






一,深度剖析数据在内存中的存储
最近在看脱口秀,感觉很快乐!看的是脱口秀大会,不过我是看的b站的单人合辑,先看的徐志胜的,再看的呼兰的,看完呼兰打算看鸟鸟。
好了,开始写文章吧,这次换个写作风格打算用讲解,而不是笔记的方式写作了另外属于初学总结笔记难免会有点错误,欢迎指正!请多包涵!
1.前面我们已经介绍了各种数据类型
看看还记得吗?
%c字符 char
%d整形 int short
%s字符串
%f浮点型float
%lf双精度浮点型double
%p地址的打印
%ld=long
%lld=long long
前文也讲了类型他所代表的意义:
-
使用这个类型开辟内存空间的大小
-
指针类型决定了指针一次访问多少个字符
-
我自己的一点思考:那个储存的原反补码都是相同的,以不同类型打印出来却是不一样的,就比如存下了一个反码,以整形和浮点型打印出来就是不一样的。
1.1来给类型分个类吧
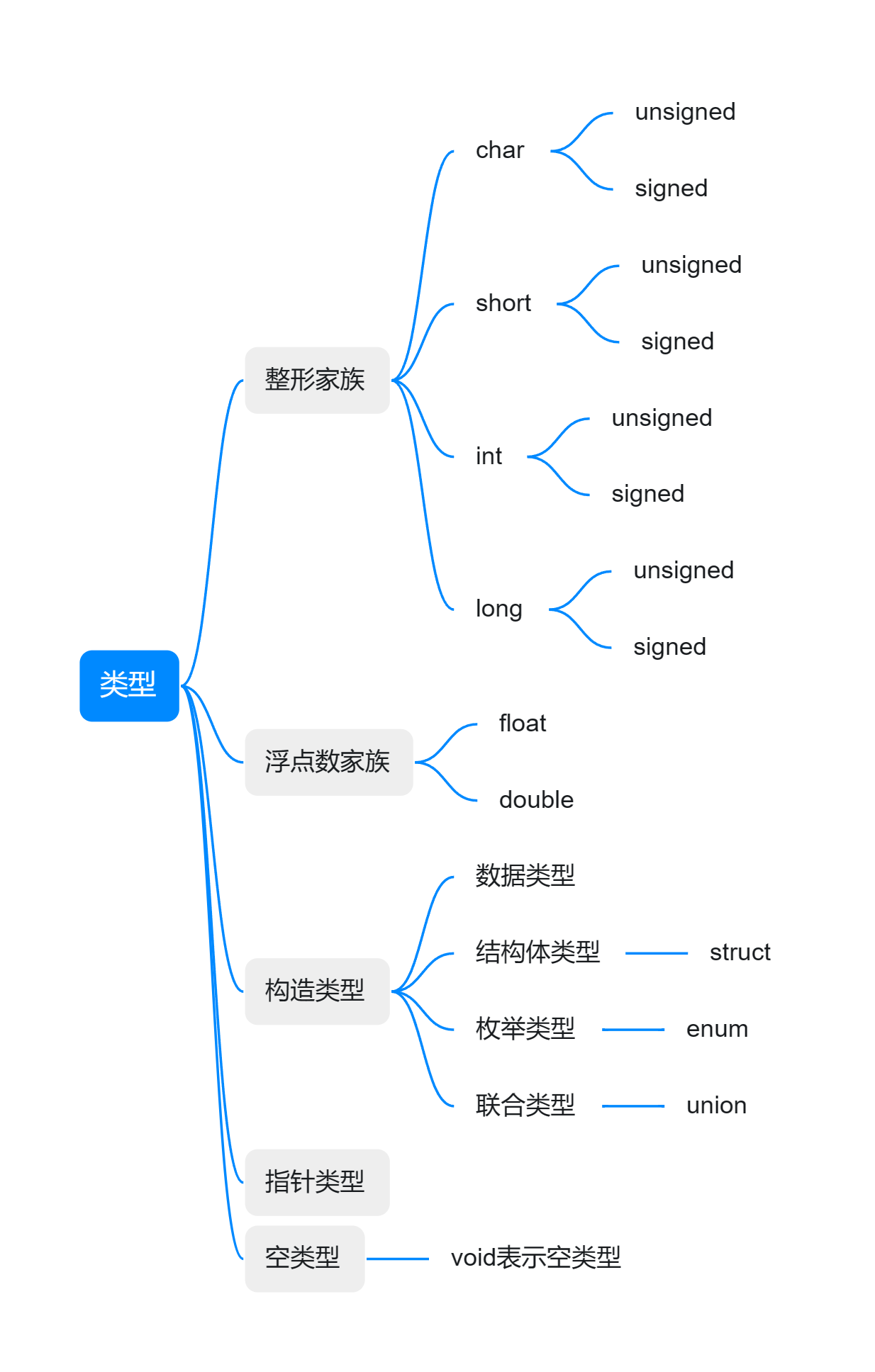
c语言中常见的数据类型在总结一下:
-
基本整数类型:
-
char:用于表示字符,通常占用1个字节。
-
int:用于表示整数,通常占用4个字节。
-
short:短整数类型,通常占用2个字节。
-
long:长整数类型,通常占用4个或8个字节。
-
long long:长长整数类型,通常占用8个字节。
-
-
浮点数类型:
-
float:单精度浮点数,通常占用4个字节。
-
double:双精度浮点数,通常占用8个字节。
-
long double:扩展精度浮点数,占用字节数可以大于8个字节。
-
-
其他基本类型:
-
void:表示无类型,通常用于函数返回类型或指针类型。
