







1 背景
爬虫的价值就不多说了,Python 的便捷与强大也就不 BB 了,在这个数据泛滥、追求效率的时代,使用 python 可以为我们创造相当多的便捷,Web 开发、桌面小工具开发、粘性脚本编写、大数据处理、图像处理、机器学习等等,能做到的事情实在太多。就拿一个再随便不过的需求来说吧,当我们在做 Android 开发时想将现有 drawable 目录下 *.png 图片全部自动转换为 webp 格式时,我们一般的套路可能都是借助第三方工具(很多都只能一张一张转换),而使用 Python 核心就两行代码就可以做到这一点,如果想批量自定义转换姿势(路径、文件名等),使用 Python 也是非常方便的,譬如这里就有一个我写的非常简单的 Python png 批量转换 webp 工具。具体源码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
震撼吧,人生苦短,我用 Python!真的是这样咯,不过这一系列我们不探讨 Python 的其他奥妙,而是直接探讨一个垂直领域 —— Python 爬虫。其实双赢的爬虫(搜索引擎收录爬虫就是共赢的,地下黑作坊在网上肆意洗数据,譬如洗邮箱数据就是被抵制或非法的)对于大多数网站来说是有利的,而恶意的爬虫就适得其反了。正常来说我们想要获取某些网站数据应该通过他们的开放 API 进行合法授权访问,但是企业毕竟是企业,都是有所保留的开放 API 权限,所以有时候我们不得不使用暴力手段来洗劫有价值的数据,这也就是爬虫存在的一大价值。
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
2 爬虫基础
爬虫其实涉及的东西还是比较杂和多的,比较重要的几点可能就是得掌握 Python 语法基础和一些常用的内置或者拓展模块、熟悉 WEB 开发的相关知识、熟悉数据持久化(关系型数据库、非关系型数据库、文件)缓存等一些技术、熟悉正则等。
2-1 约定俗成的潜规则
对 WEB 了解的朋友都知道一般的网站都会有 robots.txt 和 Sitemap 定义,这些定义其实对我们进行合理化的爬虫编写是具备指导意义的,譬如我们看下稀土掘金(https://juejin.im)这个网站的 robots.txt 文件(https://juejin.im/robots.txt),如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
robots.txt 中定义的 Sitemap,访问(https://juejin.im/sitemap/sitemappart1.xml)如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以看到 robots.txt 文件内容明确建议(注意:只是建议,只是建议,只是建议,恶意的爬虫管你这屁建议呢)了爬虫程序爬取该网站时有哪些限制,一般遵守这些限制规则就能很好的降低自己爬虫被封的风险;Sitemap 提供了网站几乎所有的页面列表,我们可以使用这个列表直接爬取这个站点,也可以自己采用别的方式,因为这玩意不是每个网站都有的。所以说 robots.txt 和 Sitemap 只是约定俗成的潜规则,潜规则,一般我们酌情遵守就行了,譬如可以考虑遵守他们提到的访问请求间隔、代理禁止类型等,其他的就看你自己的节操了。
2-2 基本工具
