







接上篇
MySQL 数据库简单介绍 以及在 Ubuntu中 关于 MySQL 的操作 数据类型和约束
数据库中操作的 sql 语句
一. mysql 数据库的基本操作
1.Ubuntu中登录和登出数据库
登录数据库: mysql -uroot - p
- -u 后跟的是登录的用户名
- -p 后边是登录密码, 如果不填写,回车之后会提示输入密码的
显示当前时间: select now()
退出数据库: quit / exit / ctrl + d
2.数据库的操作
- 展示当前系统中所有的数据:
show databases; - 新建数据库:
create database 数据库名 charset=utf8
(一定要指定字符集<默认是latin1, 不能放中文>) - 进入到指定的数据库:
use 数据库名;
(刚登录是记得切换, 默认是 null) - 查看当前正在使用的数据库
select database(); - 删除数据库(慎用):
drop database
3. 表结构操作
表结构指的就是字段名, 类型, 约束
- 1.展示当前数据库中所有的表:
show tables - 2.创建表 :
create table 表名(字段名 类型[约束],...)
eg:
create tabele students(
id int unsigned primary key auto_increment,
name varchar(32) not null,
age tinyint unsigned default 18,
height decimal(5,2) not null,
gender enum('男','女','保密')
);
- 3.查看表结构<描述 describe 信息>:
desc students; - 4.展示建表语句:
show create table students; - 5.展示建库语句:
show create detabase 数据库名; - 6.删除表结构:
drop table students; - 7.修改表结构:
alter table 表名
eg:
# 添加字段 alter table 表名 add 字段名 类型[约束];
alter table students add birthday datatime not null;
# 修改字段约束和 类型 alter table 表名 modify 字段名 新类型 新约束;
alter table students modify birthday date;
# 修改字段名 约束和类型 alter table 表名 change 原字段名 新字段名 新类型 新约束;
alter table students change birthday birth date not null;
# 删除字段
alter table students drop birth;
4. 表数据操作
- 1.查找 select
# select 字段名, ... from 表名,
# select * from 表名; 查看表中所有字段的数据
select id,name,age,height,gender from students;
select * from students;
select name,age from students where age>19;
- 2.添加 insert
insert into 表名(字段名,...) values(数据1,..),(数据1,...) - 字段名 数量顺序和数据一一对应
- 字段 使用0, default, null 表示默认值
# 全列插入 每次插入数据和表结构字段顺序完全一样
# 全列插入的情况 省略字段元祖
insert into students(id,name,age,height,gender) values(0,'张三',18,175.15,'男');
insert into students(id,name,age,geight,gender) values(3,'张三丰',158,180.18,'男'),(null,'郭襄',20,160,'女');
insert into students values(0,'张无忌',18,185,'男');
insert into students(id,name,sge,height,gender,is_delete) values (0,'周芷若',18,170,'女',0);
# 部分列插入 每次插入数据和表结构字段顺序数量不完全一样
insert into students(name,height,gender) values('赵敏',170,'女'),('周芷若',170,'女');
- 3.修改 update
update 表名 set 字段名 = 值 where 条件
# 把名字为 张三丰的年龄修改为 20
update students set age=20 where name='张三丰';
# 把年龄全部修改为 20
update students set age=20;
- 4.删除 delete
delete from 表名 where 条件
# 1.物理删除
# 物理删除 在储存上删除 不好恢复
delete from students where id = 8;
# 2.逻辑删除
# 类似于回收站 当删除记录时, 只给记录做了标记
# 2.1新增一个字段用来标识当前记录是否被逻辑删除
alter table students add is_delete bit default 0;
# 2.2 逻辑删除 给这个记录修改一个标记
update students set is_delete = 1 where i = 7;
# 验证
select * from students where is_delete = 0;
