






第二讲 基础语法
一、注释
- 概念
注释就是对代码的解释和说明。其目的是让人们能够更加轻松地了解代码。为代码添加注释,是十分必须要的,它参与也不影响程序的编译和运行。
(二)作用
1、对程序的思路进行描述。
2、对程序进行调试:通过注释的方式,快速定位出现错误的代码位置。
(三)分类
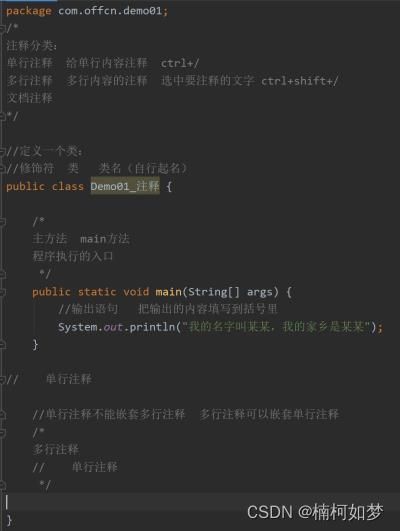
1、单行注释
格式: //注释内容 ctrl+/
2、多行注释
格式: /* 注释内容 */ ctrl+shift+/
3、文档注释
格式:/** 注释内容 */
- 关键字
- 概述
- 概念
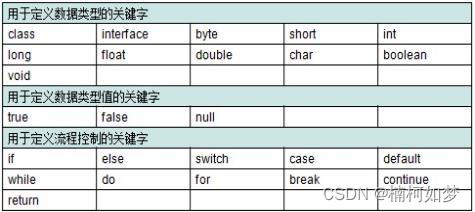
关键字是被Java语言赋予特殊含义,具有专门用途的单词,比如之前接触的class,public,static,void均为Java已经预设好的。可以先把Java关键字理解为“命令”!
- 特点
1、组成关键字的字母全部小写。
2、常用的代码编辑器,针对关键字有特殊的颜色标记,非常直观,所以我们不需要去死记硬背,在今后的学习中重要的关键字也会不断的出来。
(二)关键字展示
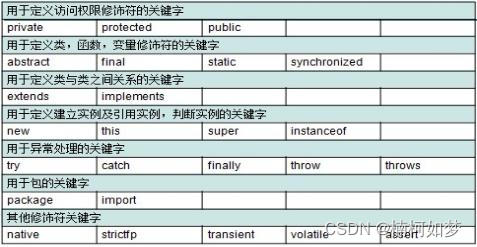
注意事项:
1、全部小写
2、自己起名字的时候,不要和关键字重名
3、有两个保留字:goto、const,在当前版本不使用,但是以后是否使用未知。
边学边积累(不用背)
三、标识符
(一)什么是标识符
其实标识符就是名称的意思,所有的名称都统称为标识符。
Java中经常要定义类、方法、变量(后面会学习到),在定义他们时总要给它们起名字,这些名字就是标识符。我们要学习的就是标识符的规范。凡是可以自己起名字的地方都叫做标识符。
- 命名规则
硬性要求
标识符可以包含英文字母26个(区分大小写)、0-9数字 、$(美元符号)和_(下划线)。
标识符不能以数字开头。
标识符不能是关键字。
- 命名规范
类名规范:首字母大写,后面每个单词首字母大写(大驼峰式)。
方法名规范: 首字母小写,后面每个单词首字母大写(小驼峰式)。
变量名规范:首字母小写,后面每个单词首字母大写(小驼峰式)。
要做到见名知意。
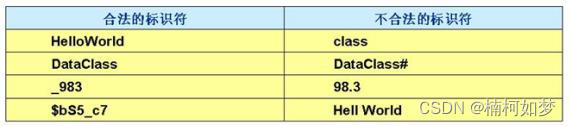
练习:以下标识符是否符合规则:
date、$2011、_date、D_$date
123.com、2com、height#、for、if
四、数据类型
(一)概念
软件就是用来处理数据的程序。可以把软件分为两个部分,一个部分是“数据”;另一个部分是“数据处理的逻辑”。
程序 = 数据 + 逻辑(算法)
什么是数据?用电商来举例,用户就是数据,商品也是数据。那么什么是数据处理逻辑呢?购买商品的流程就是数据处理逻辑了。
在生活中数据是有类型的,例如人的姓名是字符串类型,人的年龄是正整数类型。在Java中数据也是有类型的。
- 分类

基本数据类型
是Java语言中内置的类型,分别是整数类型、浮点类型、字符类型、布尔类型。这四类基本类型是最简单、最基础的类型。
引用数据类型
是强大的数据类型,它是基于基本数据类型创建的。JavaSE中提供了一个超级类库,类库中包含了近万种引用数据类型,也可以自定义引用数据类型。不过现在我们先要学习的是基本类型!
