS1,yS1),...,(xSn,ySn)},xSi∈Xs,ySi∈Ys
来表示源域。以文档分类为例,
DS
是文档对象向量及对应的true或false标签的集合。相似地有目标域记法
DT
,一般有
0≤nT≪nS
。
现在我们给出迁移学习的统一定义:
Definition 1 (Transfer learning): 给定源域 DS 和学习任务 TS ,一个目标域 DT 和学习任务 TT ,迁移学习致力于用 DS 和 TS 中的知识,帮助提高 DT 中目标预测函数 fT(⋅) 的学习。并且有 DS≠DT 或 TS≠TT 。
在上面定义中, D={X,P(X)} , DS≠DT 意味着源域和目标域实例不同( XS≠XT )或者源域和目标域边缘概率分布不同( PS(X)≠PT(X) )。同理 T={Y,P(Y|X)} , TS≠TT 意味着源域和目标域标签不同( YS≠YT )或者源域和目标域条件概率分布不同( P(YS|XS)≠P(YT|XT) )。当源域和目标域相同且源任务和目标任务相同,则学习问题是一个传统机器学习问题。
以文档分类为例,域不同有以下两种情况:
1. 特征空间不同,即
DS≠DT
。可能是文档的语言不同。
2. 特征空间相同但边缘分布不同,即
P(XS)≠P(XT)
。可能是文档主题不同。
给定域
DS
和
DT
,学习任务不同可能有以下两种情况:
1. 域间标签空间不同,即
YS≠YT
。可能是源域中文档需要分两类,目标域需要分十类。
2. 域间条件概率分布不同,即
P(YS|XS)≠P(YT|XT)
。
除此之外,当两个域或者特征空间之间无论显式或隐式地存在某种关系时,我们说源域和目标域相关。
2.3 迁移学习分类
迁移学习主要有以下三个研究问题:1)迁移什么,2)如何迁移,3)何时迁移。
“迁移什么”提出了迁移哪部分知识的问题。
“何时迁移”提出了哪种情况下迁移手段应当被运用。当源域和目标域无关时,强行迁移可能并不会提高目标域上算法的性能,甚至会损害性能。这种情况称为negative transfer。当前大部分关于迁移学习的工作关注于“迁移什么”和“如何迁移”,隐含着一个假设:源域和目标域彼此相关。然而,如何避免negative transfer是一个很重要的问题。
基于迁移学习的定义,我们归纳了传统机器学习方法和迁移学习的异同见Table 1。

1. inductive transfer learning
目标任务和源任务不同,无论目标域与源域是否相同。
这种情况下,要用目标域中的一些已标注数据生成一个客观预测模型
fT(⋅)
以应用到目标域中。除此之外,根据源域中已标注和未标注数据的不同情况,可以进一步将inductive transfer learning分为两种情况:
- 源域中大量已标注数据可用。这种情况下inductive transfer learning和multitask learning类似。然而,inductive transfer learning只关注于通过从源任务中迁移知识以便在目标任务中获得更高性能,然而multitask learning尝试同时学习源任务和目标任务。
- 源域中无已标注数据可用。这种情况下inductive transfer learning和self-taught learning相似。self-taught learning中,源域和目标域间的特征空间(原文为label spaces)可能不同,这意味着源域中的边缘信息不能直接使用。因此当源域中无已标注数据可用时这两种学习方法相似。
2. transductive transfer learning
源任务和目标任务相同,源域和目标域不同。这种情况下,目标域中无已标注数据可用,源域中有大量已标注数据可用。除此之外,根据源域和目标域中的不同状况,可以进一步将transductive transfer learning分为两类:
- 源域和目标域中的特征空间不同,即
XS≠XT
;
- 源域和目标域间的特征空间相同,
XS=XT
,但输入数据的边缘概率分布不同,即
P(XS)≠P(XT)
.