-
_Bool:布尔类型,用于表示真或假的值,占用1个字节。
-
-
枚举类型(enum):用于定义一组命名的整数常量。
-
派生类型:
-
数组(Array):用于存储相同类型的多个元素。
-
结构体(Struct):用于封装不同类型的数据成员。
-
联合体(Union):用于在同一内存位置存储不同类型的变量。
-
枚举类型(Enum):用于定义一组命名的整数常量。
-
指针(Pointer):用于存储变量的内存地址。
-
函数(Function):用于封装一组可执行的代码。
-
2.整型在内存中的存储
变量的创建是要在内存中开辟空间的,空间的大小是由类型决定的。
接下来我们详细讲一下数据究竟是怎么存储的?
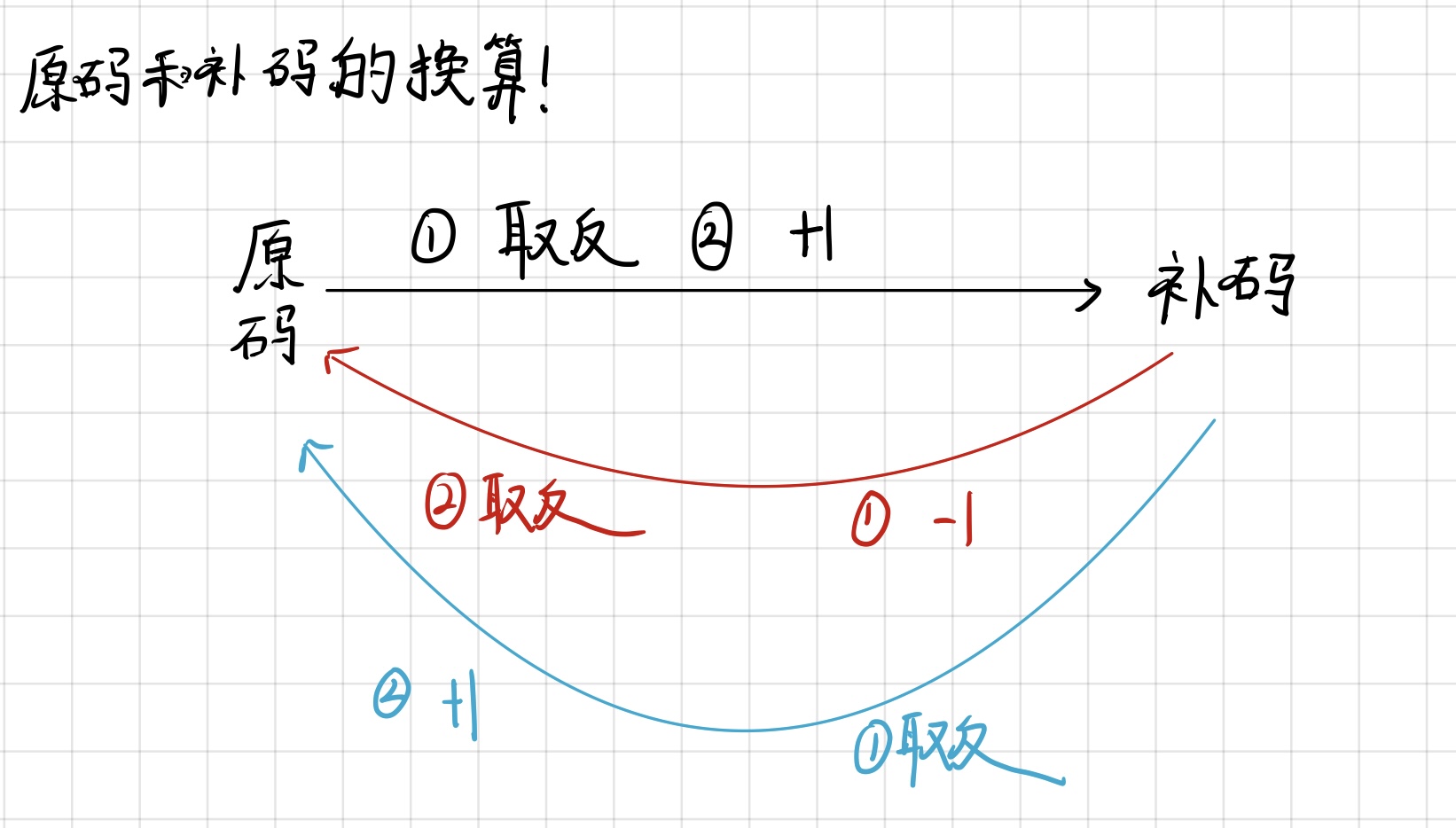
2.1原码,反码,补码
在前文讲指针的时候已经讲过~
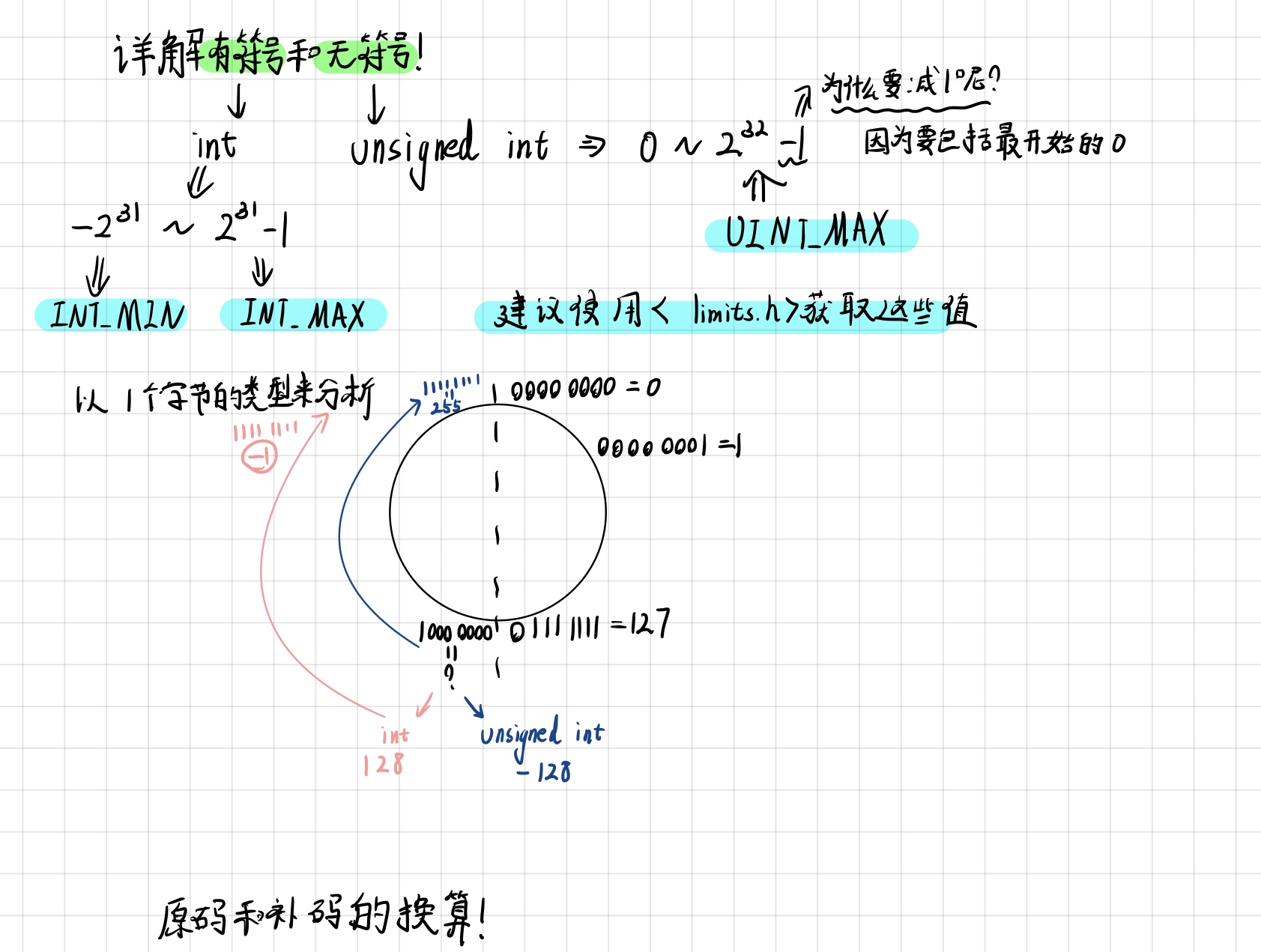
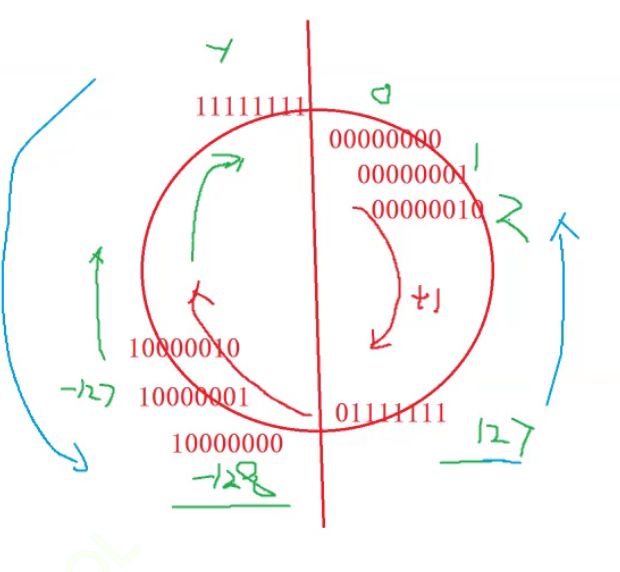
在计算机中,整数通常使用二进制来表示。为了表示正负数,引入了原码、反码和补码的概念。
:::
原码(Sign-Magnitude):
最高位为符号位,0表示正数,1表示负数。
其余位表示数值的绝对值。
例如,+5的原码为 00000101,-5的原码为 10000101。
反码(Ones’ Complement):
正数的反码与原码相同。
负数的反码是将其原码按位取反(0变为1,1变为0)得到的。
例如,+5的反码为 00000101,-5的反码为 11111010。
补码(Two’s Complement):
正数的补码与原码相同。
负数的补码是将其反码加1得到的。