# 2.3 撤销删除 给这个记录修改原有标记
update students set is_delect = 0 where id =7;
5.where条件 筛选表中满足条件的数据
- where 条件 筛选表中满足条件的数据
- 查看所有记录的所有字段数据
select * from students; - 查看没有被逻辑删除的记录的所有字段
select * from students where is_delect = 0;
6. as 关键字
作用: 给sql 中字段或者标明起别名原名 as 别名
- 一旦起别名之后 在当前sql 中就不能再使用原名 只能使用别名
- 别名只在当前 sql 中有效
- 不会影响真正的表或者字段名字
- 在 mysql 中 as 可以省略
1.给字段起别名
select name as '姓名', age as '年龄' from students;
select name '姓名', age '年龄' from students;
2.给表起别名<自连接需要> select 表名.字段名
select name as '姓名', age from students as s;
select s.name as '姓名', s.age from students as s;
7. distinct
作用: 取出结果集中重复行select distinct 字段名,...from 表;
select distinct gender from students;
select distinct gender, age from students;
8.where 子句
- 筛选表中满足条件的记录
- 枚举类型元素在比较的 可以不使用元素 而是用对应位置从1开始
1.比较运算符
- 等于: =
- 大于: >
- 大于等于: >=
- 小于: <
- 小于等于:<=
- 不等于: != 或者 <>
# 查询学生表中身高大于170的数据
select * from students where height > 170;
# 查询学生表中性别不为女的数据
select * from students where gender != '女';
select * from students where gender <> '女';
select * from students where gender <> 2;
2.逻辑运算符 and or not
- 不能使用连写方式
# 身高大于170的男性
select * from students where height > 170 and gender = 1;
# 年龄在17和25 之间的数据
select * from students where age >= 17 and age <= 25;
# 年龄等于20或者18的数据
select * from students where age = 18 or age = 20;
3.模糊查询
- like 是模糊查询关键字
- % 表示任意多个任意字符
- _ 表示一个任意字符
# 查询名字是黄X的数据
select * from students where name like '张%';
# 查询名字是姓黄的数据
select *from students where name like '张_'
4.范围查询
- between …and … 表示在一个连续的范围内查询
- in 表示在一个非连续的范围内查询
# 查询年龄 在17和25之间的数据
select * from students where age between 17 and 25;
# 查询 年龄是 18,28,38,48的数据
select * from students where age in (18,20,38,48);
# not 取反 查询年龄不是 18,28,38,48的数据
select * from students where age not in (18,20,38,48)
5.空判断
- 判断为空的使用: is null
- 判断非空的使用: is not null
- 不能使用 where height = null 判断是否为空
- 不能使用 where height != null 判断是否非空
- bull 不等于’空字符串’
# 判断性别字段是否为空
select * from students where gender IS null;
# 判断性别字段是得空 不能说不是空
select * from students where gender IS not null;
9.排序查询 order by
作用: 按照一个或者多个字段进行有序<从高到底-降序 从低到高-升序>
- 网页的排序规则: 关键字和网页匹配程度,竞价,点击量
- 按多个字段排序: 前别一个字段相同就按后边一个字段进行排序
- asc 从小到大排序, 升序
- desc 从大到小排序, 降序
- 按照默认列值从小到大排序
语法结构: `order by 字段名 排序方式, 字段2 排序方式 ,…
# 按照身高向上倾斜 升序
select * from students order by height asc;
# 按照身高向下倾斜 降序
select * from students order by height desc;
# 多字段排序
# 按照身高降序排列 身高相同按照 id 降序排列
select * from students order by height desc, id desc;
# 按照年龄升序 年龄相同的按照身高排序
select * from students order by age asc, height asc;
10. 分页查询
意义: 服务器数据量太大了,不可能一次性的将全部数据给用具, 就会将数据分成一页一页的形式, 然后根据用户的需要将这些数据分别给用户.
