






统计手机上网的上行流量和下行流量
数据格式:
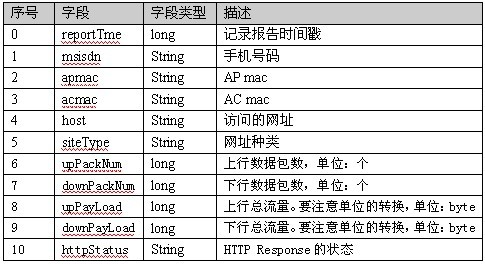
统计手机的 上网流量只需要“手机号”、“上行流量”、“下行流量”三个字段,根据这三个字段创建bean对象, 该对象要实现Writable接口,以便实现序列化, 并且要有无参构造方法,hadoop会使用反射创建对象
MapReduce程序
把需要的数据上传到hdfs,程序打包后运行
通过partition对手机号进行划分,使用Map来模拟从数据库中查询出来的partition的规则
总结:分区Partitioner主要作用在于以下两点
(1)根据业务需要,产生多个输出文件;
(2)多个reduce任务并发运行,提高整体job的运行效率
设置reduce的任务数,通过参数传入程序
partition分了0、1、2、3个区总共四个分区, 但如果reduce的数量小于partition的会报一个IO的异常,因为每个reduce对应一个输出文件
如果设置的reduce的数量大于partition数量,写出的reduce文件将为空文件
partiton的注意事项:
1、partition规则要清晰
2、reduce的数量要等于或大于partition数量
转自: http://mvplee.iteye.com/blog/2245011
数据格式:
统计手机的 上网流量只需要“手机号”、“上行流量”、“下行流量”三个字段,根据这三个字段创建bean对象, 该对象要实现Writable接口,以便实现序列化, 并且要有无参构造方法,hadoop会使用反射创建对象
public class PhoneBean implements Writable {
private String phone;
private Long upPayLoad;
private Long downPayLoad;
private Long totalPayLoad;
public PhoneBean() {
}
public PhoneBean(String phone, Long upPayLoad, Long downPayLoad) {
super();
this.phone = phone;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
this.totalPayLoad = upPayLoad + downPayLoad;
}
@Override
public String toString() {
return this.upPayLoad + "\t" + this.downPayLoad + "\t" + this.totalPayLoad;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phone);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
@Override
public void readFields(DataInput in) throws IOException {
this.phone = in.readUTF();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
}
setter/getter略
}
MapReduce程序
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PhoneCount {
public static class PCMapper extends Mapper<LongWritable, Text, Text, PhoneBean> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, PhoneBean>.Context context) throws IOException, InterruptedException {
String val = value.toString();
String[] vals = val.split("\t");
String phone = vals[1];
Long upPayLoad = Long.parseLong(vals[8]);
Long downPayLoad = Long.parseLong(vals[9]);
PhoneBean bean = new PhoneBean(phone, upPayLoad, downPayLoad); // 输出map结果
context.write(new Text(phone), bean);
}
}
public static class PCReducer extends Reducer<Text, PhoneBean, Text, PhoneBean> {
@Override
protected void reduce(Text key, Iterable<PhoneBean> iterable, Reducer<Text, PhoneBean, Text, PhoneBean>.Context context) throws IOException, InterruptedException {
Long upTotal = 0L;
Long downTotal = 0L;
for (PhoneBean pb : iterable) {
upTotal += pb.getUpPayLoad();
downTotal += pb.getDownPayLoad();
}
// reduce输出结果
context.write(key, new PhoneBean("", upTotal, downTotal));
}
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 设置jar对应的class文件
job.setJarByClass(PhoneCount.class);
// 设置map class文件
job.setMapperClass(PCMapper.class);
// 设置reduce class文件
job.setReducerClass(PCReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PhoneBean.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PhoneBean.class);
// 设置输入文件位置
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 设置输出文件位置
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
把需要的数据上传到hdfs,程序打包后运行
hadoop jar phone2.jar /phone/phone.dat /phone/output
通过partition对手机号进行划分,使用Map来模拟从数据库中查询出来的partition的规则
public static class PCPartitioner extends Partitioner<Text, PhoneBean> {
private static Map<String, Integer> dataMap = new HashMap<String, Integer>();
static {
// 第一分区
dataMap.put("135", 1);
dataMap.put("136", 1);
dataMap.put("137", 1);
// 第二分区
dataMap.put("138", 2);
dataMap.put("139", 2);
// 第三分区
dataMap.put("150", 3);
}
@Override
public int getPartition(Text key, PhoneBean value, int numPartitions) {
String phone = key.toString();
String code = phone.substring(0, 3);
Integer partition = dataMap.get(code);
return partition == null ? 0 : partition;
}
}
总结:分区Partitioner主要作用在于以下两点
(1)根据业务需要,产生多个输出文件;
(2)多个reduce任务并发运行,提高整体job的运行效率
设置reduce的任务数,通过参数传入程序
// 指定Partitioner文件
job.setPartitionerClass(PCPartitioner.class);
// 设置Reduce任务数量
job.setNumReduceTasks(Integer.parseInt(args[2]));
partition分了0、1、2、3个区总共四个分区, 但如果reduce的数量小于partition的会报一个IO的异常,因为每个reduce对应一个输出文件
#设置reduce的数量为3 hadoop jar phone3.jar /phone/phone.dat /phone/output1 3 #程序执行时的异常 15/09/21 16:51:34 INFO mapreduce.Job: Task Id : attempt_1442818713228_0003_m_000000_0, Status : FAILED Error: java.io.IOException: Illegal partition for 15013685858 (3)
如果设置的reduce的数量大于partition数量,写出的reduce文件将为空文件
#设置reduce数量为5 hadoop jar phone3.jar /phone/phone.dat /phone/output2 5 [root@centos1 sbin]# hadoop fs -ls /phone/output2 Found 6 items -rw-r--r-- 1 root supergroup 0 2015-09-21 16:53 /phone/output2/_SUCCESS -rw-r--r-- 1 root supergroup 156 2015-09-21 16:53 /phone/output2/part-r-00000 -rw-r--r-- 1 root supergroup 241 2015-09-21 16:53 /phone/output2/part-r-00001 -rw-r--r-- 1 root supergroup 127 2015-09-21 16:53 /phone/output2/part-r-00002 -rw-r--r-- 1 root supergroup 27 2015-09-21 16:53 /phone/output2/part-r-00003 -rw-r--r-- 1 root supergroup 0 2015-09-21 16:53 /phone/output2/part-r-00004
partiton的注意事项:
1、partition规则要清晰
2、reduce的数量要等于或大于partition数量
转自: http://mvplee.iteye.com/blog/2245011

















 1995
1995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









