







协同过滤推荐
1. 什么是协同过滤
协同过滤(collaborative filtering)是通过将用户和其他用户的数据进行对比来实现推荐的算法。
2. 协同过滤流程图
3. 协同过滤分类
(1)基于用户的协同过滤推荐(User-based Collaborative Filtering Recommendation)
基于用户的协同过滤推荐算法先使用统计技术寻找与目标用户有相同喜好的邻居,然后根据目标用户的邻居的喜好产生向目标用户的推荐。基本原理就是利用用户访问行为的相似性来互相推荐用户可能感兴趣的资源,
(2)基于项目的协同过滤推荐(Item-based Collaborative Filtering Recommendation)
根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户,
(3)基于模型的协同过滤推荐(Model-based Collaborative Filtering Recommendation)
基模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测推荐。
UserCF
推荐和当前用户相似度高的N个用户产生过行为的物品给当前用户;
这些物品是当前用户没有行为过而其他N个用户行为过的物品的前M个;
余弦相似度改进:在分子中除了考虑两个用户共同行为的物品,还考虑到这个物品被多少个用户行为过。
加入时间因子:
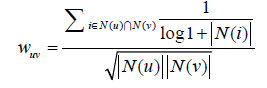
相似度计算:用户u和用户v对物品i产生行为的时间越远,那么这两个用户的兴趣相似度就会越小。
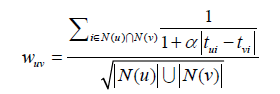
预测阶段:和当前用户相似的其他用户最近行为过得物品更容易得到推荐。
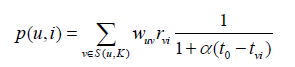
ItemCF
推荐和当前用户历史上行为过的物品相似的物品给当前用户;
对于当前用户历史航行为过的每一个物品,推荐和每一个物品相似度高的前N个物品给当前用户;
余弦相似度改进:在分子中除了考虑这两个物品是否同时被用户行为过,还考虑该用户一共行为过的物品的数量。
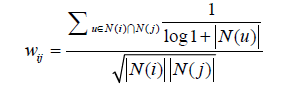
物品相似度的归一化:将相似度矩阵按照最大值归一化,可以提高推荐的准确率,还可以提高推荐的覆盖率和多样性。
加入时间因子:
- 相似度计算:在原先余弦相似度基础上,同一个用户对两个物品行为的时间距离越近,相似度越大。
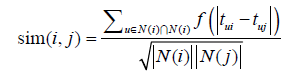
- 预测阶段:和当前时间距离近的用户作用过的物品相似的物品更容易得到推荐。
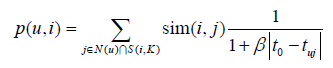
4. 相似度
相似度计算就是看两个物品(或用户)有多相似,拿电影来说,可能会比较类型、导演、地区等等,但是在协同过滤里,不关心这些属性,严格地按照许多用户的观点来计算相似度。比如下面的电影和用户评分矩阵:
相似度计算
欧氏距离(euclidean metric)
欧氏距离指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离,就是那个“根号下横坐标差的平方加纵坐标差的平方”。
numpy的线性代数(Linear algebra)库linalg里有一个norm函数,用于求范数(normal form),如果不指定范数的阶数,就默认指2范数,就是向量各个元素平方和开根号,比如向量A=(4,2,2),向量A的2范数||A||=根号下(4^2+2^2+2^2)(简书不支持LaTeX真是不方便……),所以np.linalg.norm(colA - colB))就是向量A和B的欧式距离了。1.0/(1.0 + 欧式距离)的作用是使相似度的值在0到1之间变化,越相似,相似度的值越大,距离为0时,相似度为1。
皮尔逊相关系数
皮尔逊相关系数可以用来度量两个向量之间的相似度,比欧氏距离好的一点是它对用户评级不敏感,比如某个狂躁者对所有电影评分都是5,一个忧郁者对所有电影评分都是1,皮尔逊相关系数会认为这两个向量相等。看最后一个公式,对比两个向量的余弦公式,长得挺像,据说皮尔逊系数是两组向量的余弦。
- Python代码实现
def pearson_sim(colA, colB):
if len(colA) < 3:
return 1.0
return 0.5 + 0.5 * np.corrcoef(colA, colB, rowvar=0)[0][1]代码解析len(colA) < 3是检查是否有3个或更多的点,如果不存在,则返回1,两向量完全相关。corrcoef(colA, colB, rowvar=0)返回的是变量的相关系数矩阵,第[0][1]个元素是相关系数,rowvar=0代表列是variables。API在这里。0.5 + 0.5 *皮尔逊相关系数目的也是将取值范围归一化到0~1之间,皮尔逊相关系数的取值范围是-1~1,所以用0.5+0.5*系数的方式归一化。
余弦相似度
余弦相似度就是计算两个向量夹角的余弦值,如果夹角为90度,则相似度为0;如果方向相同,相似度为1。因为余弦值的范围也是-1~1,所以需要用同样的方法进行归一化。前面说过,||A||代表向量的2范数。
def cos_sim(colA, colB):
num = float(colA.T * colB)
denom = np.linalg.norm(colA) * np.linalg.norm(colB)
return 0.5 + 0.5 * (num / denom)调整的余弦相似度
调整的余弦相似度计算,由于基于余弦的相似度计算没有考虑不同用户的打分情况,可能有的用户偏向于给高分,而有的用户偏向于给低分,该方法通过减去用户打分的平均值消除不同用户打分习惯的影响,公式如下:
其中表示用户u对物品i的打分,
表示用户u打分的平均值。该公式主要用于基于物品的协同过滤推荐系统。
基于Tanimoto系数计算相似度:

相似度选择
计算两个电影之间的距离,是基于物品(item-based)的相似度,计算用户的距离,是基于用户(user-based)的相似度。到底使用哪种相似度,取决于用户和物品的数量。
基于物品的相似度会随着物品增加而增加,基于用户的相似度会随着用户的增加而增加。如果用户很多,则倾向于物品相似度计算方法。对于大部分推荐引擎而言,用户数目往往大于物品数目,所以一般用物品相似度。
选用基于物品(item-based)、基于用户(user-based)哪种协同过滤,一般会倾向于选择数据量少的一方,计算距离,作为相似度量度。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