语法形式: limit[起始下标= 0] 数据数量
# 求出身高的前三甲
select * from students order by height desc limit 0,3;
# 如果起始下标是0 可以写成 limit 数量
select * from students order by height desc limit 3;
# 求身高的第 3,4,5,6个数据
select * from students order by height desc limit 3,4
limit 分页公式:
| 用户第1页 | 0,1,2 | limit 0,3 |
|---|---|---|
| 用户第2页 | 3,4,5 | limit 3,3 |
| 用户第3页 | 6,7,8 | limit 6,3 |
| 用户第n页 | (n-1)*3,… | limit 3(n-1),3 |
用户第n页 每页m条 limit m(n-1),m
二. mysql 数据库的条件查询
1.聚合函数
聚合函数又叫组函数, 通常是对表中的数据进行统计和计算,一般结合分组(group by)来使用,用于统计和计算分组数据.
聚合函数默认忽略字段为 null 的记录, 想要列值 null 的记录也参与计算, 必须使用 ifnull 函数对 null 值做替换
常用的聚合函数:
- 1.count : 表示求指定列的总行数
- 2.max:表示求指定列的最大值
- 3.min: 表示求指定列的最小值
- 4.sum: 表示求指定列的和
- 5.avg: 表示求指定列的平均值
如果字段值为 null 的话,不计入统计结果
1.计数 count
# 求出总行数
select count(*) from students;
# 求出id的行数
select count(id) from students;
# 得到不重复性别的数量
select count(distinct gender) from students;
2.最大值 max
# 求出年龄最大的数据
select max(age) from students;
3.最小值 min
# 求出身高最小的数据
select min(height) from students;
4.sum 求和
# 求身高和
select sum(height) from students;
5.avg 平均值
# 求身高的平均值
select sum(height)/count(height) from students;
select avg(height) from students;
2.分组查询
分组查询就是将查询结果按照指定字段进城分组, 字段中数据相等的分为一组.
字段相同的在同一个组.
语法:group by 分组字段名
说明:
