






在文生图模型技术日益成熟之际,仍有众多设计爱好者在Midjourney的咒语中苦练,却难以召唤出令人满意的图像。
设计界的专业术语、不甚准确的英文翻译,以及对中国古代建筑的一知半解,充斥着当前的文生图工具,这在很大程度上是由于国内众多团队依赖于翻译后的英文开源Stable Diffusion模型,或是仅基于有限的中文数据在特定场景进行微调(finetune)。这两种方法都面临着对中文理解的不足和缺乏通用性的问题。
为了解决这些难题,腾讯携其创新的中文原生文生图大模型隆重登场。
5月14日,腾讯宣布开源其混元文生图大模型,这标志着国内首个采用DiT(Dual-Path Transformers)架构的中文原生模型问世。该模型不仅具备中英文双语的深度理解与生成能力,更在古诗词、俚语、传统建筑、中华美食等富含中国特色的元素生成上展现出卓越的性能。
比如同样是含有“昆曲”、“狗不理包子”关键词的Prompt,对比不同对文生图模型,混元生成了最匹配对图片:

为了进一步降低了用户的使用门槛,解决几个Prompt搞不定一张图的难题,对比此前大多数文生图模型77个字符的输入,混元支持最多256个字符的输入,简直是文生图界的“Kimi”了。
"文生图也需DiT架构?"
混元文生图大模型的独特之处,根植于其底层技术架构的创新。在架构设计上,该模型采纳了DiT(Dual-Path Transformers)架构,不仅支持中英文双语输入及理解,更拥有高达15亿的参数量。
DiT架构,由Sora引领潮流,巧妙地融合了扩散模型与Transformer架构的长处,赋予了模型强大的视觉生成能力。这种架构的灵活性不仅限于文生图领域,更可扩展至视频制作和其他多模态视觉内容的生成,奠定了其作为未来视觉内容生成的基石。
据消息透露,腾讯混元团队坚信,基于Transformer架构的扩散模型(如DiT)拥有更广阔的可扩展性,有潜力成为下一代视觉生成技术的主流架构,甚至可能统一文生图、视频生成、3D内容生成等多模态视觉生成领域。
“Transformer架构展现出了惊人的扩展潜力,我们至今仍未触及其极限,这也是我们坚定选择Transformer架构的原因。”腾讯文生图项目的负责人芦清林如是说。
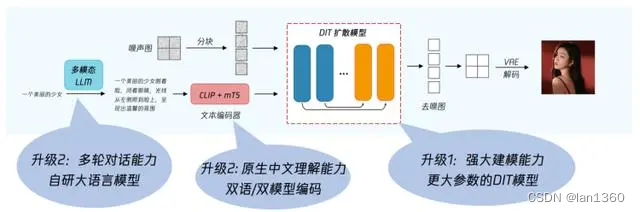
混元文生图大模型自2023年7月明确了基于Transformer架构的发展方向,并投入了长达半年的研发、优化与精细打磨。到了2024年2月,模型基础架构已从U-Net成功升级至Transformer,标志着其技术进步的又一里程碑。
部署流程
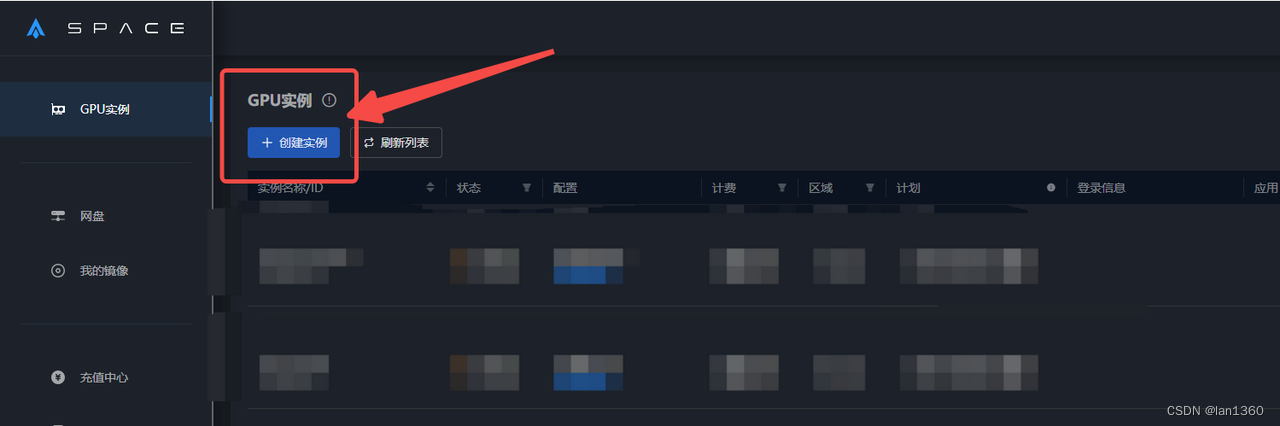
1、注册算力云平台:星海算力
https://gpu.spacehpc.com/
注意1:星海算力有欠费透支功能,大概可以免费体验3小时!
