







文章目录
pytorch中关于detach clone 梯度等一些理解
pytorch中有时需要复制一下张量(tensor),如果在迭代过程中就会涉及到梯度的问题。
我了解的常用的tensor复制方式有两种 .detach()和.clone()
1、.detach()方法,比如已有tensor a ,b=a.detach(),则相当于给a起了个别名b,两个在内存中实际是一个东西,但是在计算梯度时,梯度从后面传到b不会再往前传了,到这就截止了。当只需要tensor数值,不需要往前的梯度或者故意将梯度在这儿截断时可以用这个方法。
2、.clone()方法,与上面正相反,如果c=a.clone(),那么c跟a在内存中是两个tensor,改变其中一个不会对另一个的数值造成影响,但是c拥有与a相同的梯度回传路线,保留了继续回传梯度的功能,但不再共享存储。
3、 开始都对tensor这一数据类型比较熟悉,看博客有时会看到variable,形象地理解为这是另一种数据格式,tensor属于variable的一部分,tensor只包含数值,除了tensor,variable还有梯度值,梯度是否可计算等等属性(维度更广了),在迭代过程中从variable变量中取出tensor的操作时不可逆的,因为已经丢失了有关梯度的一切信息。
A = torch.arange(20, dtype=torch.float32).reshape(5,4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
矩阵的创建
A = torch.arange(20).reshape(5, 4)
转置
A.T
矩阵乘法
按元素的乘法又叫做 哈达玛积 (Hadamard product)
数学符号是
⊙
\odot
⊙
# 在pytorch里面很简单
A * B
# 按元素位置相乘,不求和
torch.sum
- 会发现不同的sum维度会减少
A = torch.arange(20*2).reshape(2, 5, 4)
B = A.sum()
C = A.sum(1)
print(B.shape)
print(C.shape)
>> torch.Size([])
>> torch.Size([2, 4])
torch.mean
- dtype=torch.float32 很重要
A.mean(), A.sum()/A.numel()
# 平均等价于求和除个数
A.mean(axis=0), A.sum(axis=0) / A.shape[0]
计算总和或均值时保持轴数不变
- 这时应该被减去的维度就是1
- 好处就是可以使用广播机制了
sum_A = A.sum(axis=1, keepdims=True)
A / sum_A
cumsum
a=torch.arange(0,12).reshape(3,4)
print(a)
'''
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
'''
b=a.cumsum(0)
print(b)
'''
tensor([[ 0, 1, 2, 3],
[ 4, 6, 8, 10],
[12, 15, 18, 21]])
'''
点积是相同位置的按元素乘积的和
x = torch.arange(4, dtype=torch.float32)
y = torch.ones(4, dtype=torch.float32)
print(x.dot(y)) # 和哈达玛积的区别就是多了一个sum操作
print(torch.sum(x*y))
>> tensor(6.)
>> tensor(6.)
矩阵-向量积
x = torch.arange(12,dtype=torch.float32).reshape(3, 4)
y = torch.arange(4,dtype=torch.float32)
print(x)
print(y)
print(x.mv(y))
>> tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
>> tensor([0., 1., 2., 3.])
>> tensor([14., 38., 62.])
矩阵矩阵乘法
- 可以把矩阵-矩阵乘法AB看作是简单的执行m次矩阵-向量积, 并将结果拼接在一起, 形成一个n * m 矩阵
x = torch.arange(12,dtype=torch.float32).reshape(3, 4)
y = torch.ones(4,3)
print(x.mm(y))
矩阵范数
- L2范数是向量元素平方和的平方根:
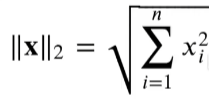
u = torch.tensor([3.0, -4.0])
print(torch.norm(u)
tensor(5.)
- L1范数, 它表示为向量元素的绝对值之和:
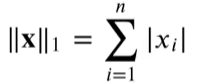
u = torch.tensor([3, 4], dtype=torch.float32)
norm1 = torch.abs(u).sum()
- F范数, 矩阵的弗洛贝尼乌斯范数(Frobenius norm), 是矩阵元素的平方和的平方根, 类似于把矩阵展平然后计算L2 norm
a = torch.ones((4, 9))
print(a.norm())
>> tensor(6.)
按轴计算
- 以最简单的举例
假设有个向量是5*4, axis 0 对应5, axis 1 对应4 - 按行就是轴为0, 按列就是轴为1

注意keepdims这个参数, 会把应该消除的轴变为1
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











