







1.基础知识
虚拟机和容器
操作系统 = 内核 + apps
虚拟化技术=资源隔离+资源控制
虚拟机技术:有自己的内核
容器技术:共享宿主机内核
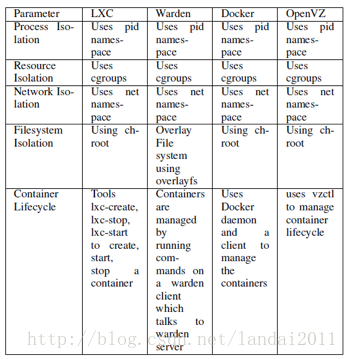
Linux相关模块
A .Chroot
Chroot(改变 根目录)是一个改变当前进程和它子进程根目录到一个新目录的一个linux命令。在虚拟环境下,一些容器用Chroot来隔离和共享文件系统。
B.Cgroups
Cgroups 是内核子系统的一部分,提供了一个很好的细粒度控制,通过共享像CPU,内存,组进程等等的资源。几乎所有的容器都用cgroups作为资源管理的底层机制。Cgroups对这些资源做了限制。
C.内核命名空间
命名空间在不同级别的容器之间创建了栅栏。Pid命名空间允许每个容器有自己的进程id。网络的命名空间精简允许每个容器有一个网络构件,比如 路由表、ip表、回送接口。IPC(信息处理中心)命名空间为各种IPC机制,即信号、信息队列和共享内存片段,提供了隔离。Mnt(模组名表)命名空间为每个容器提供了自己的挂载点。UTS命名空间巴证了不同的容器可以查看以及改变专属的主机名称。
容器的实现:
Linux Containers (LXC)、Warden Container( Cloud Foundry)、OpenVZ 、Google lmctfy 、Docker
对比:
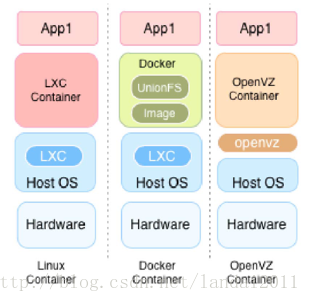
容器层次结构示意图:
2.kubernetes如何编排:
- Pods
Pod是Kubernetes的基本操作单元,把相关的一个或多个容器构成一个Pod,通常Pod里的容器运行相同的应用。Pod包含的容器运行在同一个Minion(Host)上,看作一个统一管理单元,共享相同的volumes和network namespace/IP和Port空间。
这样做的好处,方便绑定服务.比如如果你想运行一个应用,并且监控它的状态,而且又不想监控进程影响应用进程,那么一个pod里运行两个容器,一个跑主业务,一个跑监控,而且监控可以很方便的用localhost访问业务容器. - Services
Services也是Kubernetes的基本操作单元,是真实应用服务的抽象,每一个服务后面都有很多对应的容器来支持,通过Proxy的port和服务selector决定服务请求传递给后端提供服务的容器,对外表现为一个单一访问接口,外部不需要了解后端如何运行,这给扩展或维护后端带来很大的好处。也解决了内部通信,pod ip 不固定的问题! - Replication Controllers
Replication Controller确保任何时候Kubernetes集群中有指定数量的pod副本(replicas)在运行, 如果少于指定数量的pod副本(replicas),Replication Controller会启动新的Container,反之会杀死多余的以保证数量不变。Replication Controller使用预先定义的pod模板创建pods,一旦创建成功,pod 模板和创建的pods没有任何关联,可以修改pod 模板而不会对已创建pods有任何影响,也可以直接更新通过Replication Controller创建的pods。对于利用pod 模板创建的pods,Replication Controller根据label selector来关联,通过修改pods的label可以删除对应的pods。
RC重启后的pod ip地址是随机的. - Labels
Labels是用于区分Pod、Service、Replication Controller的key/value键值对,Pod、Service、 Replication Controller可以有多个label,但是每个label的key只能对应一个value。Labels是Service和Replication Controller运行的基础,为了将访问Service的请求转发给后端提供服务的多个容器,正是通过标识容器的labels来选择正确的容器。同样,Replication Controller也使用labels来管理通过pod 模板创建的一组容器,这样Replication Controller可以更加容易,方便地管理多个容器,无论有多少容器。
label 为key-value值形式,用法很灵活!