注意2:还可以联系星海客服人员免费领取50元券,差不多可免费体验1天!
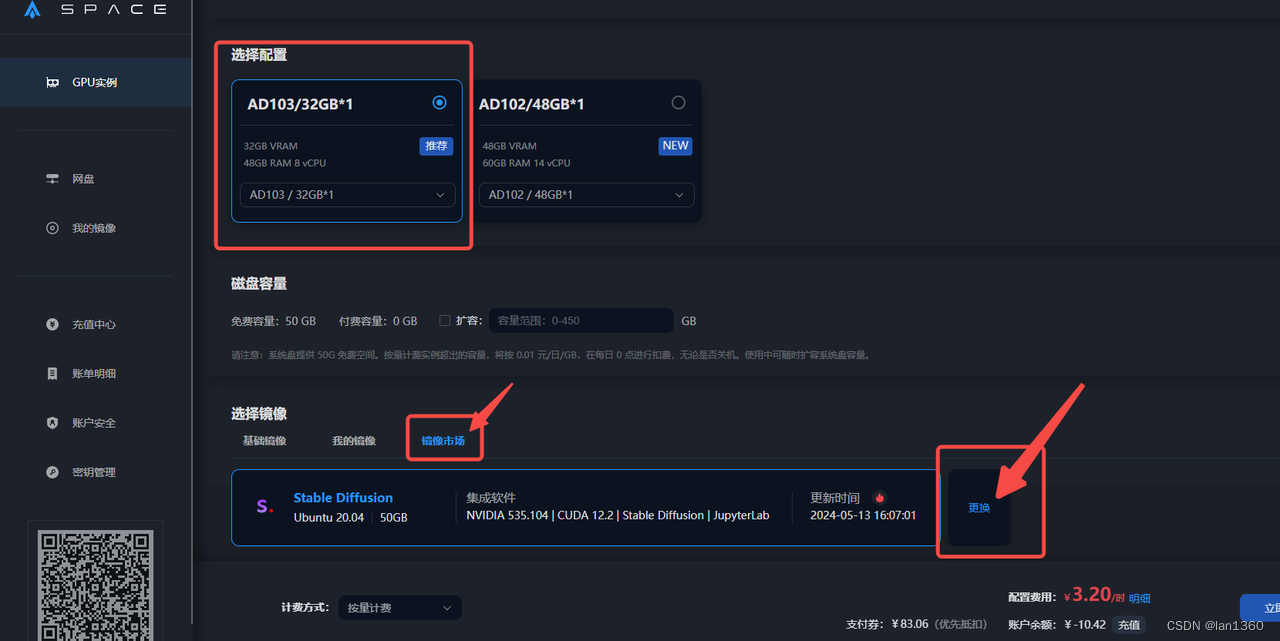
2、选择32GB显存的显卡,这边推荐ad103(和4090性能差不多),或者推荐V100 32GB显存(性能差点)
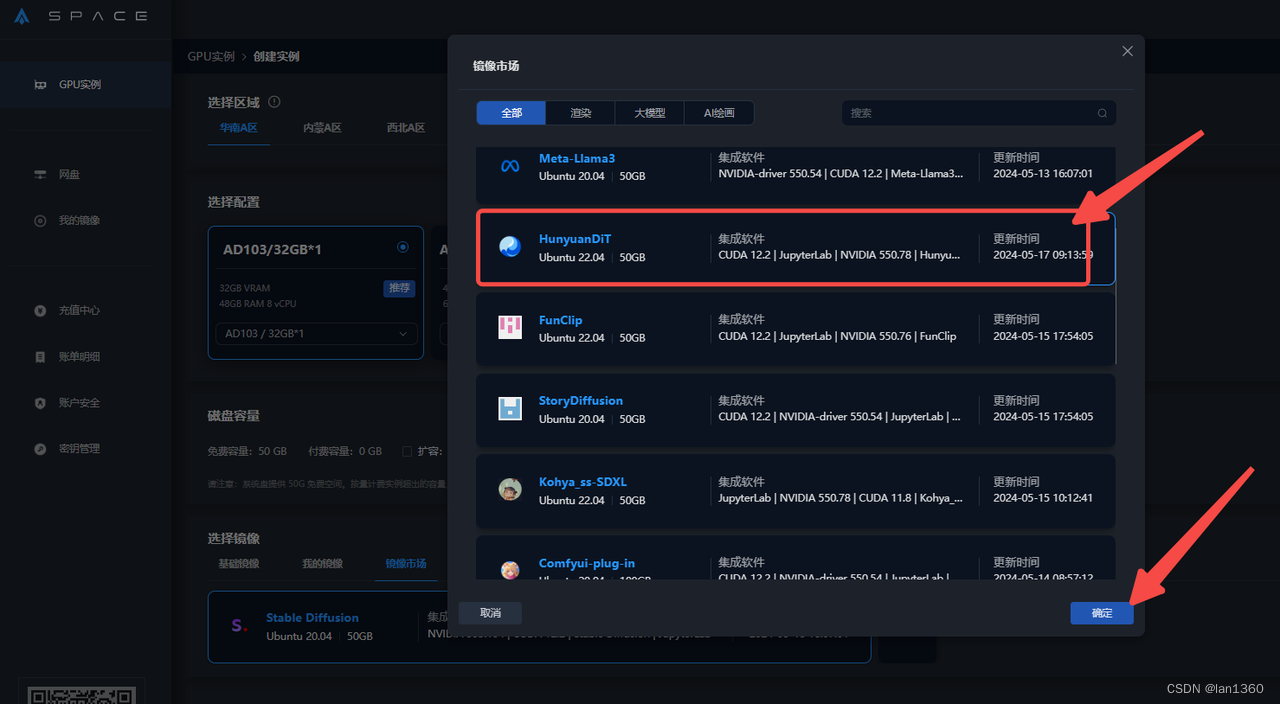