- 基本数据类型
整数类型
十进制表示方式:正常数字 如 13、25等
二进制表示方式:以0b(0B)开头 如0b1011 、0B1001
八进制表示方式:以0开头 如01、07、0721
十六进制表示方式:以0x(0X)开头 数字以0-9及A-F组成 如0x23A2、0xa、0x10
浮点数类型
如1.0、-3.15、3.168、2.5f等
布尔类型
true、false
字符类型
如'a','A', '0', '家'
字符必须使用’’ 包裹,并且其中只能且仅能包含一个字符。
Java中的基本数据类型都一个关键字与之对应,且具有相应的取值范围。在定义变量时需要先指定数据类型。
| 四类 | 八种 | 字节数 | 数据表示范围 |
| 整型 (精确) | byte | 1 | -128~127 |
| short | 2 | -32768~32767 | |
| int(默认) | 4 | -2147483648~2147483647 | |
| long | 8 | -263~263-1 | |
| 浮点型 (不精确) | float | 4 | -3.403E38~3.403E38 |
| double(默认) | 8 | -1.798E308~1.798E308 | |
| 字符型 | char | 2 | 表示一个字符,如('a','A','0','家') |
| 布尔型 | boolean | 1 | 只有两个值true与false |
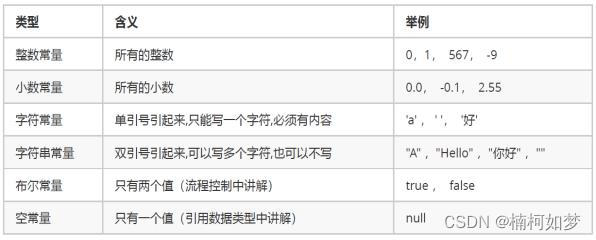
- 常量
常量就是不变的数据量(字面值),例如100就是常量,任何数据量都有其类型,那么100这个常量是什么类型呢?回忆一下基本类型中有四类,分别是整数、小数(浮点数)、字符、布尔。
示例代码
回顾HelloWorld案例,其中System.out.println(“Hello World!”)的圆括号中放的就是一个字符串。那么我们是否可以把圆括号中的字符串换成其他字符串呢?答案是可以的!不只是可以换成其他字符串,还可以把圆括号中的字符串换成其他类型的常量,例如:
- 变量
- 概念
变量:在程序中可以变化的量称为变量(常量是固定不变的量)
数学中,可以使用字母代替数字运算,例如 x=1+5 或者 6=x+5。
程序中,可以使用字母保存数字的方式进行运算,提高计算能力,可以解决更多的问题。比如x保存5,x也可以保存6,这样x保存的数据是可以改变的,也就是我们所讲解的变量。
Java中要求一个变量每次只能保存一个数据,必须要明确保存的数据类型。
- 定义
格式
数据类型 变量名 = 数据值;
例如
int a =100;
其中int是数据类型,指定了变量只能存储整数,而且指定了存储范围为-2147483648~2147483648。
其中a表示变量名,变量名是标识符,这说明只要是合法的标识符都可以用来做变量名。在程序中可以通过变量名来操作变量
其中“=100”是给变量赋值,即向a变量中写入100。
注意,给变量赋的值一定要与类型符合,也就是说int类型只能存储整数,而且必须是在-2147483648~2147483648范围内的整数。
(三)注意事项
1、变量定义后可以不赋值,使用时再赋值。不赋值不能使用。
2、变量不能重复定义,并且赋值时类型得匹配。
3、变量使用时有作用域的限制。
(四)数据类型转换
1、概念
不同类型的变量是否可以在一起运算呢?答案是可以的,但要先进行类型转换再运算。
其实,我们所学习的数据,它的表示方式是可以灵活多变的,比如把小数转换成整数的操作。
2、数据类型转换的两种方式
(1)自动类型转换
表示范围小的数据类型(如byte)可以直接转换成范围大的数据类型(如int),这种方式称为自动类型转换。(小东西装入大盒子中)
格式:范围大的数据类型 变量 = 范围小的数据类型值;
(2)强制类型转换
表示范围大的数据类型(如int)不可以转换成范围小的数据类型(如byte),但可以强制转,这种方式称为强制类型转换。
格式:范围小的数据类型 变量 = (范围小的数据类型) 范围大的数据类型值;
转换规律:
各种数据类型按照数据范围从小到大依次列出:范围小的类型向范围大的类型提升:byte<short=char‐‐>int‐‐>long‐‐>float‐‐>double
byte、short、char 运算时直接提升为int,同样的道理,当一个int 类型变量和一个double 变量运算时, int 类型将会自动提升为double 类型进行运算
Java中整数常量的默认类型是int类型,浮点数的默认类型是double类型。
浮点转成整数,直接去掉小数点,可能造成数据损失精度。
int 强制转成byte砍掉3个字节,可能造成数据丢失(丢失精度)。
3、浮点数运算问题
浮点数做运算结果不精确,要少于甚至不用浮点数直接进行运算。想要进行精确运算,要使用BigDecimal去完成(后面的课程中会学习到)
(五)字符集和char类型
1、字符集概念
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,就需要进行字符编码,以便计算机能够识别和存储各种文字。中文文字数目大,而且还分为简体中文和繁体中文两种不同书写规则的文字,而计算机最初是按英语单字节字符设计的,因此,对中文字符进行编码,是中文信息交流的技术基础。
2、常见字符集介绍
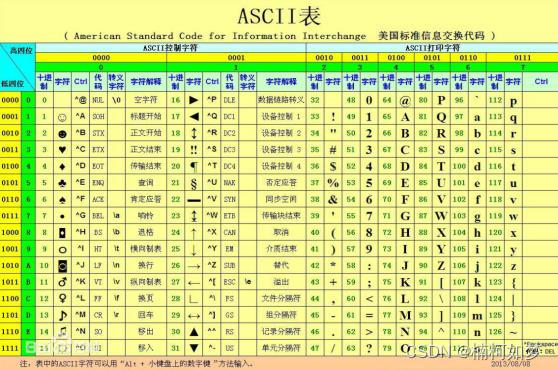
ASCII字符集&编码
ASCII(American Standard Code for Information Interchange, 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语。
ASCII一共定义了128个字符,包括33个控制字符,和95个可显示字符。大部分的控制字符已经被废弃。