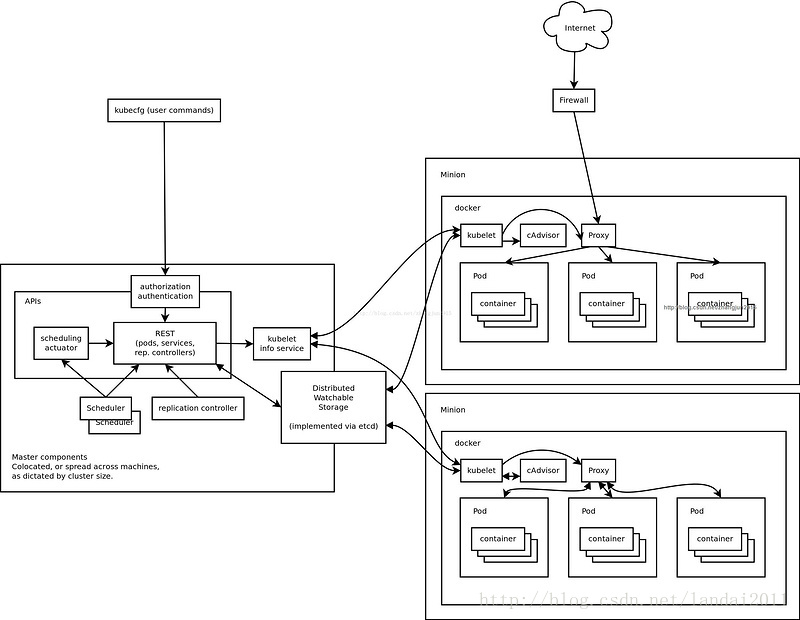
kubernetes架构:
- kube-apiserver:作为kubernetes系统的入口,封装了核心对象的增删改查操作,以RESTFul接口方式提供给外部客户和内部组件调用。它维护的REST对象将持久化到etcd(一个分布式强一致性的key/value存储)。
- kube-scheduler:负责集群的资源调度,为新建的pod分配机器。这部分工作分出来变成一个组件,意味着可以很方便地替换成其他的调度器。
3.kube-controller-manager:执行各种控制器,不断通过api-server监听状态.比如replication controller, endpoints controller, namespace controller, and serviceaccounts controller.并
endpoint-controller:定期关联service和pod(关联信息由endpoint对象维护),保证service到pod的映射总是最新的。
replication-controller:定期关联replicationController和pod,保证replicationController定义的复制数量与实际运行pod的数量总是一致的。 - kube-proxy:负责为pod提供代理。它会定期从etcd获取所有的service,并根据service信息创建代理。当某个客户pod要访问其他pod时,访问请求会经过本机proxy做转发。
kubelet:负责管控docker容器,如启动/停止、监控运行状态等。它会定期从etcd获取分配到本机的pod,并根据pod信息启动或停止相应的容器。同时,它也会接收apiserver的HTTP请求,汇报pod的运行状态。
框架如下图所示:
简要流程:
如何创建pod容器?
1.向API server发送创建请求
2.再由调度器决定minion节点
3.api-server向kubelete发送请求创建容器
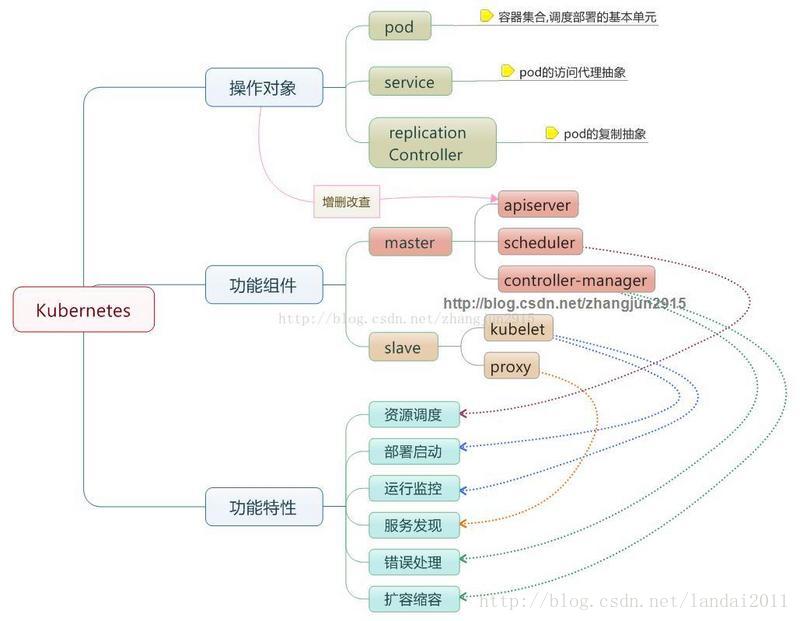
目前cAdvisor已经集成到了kubelet组件内.下幅图为编排对象,组件与功能之间关系!















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