3、选择镜像市场,点击更换镜像,选择腾讯混元镜像,最后点击立刻创建即可
4、创建成功等待4-5分钟,等虚拟机开启,开启成功后,打开应用,即可测试腾讯混元镜像
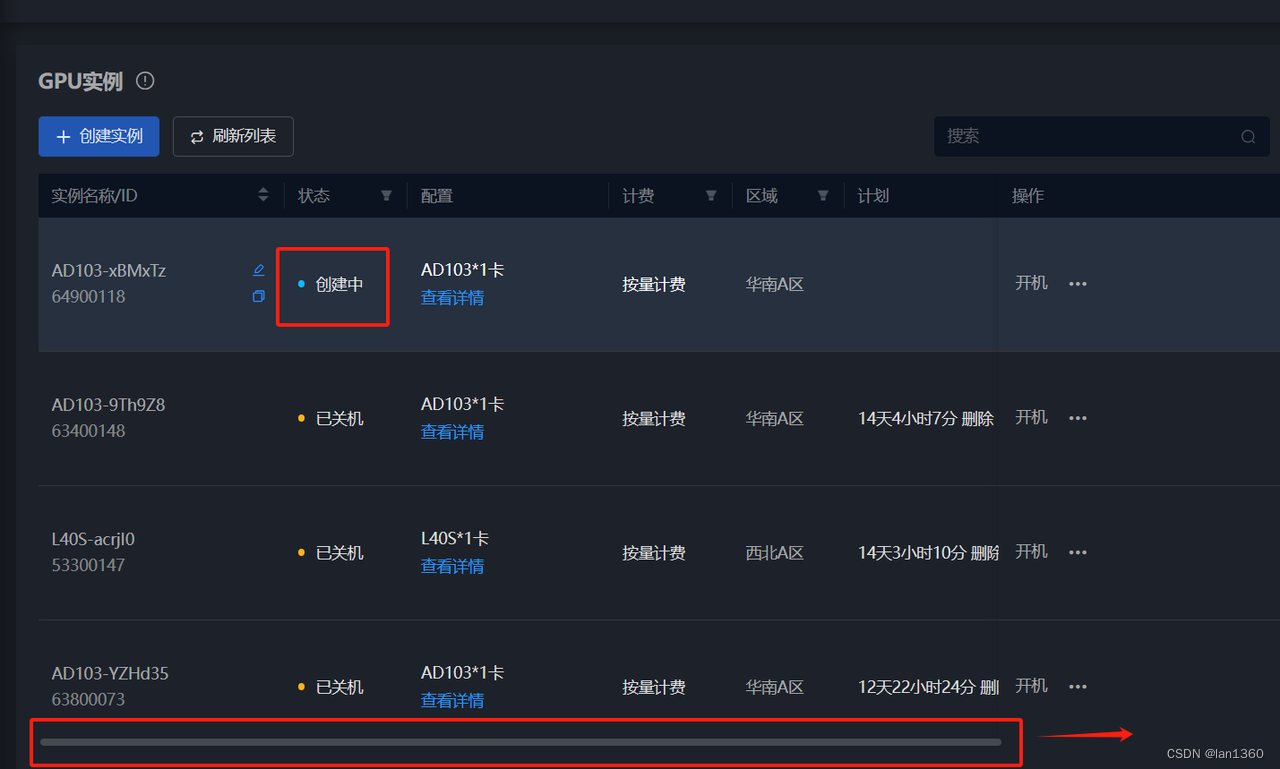
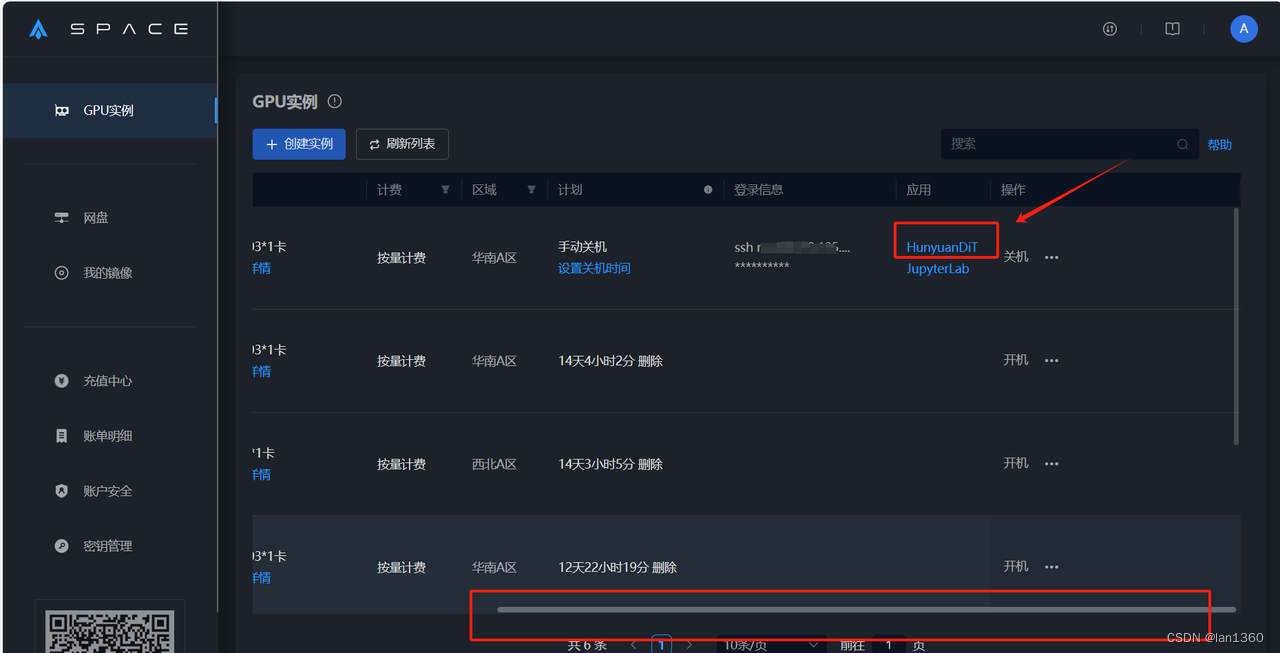