补码表示中,最高位为符号位,0表示正数,1表示负数。
补码表示中,负数比正数多一个数,即负数的范围比正数的范围多一个。
例如,+5的补码为 00000101,-5的补码为 11111011。
补码的引入主要是为了解决计算机中加法和减法的统一性(cpu只有加法器)。使用补码表示负数时,可以直接使用加法运算进行负数和正数的相加,而无需单独的减法运算。
补码表示中,负数的最高位是1,正数的最高位是0,这样可以通过判断最高位来确定一个数是正数还是负数。同时,负数的补码可以通过取反加1得到原码,正数的补码就是其原码本身。
需要注意的是,在C语言中,整数类型的表示和运算都是以补码的形式进行的。这是因为大多数计算机体系结构都使用补码表示整数,因此C语言中也采用了补码作为默认的整数表示方法。
:::
来我们看一下在内存中存放的地址!
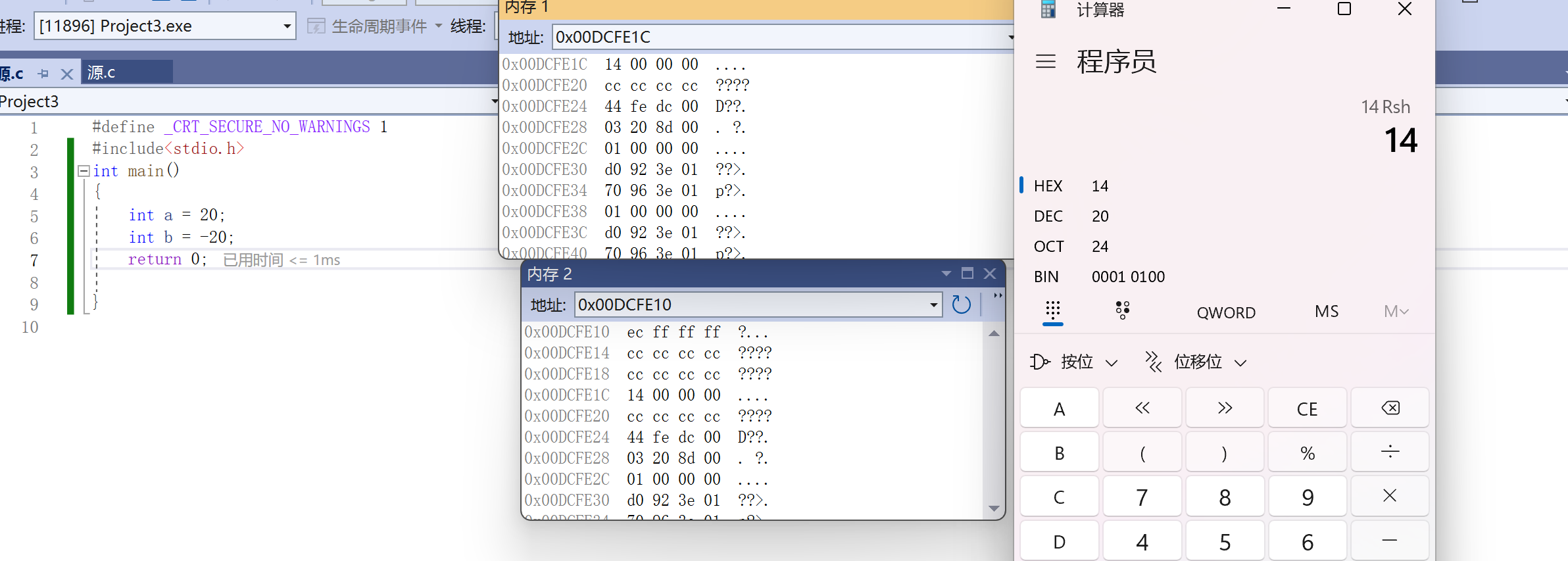
我们可以看到存储的都是补码!,然后你会发现顺序似乎有点奇怪?那个14不应该存储的后面吗?
这就引出我们的小端存储
2.2大小端介绍
大小端(Endianness)是指在计算机内存中多字节数据(如整数、浮点数)的存储方式。
它涉及到字节的存储顺序和字节的访问顺序。
-
大端字节序(Big-Endian):
-
在大端字节序中,较高的有效字节(最高位字节)存储在较低的内存地址,而较低的有效字节(最低位字节)存储在较高的内存地址。
-
以16位整数0x1234为例,它在内存中的存储方式为:地址递增方向 0x12 0x34。
-
-
小端字节序(Little-Endian):
-
在小端字节序中,较低的有效字节(最低位字节)存储在较低的内存地址,而较高的有效字节(最高位字节)存储在较高的内存地址。