ASCII码为单字节,用7位二进制数表示,由于计算机1个字节是8位二进制数,所以最高位为0,即00000000-01111111或0x00-0x7F。
|
|
2 GB2312字符集&编码
GB2312 或 GB2312–80 是中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB 2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。
GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符,基本满足了汉字的计算机处理需要。它所收录的汉字已经覆盖中国大陆99.75%的使用频率,但对于人名、古汉语等方面出现的罕用字和繁体字,GB2312不能处理。
3 GBK字符集&编码
汉字内码扩展规范,称GBK,全名为《汉字内码扩展规范(GBK)》1.0版,由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司和电子工业部科技与质量监督司1995年12月15日联合以《技术标函[1995]229号》文件的形式公布。
GBK的K为汉语拼音Kuo Zhan(扩展)中“扩”字的声母。英文全称Chinese Internal Code Extension Specification。
GB2312只收录6763个汉字,有不少汉字,如部分在GB2312推出以后才简化的汉字(如“啰”),部分人名用字(如中国前总理朱镕的“镕”字),台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。GBK对GB 2312-80进行扩展, 总计拥有23940个码位,共收入21886个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号883 个。
4 Unicode字符集&编码
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
Unicode伴随着通用字符集的标准而发展,同时也以书本的形式对外发表。Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为2016年6月21日公布的9.0.0,已经收入超过十万个字符(第十万个字符在2005年获采纳)。Unicode涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母。
Unicode发展由非营利机构统一码联盟负责,该机构致力于让Unicode方案替换既有的字符编码方案。因为既有的方案往往空间非常有限,亦不适用于多语环境。
Unicode备受认可,并广泛地应用于电脑软件的国际化与本地化过程。有很多新科技,如可扩展置标语言、Java编程语言以及现代的操作系统,都采用Unicode编码。
统一码的编码方式与ISO 10646的通用字符集概念相对应。目前实际应用的统一码版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示2的16次方(即65536)个字符。基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这16位编码,而是保留了大量空间以作为特殊使用或将来扩展。
Unicode原编码占用两个字节,在使用ASCII字符时,高位字节的8位始终为0,这会造成空间的浪费。为了避免这种浪费,Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
5 UTF-8 编码
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。
UTF-8使用一至六个字节为每个字符编码(尽管如此,2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,也就是说最多四个字节):
128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要两个字节编码(Unicode范围由U+0080至U+07FF)。
其他基本多文种平面(BMP)中的字符(这包含了大部分常用字,如大部分的汉字)使用三个字节编码(Unicode范围由U+0800至U+FFFF)。
其他极少使用的Unicode 辅助平面的字符使用四至六字节编码(Unicode范围由U+10000至U+1FFFFF使用四字节,Unicode范围由U+200000至U+3FFFFFF使用五字节,Unicode范围由U+4000000至U+7FFFFFFF使用六字节)。
对上述提及的第四种字符而言,UTF-8使用四至六个字节来编码似乎太耗费资源了。但UTF-8对所有常用的字符都可以用三个字节表示,而且它的另一种选择,UTF-16编码,对前述的第四种字符同样需要四个字节来编码,所以要决定UTF-8或UTF-16哪种编码比较有效率,还要视所使用的字符的分布范围而定。
编码方式
单字节字符的最高有效比特永远为0。
多字节序列中的首个字符组的几个最高有效比特决定了序列的长度。最高有效位为110的是2字节序列,而1110的是三字节序列,如此类推。
多字节序列中其余的字节中的首两个最高有效比特为10。
3、char类型
Java语言采用国际通用编码集utf-8作为默认编码集。
赋值方式
和int类型的运算
说明
在char类型和int类型计算的过程中,char类型的字符先查询编码表,得到97,再和1求和,结果为98。char类型提升为了int类型。char类型内存2个字节,int类型内存4个字节。
几个特殊意义的字符
\ 转义字符
\’ 表示 单引号
\\ 表示 \
\n 换行
\r 回车
\t tab 制表符















 1464
1464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