- 列名: 指按照指定字段的值进行分组
- having条件表达式:用来过滤分组后的数据
- with rollup: 在所有记录的最后加上一条记录, 显示 select 查询时聚合函数的统计和计算结果.
分组之后, 数据结构发生变化 不能直接使用 sql 进行操作
2.1 group_concat(字段名) 将同组成员的字段拼接在一起显示
select gender,group_concat(name) from students group by gender;
2.2 结合组函数使用
group 分了 4 个组, 最终组函数会统计出4个值
select gender, group_concat(name), count(*) from students group by gender;
select gender,avg(age),count(*) from students group by gender;

2.3 where 筛选表中的数据
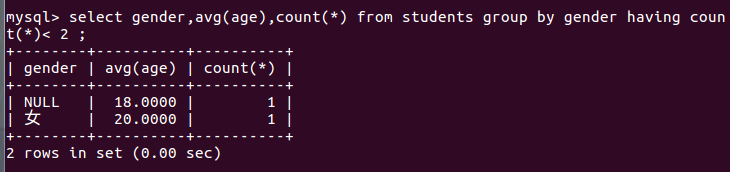
# 按照性别分组, 将分组中人数数量少于 2 个人的组显示出来
select gender,avg(age),count(*)
from students
group by gender
having count(*)< 2 ;
# 按照性别分组 筛选出其中平均年龄低于20岁的分组数据
select gender,avg(age),count(*) from students group by gender having avg(age) < 20;
select gender, avg(age) as aage, count(*) from students group by gender having aage<20;

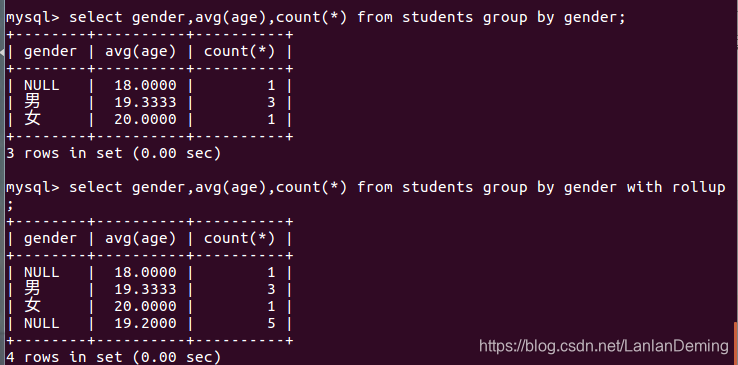
# 汇总显示 with rollup
# 最后一行新增行 专门用来显示汇总结果
select gender, avg(age), count(*) from students group by gender;
select gender,avg(age),count(*) from students group by gender with rollup;
3.连接查询
意义: 当需要求出的结果来自多张标的拼接的时候
连接查询可以分为:
- 1.内连接查询
- 2.左连接查询
- 3.有连接查询
- 4.自连接查询
hero 表和 gongfu 表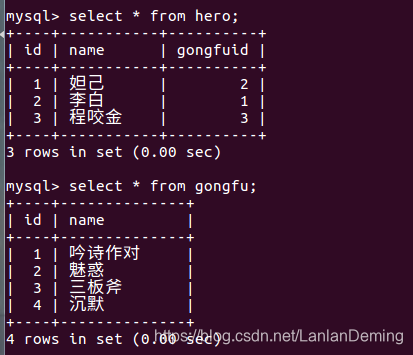
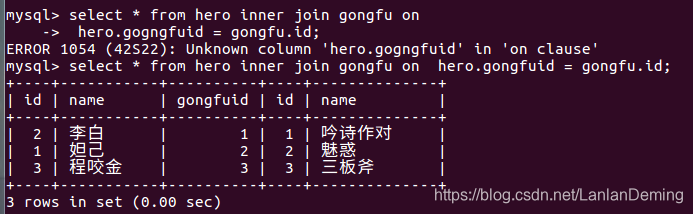
3.1 内连接查询
内连接查询表示两个表中符合条件的共有记录.