-
以16位整数0x1234为例,它在内存中的存储方式为:地址递增方向 0x34 0x12。
-
为什么会产生大小端的存储模式?这涉及到计算机体系结构和数据存储的历史发展。
计算机在处理多字节数据时,需要将数据拆分成字节并存储在内存中。在早期计算机设计中,并没有明确的字节顺序规范。因此,不同的计算机体系结构采用了不同的字节顺序。
历史上,IBM的大型机(如IBM System/360)采用了大端字节序,这主要是因为早期打孔卡片机和打字机的字节顺序是从左到右。后来,Intel的x86体系结构(包括当前的PC和服务器)采用了小端字节序,这主要是因为在处理器内部,低字节位于低地址,与处理器的设计有关。
因此,大小端的存储模式是由不同的计算机体系结构和历史发展决定的。在实际应用中,需要注意不同计算机体系结构之间的字节顺序差异,特别是在进行数据交换、网络通信或跨平台开发时,需要进行字节序转换来保证数据的正确传输和解析。
进一步:
产生大小端存储模式的原因与计算机体系结构、数据存储和数据传输的需求有关。
下面将详细解释为什么会产生大小端存储模式,以及为什么会有大小端的存在。
-
计算机体系结构:
-
计算机内部使用的数据存储单元是字节(Byte),而数据类型可以是多字节的,如整数、浮点数等。
-
不同计算机体系结构在硬件层面上设计了不同的数据存储方式和处理方式,包括字节的排列顺序。
-
计算机体系结构决定了字节的存储顺序和处理方式,从而导致了不同的字节序模式。
-
-
内存访问方式:
-
在计算机内存中,数据存储是以字节为单位的,每个字节都有唯一的地址。
-
访问多字节数据时,根据字节的排列顺序,处理器可以按照不同的方式组合和解析字节。