俗话说“工欲善其事必先利其器”,爬虫也需要一些利器。对于 Python 开发工具我选择 PyCharm 和 Sublime;对于浏览器可以选择 Chrome 等,再安装一些 WEB 开发插件,譬如 FireBug、Wappalyzer、Chrome Sniffer 等,方便爬虫时分析网站,尤其是浏览器 F12 大法和清空站点 Cookie 一定要掌握,不然就没法愉快的玩耍爬虫了。当然了,爬虫的核心之一其实在于抓取到数据后如何筛选出对自己有价值的数据,关于做到和做好这一点我们有必要对站点页面有一个比较准确的把握,想要做到这一点就必须大致知道该网页使用了那些技术,这样就可以提高我们分析页面的效率。分析网页使用哪些技术有很多方法,也有很多浏览器插件,譬如上面提到的 Chrome Sniffer等;也可以直接访问 https://builtwith.com/ 网站输入你要爬取的网页进行识别;当然也可以用 Python 的 builtwith 模块来获取,悲哀的是这个模块现在不支持 Python 3.X 版本,需要自己安装后手动修改。
当然了,还有一个不常用的利器需要知道,那就是度娘和 Google 咯,为啥呢?因为有时候我们大型项目可能需要先大致评估全站点爬虫的量有多大来进行相关爬虫的技术选型参考,所以有必要知彼知己。下面就以稀土掘金为例说明,如图:
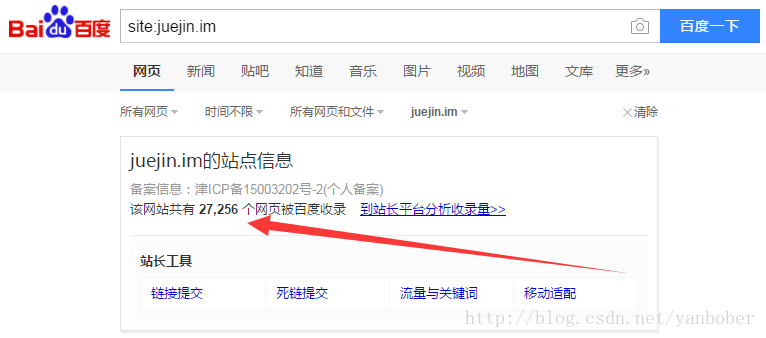
可以看到,通过 site 指令度娘搜索告诉我们稀土掘金这个站点大约有 27256 个页面(这只是参考值,不完全准确),当我们真的需要全站点爬虫攻击时就要考虑这么大量情况下的爬虫方案选型和策略,以便保证爬虫的效率。
2-3 基本爬取技术思路
爬虫涉及的通用技术最核心的可能就是 HTTP 请求了,我们至少至少应该掌握 HTTP 的 POST 和 GET 请求方法;其次就是 HTTP 请求和返回的 Header 含义及如何使用浏览器等工具跟踪请求 Header,因为爬虫链接请求时出现问题最多的情况一般都是 Header 有问题,譬如通常至少要保证 User-Agent、Referer、Cookie 等的伪装正确性,返回 Header 里的重定向链接,Gzip 数据需要解压等;还有就是 POST 数据的 urlencode 包装发送等;所以在进行爬虫前一定要具备比较扎实的前端与后端基础知识,同时要具备比较充足的 HTTP 知识。
有了这些知识我们可能就会急于开始爬取,其实这是不对的,我们应该做的第一件事是对要爬取的站点进行分析,至于如何分析,下面给出了一些常规套路:
-
首先倒腾下看你要抓取的站点有没有响应式的移动页面,如果有那就保持一个原则,尽可能的抓取他们的移动页面(原因就是一般移动页面都是内容干货啊,相对 PC 页面没那么臃肿,方便分析)。
-
Cookie 的操蛋之处,分析时建议开启隐身模式等,不然就面对清空 Cookie 大法了,清空 Cookie 对于爬虫网站分析至关重要,一定要 get 到。
-
分析爬取网页是静态页面还是动态页面,以便采取不同的爬取策略,使用不同的爬取工具。
-
查看网页源码找出对你有价值的数据的网页排版规律,譬如特定 CSS 选择等,从而指定抓取后的数据解析规则。
-
清洗数据后选择如何处理抓取到的有价值数据,譬如是存储还是直接使用,是如何存储等。
以上几个套路摸索清楚以后就可以开始编写爬虫代码了,不过这时候还是有很多代码套路需要注意的,譬如 URL 的重复爬取、无效 URL 的剔除、爬虫欺骗、爬取异常处理等,如果想要自己的爬虫十分健壮,上面这些套路似乎都是必须要考虑的。