语法:select 字段 表1 inner join 表2 on 表1.字段1 = 表2.字段2;
select * from hero inner join gongfu on
hero.gongfuid = gongfu.id;
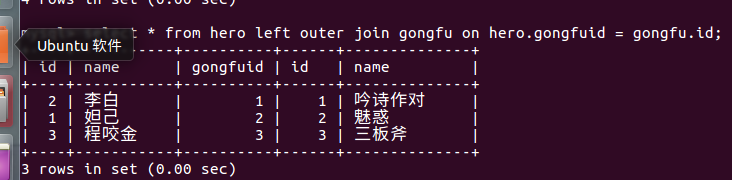
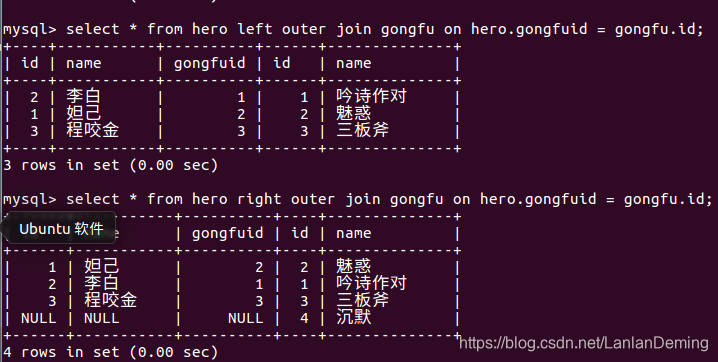
3.2 左连接查询
以左表为主根据条件查询右表数据, 如果根据条件查询右表数据不存在使用null值填充
语法:select 字段 from 表1 left hoin 表2 on 表1.字段1 = 表2.字段2;
select * from hero left outer join gongfu on hero.gongfuid = gongfu.id;
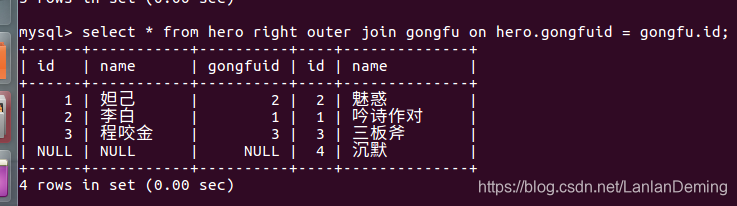
3.3 右外连接
以右表为主根据条件查询表数据, 如果根据条件查询坐标数据不存在使用 null 值填充;
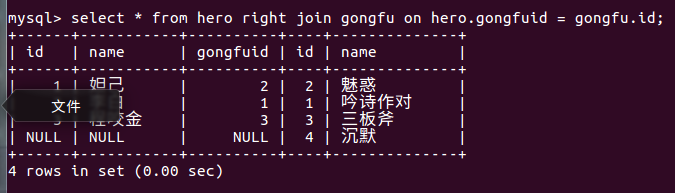
语法:select 字段 from 表1 right join/ right outer join 表2 on 表1.字段1 = 表2.字段2;
select * from hero right outer join gongfu on hero.gongfuid = gongfu.id;
select * from hero right join gongfu on hero.gongfuid = gongfu.id;
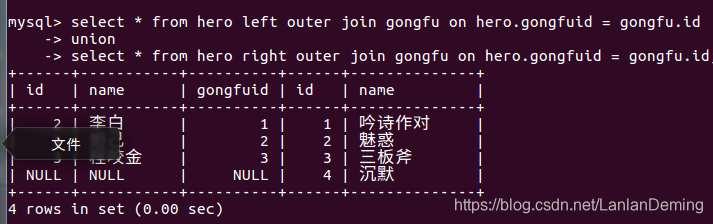
3.4 全连接查询
没有关键字 union 并集 123 124 1234
select * from hero left outer join gongfu on hero.gongfuid = gongfu.id;
select * from hero right outer join gongfu on hero.gongfuid = gongfu.id;
select * from hero left outer join gongfu on hero.gongfuid = gongfu.id
union
select * from hero right outer join gongfu on hero.gongfuid = gongfu.id;
3.5 自连接
意义:自连接是一种特殊的连接
select * from 左表 join 右表 on 左表.字段 符号 右表.字段;
在自连接中,左表和右表是同一个表, 根据连接查询两个表中的数据