-
大端和小端模式影响了处理器如何读取和解释多字节数据的字节顺序。
-
-
数据传输和网络通信:
-
在数据传输和网络通信中,不同计算机或设备之间需要进行数据交换,例如通过网络传输数据。
-
数据交换需要统一的数据表示方式,以确保发送方和接收方能正确地解释数据。
-
大小端存储模式的存在使得在数据传输和通信中需要考虑字节序的转换和协商。
-
总结起来,产生大小端存储模式的原因主要是因为计算机体系结构和数据存储的设计差异,以及数据传输和通信的需求。不同的计算机体系结构和设备采用不同的字节顺序,这在处理器的设计和数据存储中产生了差异。大小端的存在要求在跨平台数据传输和通信中,进行字节序的转换和协商,以保证数据的正确解释和传输。
2.3一点点练习
2.3.1判断大小端
在函数中,定义了一个联合体(union),其中包含一个整型变量i和一个字符型变量c。联合体的特点是它的所有成员共享相同的内存空间,即它们在内存中的起始地址是相同的。
函数的逻辑如下:
-
将整型变量i初始化为1,这是为了检测内存中最低有效字节的值。
-
通过返回字符型变量c的值,将联合体的最低有效字节作为函数的返回值。
函数的返回值将提供以下信息:
-
如果返回值为1,表示最低有效字节为1,即小端字节序(低位字节存储在低地址)。
-
如果返回值为0,表示最低有效字节为0,即大端字节序(高位字节存储在低地址)。
通过调用该函数并观察返回值,可以判断当前系统的字节序是大端还是小端。这对于处理跨平台数据交换和网络通信非常有用,因为不同的系统可能采用不同的字节序,需要进行适当的字节序转换以确保数据的正确传输和解释。
#include<stdio.h>
//设计一个小程序判断当前的机器是以怎么样的方式存储的?