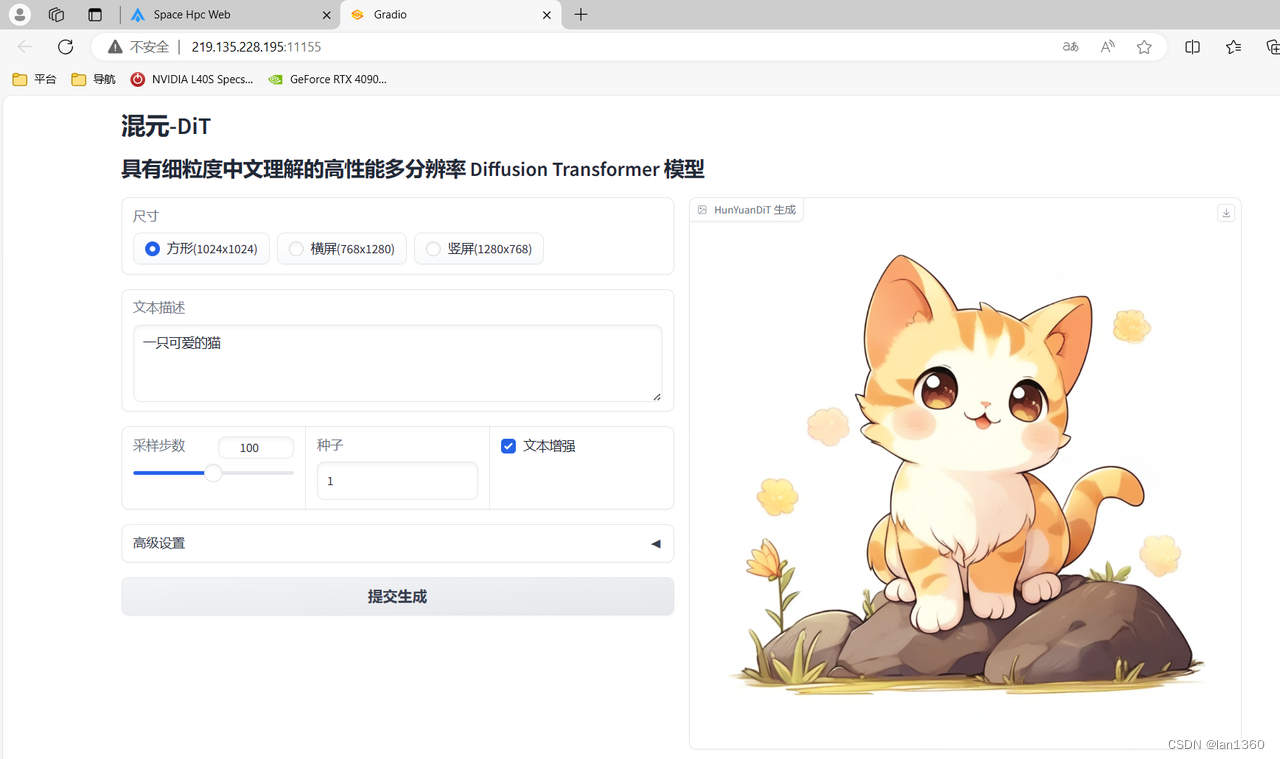
注意:腾讯混元模型比较大,所以开机以后点hunyuan跳转访问不到就稍等一下再访问
关于星海算力云
欢迎使用星海算力云,星海算力云由北京三轴空间科技有限公司开发,由非盈利组织龙游星海算力产业中心运营的高性能GPU算力云平台。
星海团队长期致力于为图像渲染、科研高性能计算等提供服务。星海AI算力服务平台,获超高速增长,团队规模有100余人,服务了国内AI行业的许多一线团队。


















 2546
2546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