select * from 表 表1 join 表 表2 on 表1.字段 符号 表2.字段
areas 中的数据
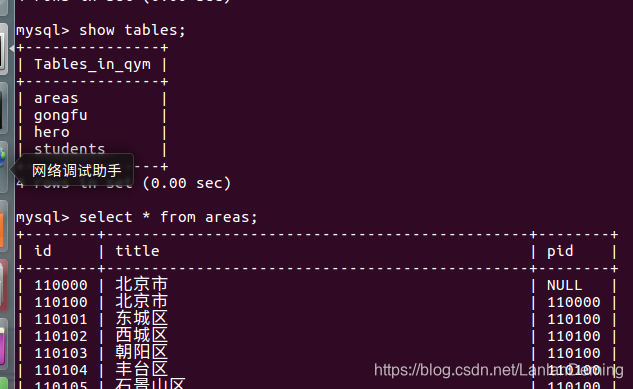
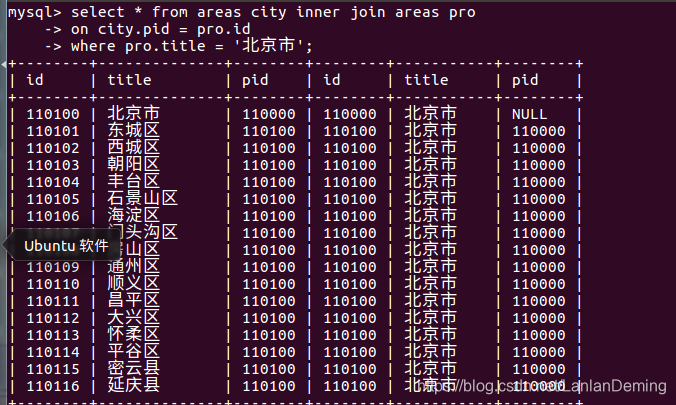
# 查询北京市下属的所有机构
select * from areas city inner join areas pro
on city.pid = pro.id
where pro.title = '北京市';
4. 子查询
4.1 子查询的介绍:
在一个 select 语句中, 嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句, 外部那个select 语句则成为主查询
4.2 主查询和子查询的关系
- 1.子查询是嵌入到主查询中的
- 2.子查询是辅助主查询的,要么充当条件, 要么充当数据源
- 3.子查询是可以独立存在的语句, 是一条完整的select 语句
语法:select语句-主查询(select 语句-子查询)
4.3分类: 标量, 行, 列 子查询
1.标量子查询
子查询返回的结果是一个值
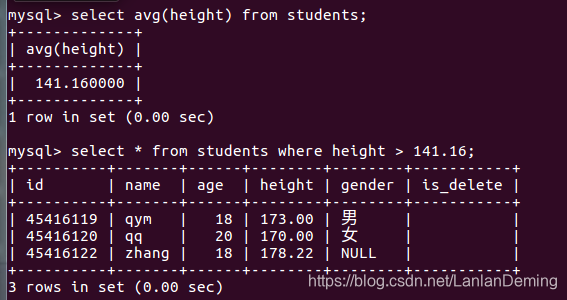
# 查询班级中 身高高于平均身高的同学信息
# 可以先求出平均升高 在使用平均身高的结果求出问题
select avg(height) from students;
select * from students where height > 141.16;
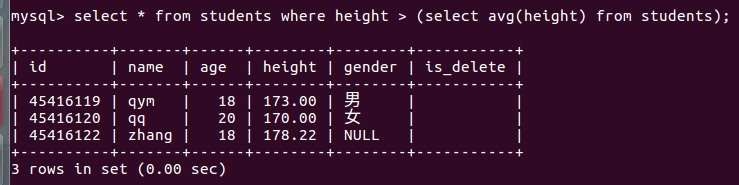
# 使用标量子查询
select * from students where height > (select avg(height) from students);
2.行子查询
子查询返回的结果是 行值
# 求班级中身高最高并且年龄最大的同学信息
select * from students where (height,age)=(select max(height),max(age)) from students);
表中没有尴尬了

3.列子查询
子查询返回的结果是列值
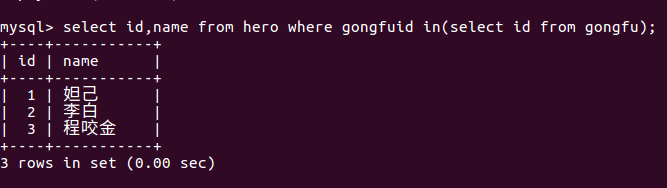
# 查询技能在技能表中能够找到的英雄 id , 名称
select id,name from hero where gongfuid in(select id from gongfu);
5. 外键约束
作用: A表中a 字段引用来自B表的b 字段的值, 把a定义为外键, a字段取值收到b字段取值的约束.
在插入和更新数据的时候, 可以防止数据库中无效数据的插入.