int check_sys1()
{
int i = 1;
return (*(char*)&i);//强制类型转化,并解引用,出第一个字符,如果是小端存储那么读取的就是1
}
int check_sys2()
{
union {
int i;
char c;
}un;
un.i = 1;
return (un.c);
}
int main()
{
int ret = check_sys1();
if (ret == 1)
{
printf("小\n");
}
if (ret == 0)
{
printf("big\n");
}
ret = check_sys2();
if (ret == 1)
{
printf("小\n");
}
if (ret == 0)
{
printf("big\n");
}
return 0;
}
2.3.2输出什么?
#include<stdio.h>
int main()
{
char a = -1;
//10000001
//11111110
//11111111以这个方式储存起来;
//这个读取的时候是以有符号的char来读取的;
//但是打印的时候按照十进制的形式打印有符号整型整数;
//所以这里整型提升;
//11111111111111111111111111111111 32位;
//11111111111111111111111111111110 反码;
//10000000000000000000000000000001 原码打印出来为-1;
signed char b = -1;
unsigned char c = -1;
//10000001
//11111110
//11111111以这个方式储存起来;
//这个读取的时候是以有符号的unsigned char来读取的;
//但是打印的时候按照十进制的形式打印有符号整型整数;
//所以这里整型提升;
//11111111111111111111111111111111 32位原码;
//打印出来为2^32-1
printf("a=%d,b=%d,c=%d", a, b, c);输出-1 -1 255
return 0;
}
2.3.3输出什么2
#include<stdio.h>
int main()
{
char a = -128;
//1000 0000 0000 0000 0000 0000 1000 0000原
//1111 1111 1111 1111 1111 1111 0111 1111反
//1111 1111 1111 1111 1111 1111 1000 0000补
//10000000
//以unsigned int 的形式打印要发生隐式类型转换
//11111111111111111111111110000000
//4,294,967,168
printf("%u\n", a);
return 0;
}
#include<stdio.h>
int main()
{
char a = 128;
//0000 0000 0000 0000 0000 0000 1000 0000原
//0000 0000 0000 0000 0000 0000 1000 0000反
//0000 0000 0000 0000 0000 0000 1000 0000补
//10000000
//以unsigned int 的形式打印要发生隐式类型转换
//11111111111111111111111110000000
//4,294,967,168
printf("%u\n", a);
return 0;
}
#include<stdio.h>
int main()
{
int a = -20;
//0000 0000 0000 0000 0000 0000 0001 0100原
//1111 1111 1111 1111 1111 1111 1110 1011反
//1111 1111 1111 1111 1111 1111 1110 1100补
unsigned int b = 10;
//0000 0000 0000 0000 0000 0000 0000 1010
// 加起来
//1111 1111 1111 1111 1111 1111 1111 0110补
//1111 1111 1111 1111 1111 1111 1111 0101反
