







 本次与大家分享一篇建模长文本篇章结构的工作,用以提升生成文本的连贯性。
本次与大家分享一篇建模长文本篇章结构的工作,用以提升生成文本的连贯性。
欢迎关注「澜舟论文领读」专栏!关注“澜舟科技”公众号探索更多 NLP 前沿论文!
本期分享者:杨二光
北京交通大学自然语言处理实验室四年级博士生,导师为张玉洁教授,研究方向为可控文本生成、复述生成、故事生成。在澜舟科技实习期间主要从事长文本生成、营销文案生成等课题。
前言:
近年来,多个大规模预训练语言模型GPT、BART、T5等被提出,这些预训练模型在自动文摘等多个文本生成任务上显著优于非预训练语言模型。但对于开放式生成任务,如故事生成、新闻生成等,其输入信息有限,而要求输出内容丰富,经常需要生成多个句子或段落,在这些任务上预训练语言模型依然存在连贯性较差、缺乏常识等问题。本次与大家分享一篇建模长文本篇章结构的工作,用以提升生成文本的连贯性。
论文题目:DISCODVT: Generating Long Text with Discourse-Aware Discrete Variational Transformer
论文作者:Haozhe Ji, Minlie Huang
论文单位:清华大学
论文链接: https://github.com/cdjhz/DiscoDVT,EMNP2021
动机(Motivation)
文本的全局连贯性一般表现为:
- 内容表达的流畅度和
- 内容之间的自然过渡。
如下图示例文本中的话语关系词(after, then, and, but等),这些篇章关系词将连续的文本片段(text span)进行合理安排,从而形成结构、逻辑较好的文本。虽然预训练语言模型在关联与主题相关的内容时表现较好,但用好的篇章结构来安排内容仍然存在很多挑战。针对此问题,研究者提出建模文本内部片段与片段之间的篇章关系,利用篇章结构指导生成,以期能够改进生成文本的连贯性。

图 1 EDU片段和篇章关系示例
方法(Method)
2.1 任务定义
首先,长文本生成的任务可以定义为:给定输入 x = ( x 1 , x 2 , ⋯ , x N ) x=(x_1, x_2, \cdots ,x_N) x=(x1,x2,⋯,xN),模型自动生成 y = ( y 1 , y 2 , ⋯ y M ) y=(y1,y2,⋯yM) y=(y1,y2,⋯yM), y = ( y 1 , y 2 , ⋯ , y M ) y=(y_1, y_2, \cdots , y_M) y=(y1,y2,⋯,yM)的过程,即 p ( y ∣ x ) p(y|x) p(y∣x)
基于以上的讨论,该工作基于VQVAE的方法提出DiscoDVT(Discourse-aware Discrete Variational Transformer),首先引入一个离散code序列 z = ( z 1 , z 2 , ⋯ , z L ) z=(z_1,z_2, \cdots ,z_L) z=(z1,z2,⋯,zL)学习文本中每个局部文本片段(span)的高层次结构,其中每一个 z l z_l zl从大小为 K K K的code vocabulary中得到。随后作者进一步提出一个篇章关系预测目标,使离散code能够捕获相邻文本片段之间显式的篇章关系,比如图1中的篇章关系,after,then等。
整个方法包括后验网络 q ϕ ( z ∣ y ) q_\phi (z|y) qϕ(z∣y)、生成器 p θ ( y ∣ z , x ) p_\theta (y|z,x) pθ(y∣z,x)和先验网络 p ψ ( z ∣ x ) p_\psi (z|x) pψ(z∣x),使用类似VAE的学习目标,该方法通过最大化ELBO来优化。
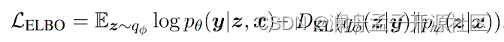
训练过程分为两个阶段,第一阶段联合训练后验网络和生成器,使后验网络根据 y y y推导出离散的code序列 z z z,其中要求 z z z能够学习到 y y y的高层次结构,生成器则根据 x x x和code序列 z z z重构 y y y。
第二阶段训练先验网络,使其能够根据 x x x,预测离散code序列 z z z。
两阶段训练完成之后,在生成阶段,先验网络首先根据 x x x预测离散code序列z,随后z用于指导生成文本,z中带有篇章结构信息,因此能够提升生成文本的连贯性。
2.2 学习离散隐变量
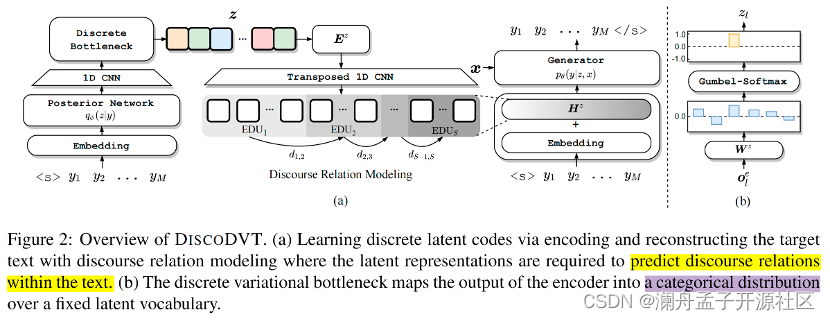
图 2 模型整体框架
这部分主要解决如何学习隐变量code序列 z z z
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









