







单词
- threshold /'θrɛʃhold/ 门槛
- annotation /ˌæno’teʃən/ n. 注解,注释
- genuine /ˈdʒɛnjuɪn/ 真实的
概述
视频中音频和口型对不上挺常见的。有研究表明音频相对于视频的提前量在-125ms (音频滞后) 到 +45ms(音频提前)是普通大众无法察觉的。Syncnet是一个端到端的判断是否同步的网络,不需要将音视频额外编码。通过无标注数据基于卷积网络对音频和嘴形经行特征嵌入(embedding)
作者总结了此网络的三个应用:
- 判断音视频口型同步
- 在多样化的场景中检测说话者
- 唇读
架构
文章网络结构与Siamese Network有些像,网络输入的是0.2s的音频与视频流。音频使用MFCC作为输入(md我数字信号处理没学好,感觉挺头疼),每个时间step使用13 mel频率带宽(mel frequency bands),特征以100Hz采样率计算,0.2s音频输入有20个时间步长。
而视频输入是5帧,因为采样率是25Hz,所以5帧也是0.2s, 输入维度是
115
∗
115
∗
5
115*115*5
115∗115∗5(W H T)
- 输入示例:
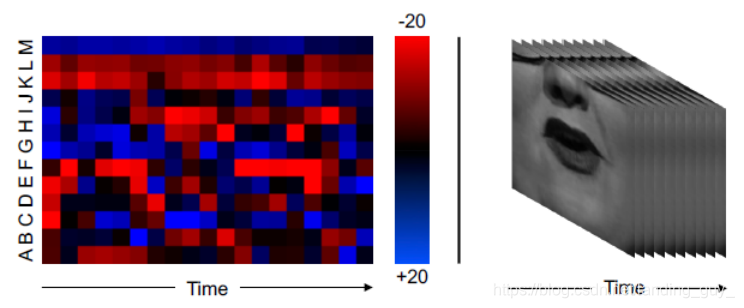
左边是音频作为heatmaps的时间表示,图像中的13行(A到M)对代表不同频率bins的13个MFCC进行编码。 右边是嘴部区域灰度图. 这样经过预处理的视频和音频输入均为二维N通道的"图片" , 每一个"样本"覆盖200ms 的时间窗口
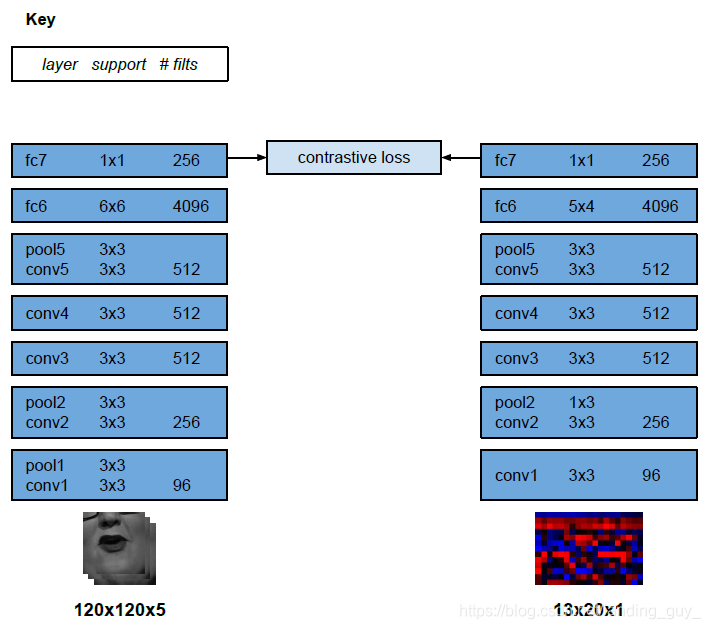
整体架构受VGGM的启发,但是修改了fliter,VGGM正常输入时224*224像素输入,这里改为时间step是20像素,另一个方向是13,所以输入图像为13×20像素, 还与论文Chung, J.S., Zisserman, A.: Lip reading in the wild. In: Proc. ACCV (2016) 类似,使用了Early Fusion模型。
Early fusion指的是先将不同的特征融合再一起,最后再使用分类器对其进行分类,这个融合过程发生在特征之间,一般称之为特征融合或者"early fusion"
- 看看结构
损失函数
训练的目标是音频和视频网络的输出对于真正的配对是相似的,对于错误的配对则不同。
对于上图的Contrastive Loss Function,这个损失函数定下的基本准则是:
- 近似样本之间的距离越小越好。