//1000 0000 0000 0000 0000 0000 0000 1010//为-10
printf("%d\n", a+b);
return 0;
}
练习4
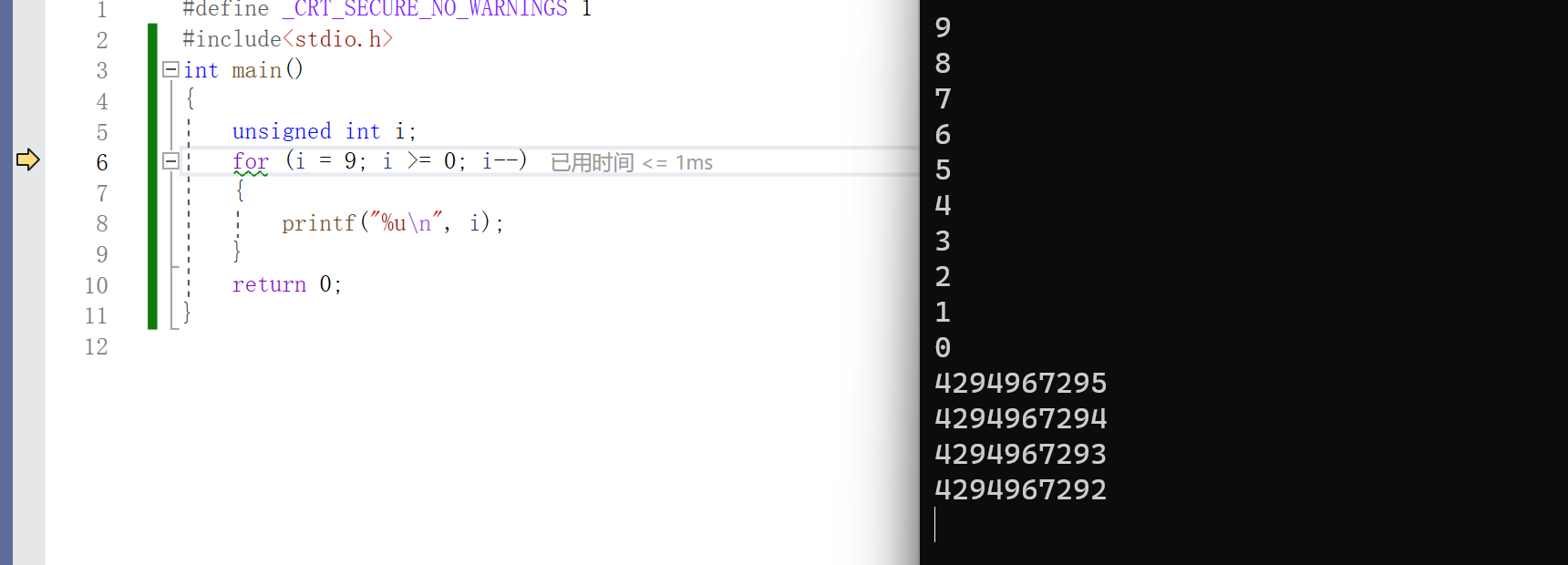
为什么会出现这个现象呢,是因为i为无符号整整型,到-1的时候就变成了4294967295
#include<stdio.h>
int main()
{
char a[1000];
//char-128~127
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));//遇到\0的时候结束,在char里\0==0
return 0;
}
#include<stdio.h>
unsigned char i = 0;
//255:
//0000 0000 0000 0000 0000 0000 1111 1111
//1111 1111放在char里
//当在增加1的时候就变成
//0000 0000 0000 0000 0000 0001 0000 0000
//0000 0000放在char里
int main()
{
for (i = 250; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
当增加到255的时候,再增加会造成!非常严重的后果:就是变成0重新开始增加(>)
3.浮点型在内存中存储
浮点型似乎从来没考虑过呢?
先看看这串代码,思考一下这个结果!
#include <stdio.h>
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);//9
printf("*pFloat的值为:%f\n", *pFloat);//0.000000
*pFloat = 9.0;
printf("num的值为:%d\n", n);//1091567616
printf("*pFloat的值为:%f\n", *pFloat);//9.0
return 0;
}
emm。。。第一个和最后一个还好理解,中间的是什么啊!。
所以现在我们来介绍一下浮点型的存储
1.先让我们的柴兄弟发言:
浮点数在内存中的存储方式通常采用IEEE 754标准,这是一种用于表示浮点数的二进制格式。根据IEEE 754标准,浮点数由三个部分组成:符号位(sign bit)、指数位(exponent bits)和尾数位(fraction bits)。
对于单精度浮点数(float),它占用32位(4个字节)内存空间,按照以下格式存储:
//[符号位][指数位][尾数位]
-
符号位(1位):用于表示浮点数的正负号,0表示正数,1表示负数。
-
指数位(8位):用于表示浮点数的指数部分。采用移码(excess-k)表示法,其中k = 127(对于单精度浮点数),将实际的指数值加上127后存储为无符号整数。
-
尾数位(23位):用于表示浮点数的小数部分,也称为尾数(fraction)。采用二进制科学计数法的形式存储,其中最高位默认为1(隐藏位),后面的23位存储尾数的二进制表示。
对于双精度浮点数(double),它占用64位(8个字节)内存空间,按照以下格式存储:
cssCopy code[符号位][指数位][尾数位]
-
符号位(1位):同样用于表示浮点数的正负号。
-
指数位(11位):采用移码表示法,k = 1023(对于双精度浮点数)。
-
尾数位(52位):同样采用二进制科学计数法表示。
通过这种存储方式,浮点数可以表示很大或很小的数值,并具有一定的精度。
然而,由于浮点数的存储方式是有限的,因此在进行浮点数计算时可能会出现舍入误差和精度损失的问题。
在对浮点数进行计算和比较时,需要注意这些问题可能会对结果产生影响。
2.咳咳,柴兄弟讲的不错,现在我来细说一下~公式
按照国际标准IEEE 754,任意一个二进制浮点数V都可以表示为下面的形式:
:::
(-1)^S * M * 2^E
:::
1.(-1)^S表示符号位,当s=0为正数,s=1为负数
2. M表示有效数字,大于等于1,小于2
3. 2^E表示指数位
举个例子吧:
1.10进制的5.0就是相当于(-1)^0 * 1.01 * 2^2
2.然后呢?按照柴兄弟的说法,放到浮点型里是什么样的呢?