transductive transfer learning中的后一种情况与domain adaptation相关,因为文本分类、sample selection bias, covaritate shift的知识迁移都有相似的假设。
3. unsupervised transfer learning
与inductive transfer learning相似,目标任务与源任务不同但相关。然而,unsupervised transfer learning专注于解决目标域中的无监督学习问题,如聚类、降维、密度估计。这种情况下,训练中源域和目标域都无已标注数据可用。
迁移学习中不同分类的联系及相关领域被终结在T able2和Fig2中。
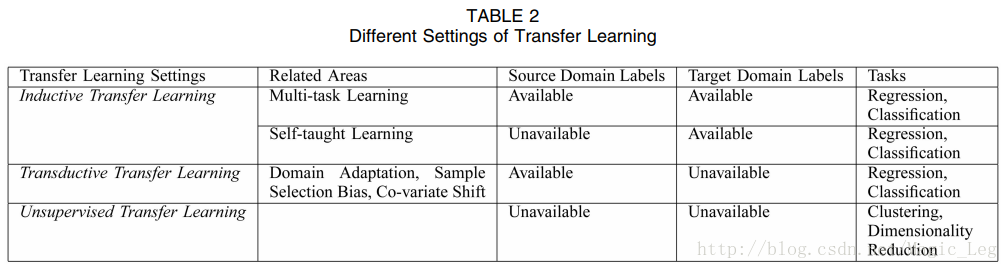
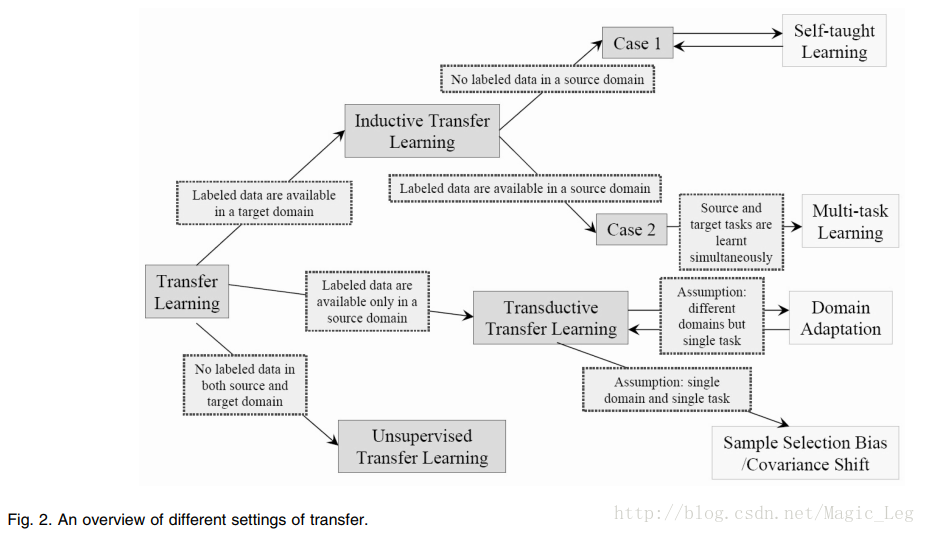
上述三种迁移学习可以基于“迁移什么”被分为四种情况,如Table3所示。Table3中已经描述的比较详细,在此不对这部分作翻译。

Table 4展示了不同迁移学习分类应用到的不同方法。

3 Inductive Transfer Learning
Definition 2 (Inductive Transfer learning): 给定源域、源任务、目标域、目标任务: DS,TS,DT,TT ,Inductive Transfer Learning目标是在 TS≠TT 的情况下利用 DS,TS 的知识提升 DT 中的目标预测函数 fT(⋅) 。
基于上述对Inductive Transfer Learning的定义,用目标域中的一小部分已标注数据作为训练数据以诱导(induce)目标预测函数是必要的。
3.1 Transferring Knowledeg of Instances
Inductive Transfer Learning的instance-transfer approach直观上很吸引眼球:尽管源域数据不能直接重用,但还是有一部分特定数据可以和目标域中的一些已标注数据实现重用。
Dai et al. [6]提出了一个boosting algorithm, TrAdaBoost, 它是AdaBoost algorithm的一个扩展,以处理inductive transfer learning问题。TrAdaBoost假设源域和目标域数据使用相同的特征集和标签集,但两个域中的数据分布不同。除此之外,因为源域和目标域的分布不同,因此TrAdaBoost进一步假设源域中的部分数据对目标域的学习有用,另一部分数据没用甚至有害。它尝试对源域数据迭代式地重加权以减轻坏的源域数据对目标域的影响,增强好数据的增益。迭代的每一轮,TrAdaBoost在加权过的源数据和目标数据上训练基本分类器。只在目标数据上计算错误。TrAdaBoost在更新目标域上的错误分类样例上和AdaBoost使用相同策略,在更新源域上的错误分类源样例上和AdaBoost使用不同策略。TrAdaBoost的具体理论分析见[6]。
[30]提出了一种基于不同条件概率
P(yT|xT),P(yS|xS)
的从源域中移除误导性训练样例的启发式方法。[31]提出了一种。。。。不想翻。。。。。
3.2 Transferring Knowledge of Feature Representations
Inductive Transfer Learning的feature-representation-transfer approach致力于找到好的特征表示去最小化域差异以及分类和回归模型误差。不同类型的源数据有找好特征表示的不同策略。如果源域中大量已标注数据可用,有监督方式可以被用于构建特征表示。这有点像multitask learning中的common feature learning。如果源域中没有已标注数据可用,无监督方式就要被使用。
3.2.1 有监督特征构建
Inductive Transfer Learning中的有监督特征构建与multitask learning中使用的方法类似。基本想法是去构建一个可以跨相关任务的低维表示,而且学习到的新表示也可以用于减小每个任务的分类或回归误差。Argyriou et al. [40]提出了一种针对multitask learning的稀疏特征学习方法。在Inductive Transfer Learning中,可以通过一个优化问题来学习公共特征,见下式:
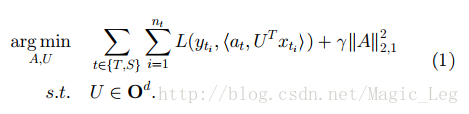
S
和
balabalalalalala还是一些进一步工作的一句话简述,感兴趣可以看原文。
3.2.2 无监督特征构建
[22]提出以应用稀疏编码,他是一种无监督特征构建方法,以在迁移学习中学习高维特征。这种想法基本由两部构成:第一步,通过在源域数据上求解(2)式得到更高层的偏置向量
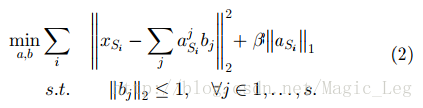
具体参数见原文
得到偏置向量
b
之后,第二步在目标域数据上应用(3)式以学习基于偏置向量
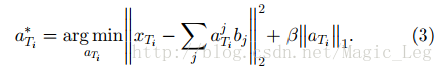
最后,目标域上,判别算法被应用到
a∗Ti
和对应的标签以训练分类和回归模型。这种方法的一个缺点是(2)式中在源域上学到的所谓更高维偏置向量
b
<script type="math/tex" id="MathJax-Element-66">b</script>可能在目标域上并不适用。
最近,manifold learning methods被应用于迁移学习,可见[44]。
3.3 Transferring Knowledge of Parameters
大多数inductive transfer learning的parameter-transfer approaches都假设相关任务的不同模型之间共享一些参数或更高层的超参数分布。这部分描述的大多数方法包括一个规则化框架一个多层Bayes框架都被设计在multitask learning下工作。然而,它们可以很容易地为迁移学习修改。就像之前提到的,multitask learning试图同时完美地学习源任务和目标任务,而迁移学习只想利用源域数据提升目标域数据下的性能。因此,multitask learning中对源域和目标域数据的损失函数的权重都一样,而对迁移学习这两者的权重则不同。直观地,我们可以对目标域山上的损失函数赋予更高的权重以确保目标域上的效果更好。
[45]提出了一个高效的算法叫MT-IVM,基于 Gaussian Processes,以处理multitask learning任务。MT-IVM试图通过共享相同 GP prior 以在多任务情况下学习Gaussian Processes的参数。[46]也在GP情况下调研了multitask learning,
3.4 Transferring Relational Knowledge
4 Transductive Transfer Learning
4.1 Transferring the Knowledge of Instances
4.2 Transferring Knowledge of Feature Representations
5 Unsupervised Transfer Learning
5.1 Transferring Knowledge of Feature Representations
6 Transfer Bounds and Negative Transfer
7 Applications of Transfer Learning
目前,至少有两个基于迁移学习的国际比赛。ECML/PKDD-2006竞赛内容是设计一个个性化垃圾邮件过滤系统。首先根据已标注(“垃圾”、“非垃圾”)的邮件训练一个分类器。对每个新邮件用户,适配这个模型给他。但靠模型的数据分布可能和新用户不同,因此这是一个生成式迁移学习问题,目标是将老的邮件过滤模型在更少训练数据和更短训练时间的情况下适配给新情境。
第二个数据集是ICDM-2007中发布的,任务是估计不同时间段内获得的WiFi信号估计用户室内位置。在不同时段,WiFi信号的强度分布可能是时间、位置、设备的不同函数。这个任务中迁移学习被用于减小数据重标注开销。

















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