1.创建
需要注意 已有数据需要满足约束 否则报错
alter table A表名 add foreign key(a字段) references B表名
alter table hero add foreign key(gongfuid)references gongfu(id);
# 验证外键约束意义 报错
update hero set gongfuid = 20 where id = 4;
2.查看 外键约束名称
show create table hero;

3.删除
语法:alter table A表 drop foreign key 外键约束名称
alter table hero drop foreign key hero_ibfk_1;
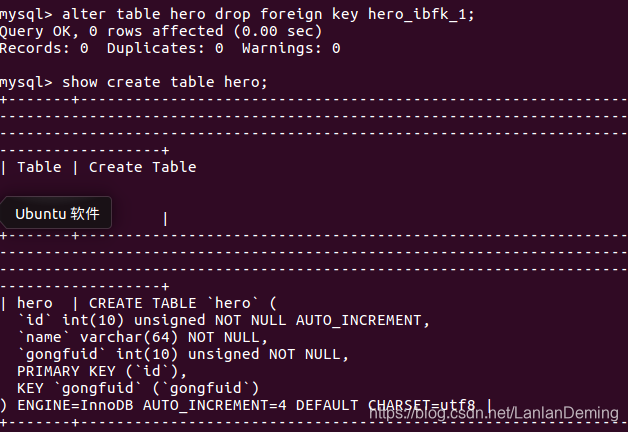
6 数据库设计之三范式
6.1 三范式的介绍
范式: 对设计数据库提出一些规范, 目前有迹可循的共有8中范式, 一般遵守3范式即可.
- 第一范式(1NF): 强调的是列的原子性, 即列不能够再分成其他几列.
- 第二范式(2NF): 满足1NF, 另外包含两部分内容, 一是表必须有一个主键; 二是非主键字段必须完全依赖于主键, 而不能只依赖于主键的一部分.
- 第三范式(3NF): 满足2NF,另外非主键必须直接依赖于主键, 不能存在传递依赖.即不能存在: 非主键列 A 依赖于非主键列 B, 非主键列B依赖于主键的情况.
6.2 E-R模型的介绍
E-R模型即实体-关系模型, E-R 模型就是描述数据库存储数据的结构模型.
E-R 模型的效果图:
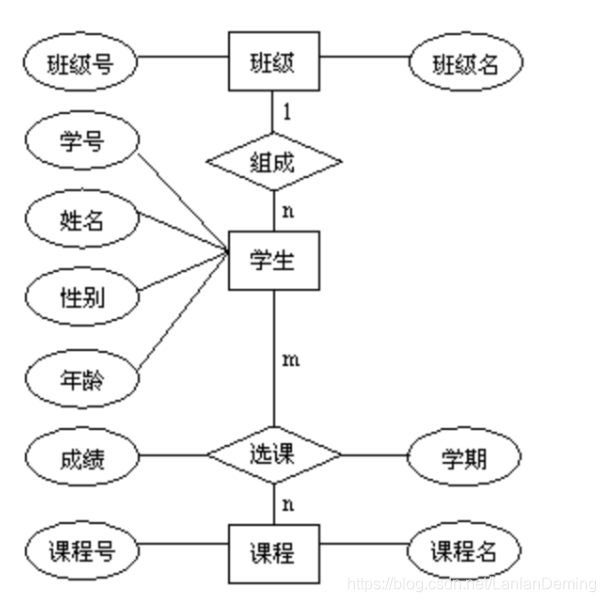
说明:
- 实体: 用矩形表示,并标注实体名称
- 属性: 用椭圆表示,并标注属性名称
- 关系: 用菱形表示,并标注关系名称
一对一关系:
- 关系也是一种数据, 需要通过一个字段存储在表中
- 1对1关系中, 在表A或者表B中创建一个字段, 存储另一个表的主键值
- 1:1
一对多关系:
- 1对多关系, 在多的一方表(学生表)中创建一个字段,存储班级表的主键值
- 1:n
多对多关系:
- 多对多关系, 新建一张表C, 这个标志有两个字段,一个用于存储A的主键值, 一个用于存储B的主键值
- m:n
7. sql执行顺序
主要了解 关键字书写顺序,运行顺序()
(8)SELECT (9)DISTINCT<select_list>
(1)FROM <left_table>
(2)<join_type>JOIN<right_table>
(3)ON <join_condition>
(4)WHERE <where_condition>
(5)GROUP BY <group_by_list>
(6)WITH {CUBE|ROLLUP}
(7)HAVING <having_condition>
(10)ORDER BY<order_by_list>
(11)LIMIT <limit_number>














 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