- 不似样本之间的距离如果小于m,则通过互斥使其距离接近m。
Siamese networks的损失函数是长这样的:
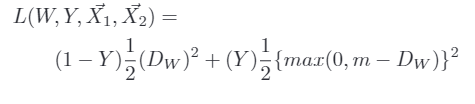
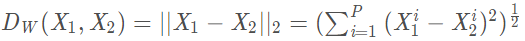
其中 W 是网络权重;Y是成对标签,如果X1,X2这对样本属于同一个类,Y=0,属于不同类则 Y=1。Dw 是 X1 与 X2 在潜变量空间的欧几里德距离。当Y=0,调整参数最小化X1与X2之间的距离。当Y=1,如果X1与X2之间距离大于m,则不做优化(省时省力);如果 X1 与 X2 之间的距离小于 m, 则增大两者距离到m。
对两两距离天生大于m的样本对,对比损失完全忽视这些样本对,大大减少了计算量。
论文里损失函数是这样的:
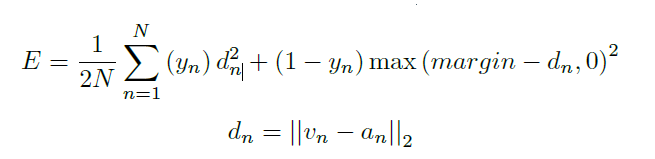
这里Y的取值与上式相反。v与a是fc7的输出,对应音频与视频
训练
对于视频,我们采用了ImageNet分类任务中使用的标准增强方法(例如随机剪切、翻转、颜色移动)。对于每个输入的0.2s也就是一个clip,对所有的视频帧采用一样的转换。
利用带动量的随机梯度下降法学习网络权值。两个网络流的参数是同时学习的。
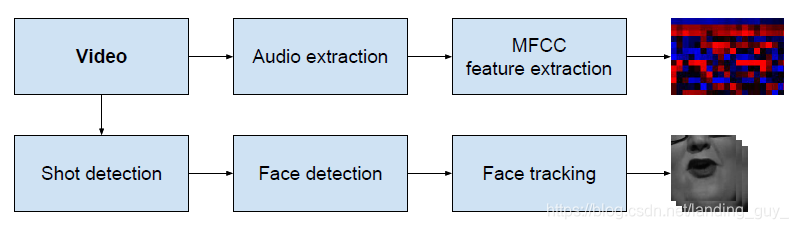
在上图的模型中shot detection值得是确定边界帧,边界帧就是帧与帧之间运动比较明显的帧,这里用比较颜色直方图的方式区分提取。然后使用基于HOG(方向梯度直方图)的方法进行人脸检测,Dlib库就是一种基于HOG的方法, 然后使用KLT tracker将人脸检测分组到帧上, 这句没有很懂?
如果出现了多个人脸就把这帧丢弃。
对于音频,真实的音视频对是由一个5帧的视频剪辑和相应的音频剪辑生成的。只有音频被随机移动至多2秒,以产生合成的假音视频对。如下图所示。可以看到视频帧不变,只有对应的音频帧变了。这样我们可以学到音视频的连接关系。训练一段时间会丢弃那些不匹配的数据。
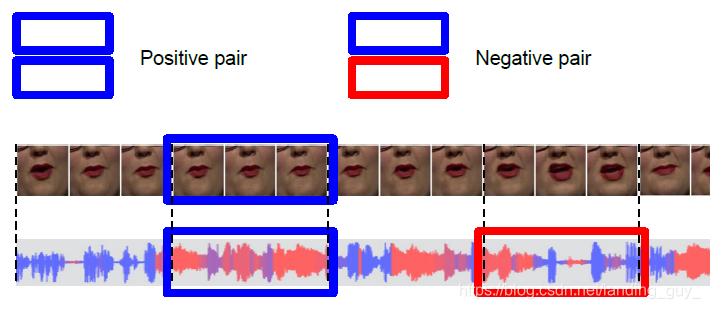
确定唇形同步错误
为了确定音频与视频的时间偏移, 使用了滑动窗口算法, 对于每个样本, 在 ± ± ±一秒范围内计算一个5帧视频特征和所有音频特征的距离, 越小偏移量越小. 但是并不是clip中的所有样本都是有区别的, 例如有些特定时间可能什么都没说, 所以对于每个clip选取多个样本, 然后取平均值.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