当然了,上面说的只是爬虫基础的核心事项,大型爬虫项目涉及的知识点就更加琐碎了,随着这个系列的渐进,我们会慢慢接触到的,下面我们先小牛试刀一把。
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
3 实战一把,先爬起来嗨
BB 了辣么多基础,还没有任何实战,搞毛线啊!Talk is easy, show me the code!既然是 Python3.X 爬虫实战系列,所以我们先让自己爬起来,故我们先来看看一个爬虫的常规套路流程结构,如下图(此图引用自网络):
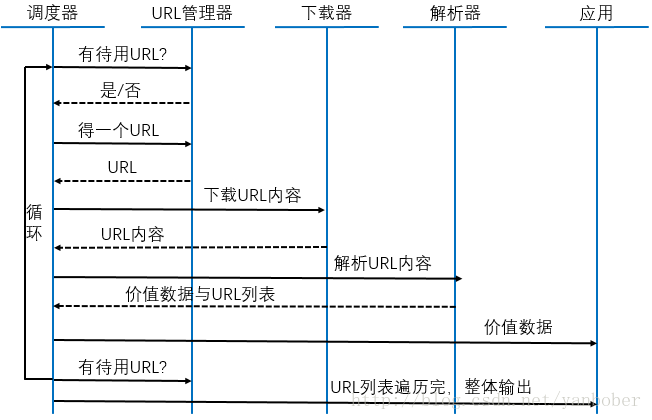
看到了吧,一个爬虫的核心流程其实就是拿到一个 URL,下载下来这个 URL 指定的数据(网页或者结构化数据),解析出有价值的数据供自己使用,所以其实爬虫的核心机制流程就是不停的重复执行这个流程,日复一日的帮你在那各种爬呀爬呀爬。
依据上面的爬虫流程图,下面我们给出一个简单的爬虫程序,以便理解和感觉爬虫的魅力。下面是一个深度爬取百度百科 android 词条简介及其衍生词条简介的实例,具体可以点击我在 github 查看该爬虫模块源码,这个小爬虫程序不是那么健壮,但是足以说明上面的流程图,该小爬虫包结构如下图:

我们在命令行执行 python3 spider_main.py 或者在 PyCharm 中点击 spider_main.py 文件右键运行就能看到爬虫开始爬取数据了(注意:该小爬虫依赖 BeautifulSoup 外部模块,如果没安装建议运行前先使用 pip 进行安装,命令为 pip install beautifulsoup4;其次该小爬虫默认只深度爬取 30 个链接),最终 30 个链接爬取完成后会在当前目录下自动输出了一个名为 out_2017-06-13_21:55:57.html 的 HTML 页面的表格,我们可以打开文件发现爬取的结果如下:

怎么样?我们爬取了百度百科一些关于 Android 和深度链接的名词介绍,然后依据自己喜好输出了一张 WEB 页面,当然咯,我们可以把这些数据写入数据库,再用 PHP 等编写 RESTFUL 接口通过 JSON 结构化语句返回给 APP 使用,赞不赞,再也不用为了自己做个小 App 到处去寻找免费的 API(譬如去聚合数据寻找),完全可以解放双手自动抓取和使用,不过一定不要未经授权直接抓取给商业 APP 使用,这可能会被起诉的。
下面是 https://github.com/yanbober/SmallReptileTraining/tree/master/AndroidSpider 这个小爬虫的源码,大家可以对照上面的爬虫流程图进行对比。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
哇呜!就是这么赞,怎么样,到此有没有对 Python 小爬虫产生一个整体的认知呢,如果表示了解了,那么我们下一篇会循序渐进的谈谈其他 Python 爬虫技术点(当然了,上面代码虽然很少,但是你可能还是觉得有些看不懂,那就的自己去补习下相关知识了,至于细节不在本系列探讨范围)。
^-^当然咯,看到这如果发现对您有帮助的话不妨扫描二维码赏点买羽毛球的小钱(现在球也挺贵的),既是一种鼓励也是一种分享,谢谢!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









