







背景
现在就出现了另外一个场景,就是我们的目标是多个步骤的。可能在中间的某个步骤,很难获得最好的收益。举个例子,小孩子在学习和玩耍的过程看成一个强化的过程。比如,下一步如果选择玩耍,下一步可以得到1分,但是最终是-100分。对于学习步骤,下一步可能是-1分,但是最终是100分。但是我们的机器在选择适合,可能会选择玩耍,因为最终的reward是多步的,比较难以学习。在这种情况下,就需要用到sparse reward的场景。
- 通常情况下,Agent 每一步操作有一个 reward 对应,但是,当 reward 的分布非常稀疏时,可能三四步甚至更多步之后才能产生reward。这样的话,对于机器而言学习如何行动会十分困难。
- 这个一开始的暂时的小的reward 就叫 Sparse Reward
- 比如说要让一个机器人倒水进水杯里,如果不对机器人做任何指导,可能它做很多次尝试,reward都一直是零。(不知道杯子在哪,不知道拿着手上的水壶干嘛,不知道水壶靠近杯子之后应该怎么做)
一、Reward shaping:Curiosity(好奇法)
- 如果 reward 分布非常稀疏的时候,actor 会很难学习,所以刻意设计 reward 引导模型学习。
- 把关键的一些动作强制地定义为正的reward,这样agent就不会反感这一学习行为,从而一步步走到最大的reward。

- 给强化学习模型添加 Reward shaping 的方法:好奇法 Curiosity。
- 在原来的强化学习模型当中,actor与环境做互动,根据环境给的state,采取一定的action,并得到reward。而新的模型引入了一个新的函数:ICM。


基于上边的例子,有一个ICM(intrinsic curiosity module)可以实现类似的逻辑。就是我们去人工设置一个reward的生成器,来帮助机器进行选择。
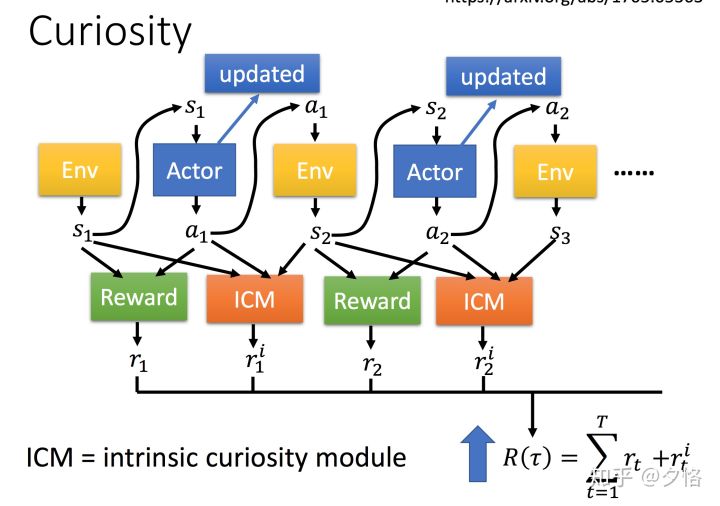
但是这样的方法会带来一个问题,就是ICM过于倾向于新的方法。这样会带来的一个问题就是机器总是会选择没出现过的场景。举个例子,在玩游戏的时候,很多的游戏背景是随机出现的,这样机器会一直待在原地不动,这个是因为背景一直变换,所以电脑倾向于选择这种的场景。

那怎么去优化这个问题呢?我们可以去学习另外一个网络,只保留有用的动作.。

二、Curriculum Learning(课程式学习):Reverse Curriculum Generation
应该逐步的进行学习,即学习的时候,应该从比较简单的方法开始学习起来,逐步到比较困难的地方。
- “制定学习计划” Curriculum Learning,人来设定agent的学习顺序,让Agent以从易到难的顺序学习。
- 比如机器人倒水的例子,最开始可以人引导机器人手臂到杯子的附近,教它做倒水的动作,之后再慢慢改变水杯,水壶等变量,让机器从简单学到复杂。
例子:


三、Hierarchical Reinforcement Learning(阶层式强化学习)
- 有好几个 agent,一些 agent 负责比较 high level 的东西,它负责订目标,然后它订完目标以后再分配给其他的 agent 去执行完成。
- 如果低一层的agent没法达到目标,那么高一层的agent会受到惩罚
- 每一层的agent都是将上一层的愿景当做输入,然后决定自己要产生什么输出
- 如果一个agent实现了一个错误的目标,那就将最初的目标改为这个错误的目标(保证已经实现的成果不被浪费)















 1534
1534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