0(s)
00000010(E?)错了!,应该是加127!所以是0111 1111(E)
01000000000000000000000(M)
3.SEM加起来为00000001001000000000000000000000
再举个例子
#include<stdio.h>
int main()
{
float f = 5.0;
//101.1
//1.011 * 2^2
//(-1)^0 *1.011 * 2^2
//S = 0
//M = 1.011
//E = 2
//0 10000001 01100000000000000000000
//0x 40b00000
return 0;
}
通过上述两个例子,发现其实浮点型的存储也是在小端哈!
3.柴兄弟来更经典的例子
单精度浮点数(float)
-
表示整数:10.0
符号位:0
指数位:10000010 (对应的十进制为 130,减去偏置 127 得到实际指数值 3)
尾数位:00000000000000000000000 (对应的十进制为 0,隐藏位默认为1)
合并后的二进制表示:0 10000010 00000000000000000000000
对应的十六进制表示:0x41 0000 00 -
表示小数:3.14
符号位:0
指数位:10000000 (对应的十进制为 128,减去偏置 127 得到实际指数值 1)
尾数位:10010010000111111011011 (对应的十进制为 10785307,隐藏位默认为1)
合并后的二进制表示:0 10000000 10010010000111111011011
对应的十六进制表示:0x40 9147 fb
双精度浮点数(double)
-
表示整数:1000000.0
符号位:0
指数位:10000000011 (对应的十进制为 1027,减去偏置 1023 得到实际指数值 4)
尾数位:0000000000000000000000000000000000000000000000000000 (对应的十进制为 0,隐藏位默认为1)合并后的二进制表示:0 10000000011 0000000000000000000000000000000000000000000000000000
对应的十六进制表示:0x41 8000 0000 0000
-
表示小数:3.14159
符号位:0
指数位:10000000000 (对应的十进制为 1024,减去偏置 1023 得到实际指数值 1)
尾数位:1001000001111101101010100010001000011101110101110010 (对应的十进制为 4160749569,隐藏位默认为1)合并后的二进制表示:0 10000000000 1001000001111101101010100010001000011101110101110010
对应的十六进制表示:0x40 9249 0f 3d 70 a3
4.这样我就对一开始的那个例子更懂了,嘿嘿
#include <stdio.h>
int main()
{
int n = 9;
//00000000000000000000000000001001
float* pFloat = (float*)&n;
//0 00000000 00000000000000000001001
//S E M
//0 -126 0.00000000000000000001001
//(-1)^0 * 0.00000000000000000001001 * 2^(-126)
//E在内存中是全0(所以就很小了)
printf("n的值为:%d\n", n);//9
printf("*pFloat的值为:%f\n", *pFloat);//0.000000
*pFloat = 9.0;
//1001.0
//1.001 * 2^3
//(-1)^0 * 1.001 * 2^3
//S=0 E=3 M=1.001
//0 10000010 00100000000000000000000(注意m要省去那个那个那个哦!)
printf("num的值为:%d\n", n);//1091567616
//01000001000100000000000000000000经过二进制转化就成这个1091567616了
printf("*pFloat的值为:%f\n", *pFloat);//9.0
return 0;
}
然后然后然后~似乎没有然后了,
就到这里,兄弟姐妹们下次见!
我:希望期末考试不挂科
柴兄弟:怎么可能不挂?你连部分的课的课本都没有。
我:算了,等考前三天找吧。
柴兄弟:好了,估摸着三天时间两天半都得用来找书。
我:emmm…
see you~~~~~~~~~~~~~~~~~~~next time
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









