







redis中其他几种数据类型:
【List类型使用及底层结构】
【String类型使用及底层结构】
【set类型使用及底层结构】
【hash类型使用及底层结构】
一、基本用法
Zset是有序集合,它在set的基础上加了一个值score称为权重,可以通过score进行排序。
#添加元素 zadd
127.0.0.1:6379> zadd myzset 1 one #添加一个值one,它的score为1
(integer) 1
127.0.0.1:6379> zadd myzset 2 two 3 three #添加多个值
(integer) 2
127.0.0.1:6379> zrange myzset 0 -1
1) "one"
2) "two"
3) "three"
#删除元素 zrem
127.0.0.1:6379> zrange salary 0 -1
1) "xiaoli"
2) "xiaobai"
3) "xiaoming"
127.0.0.1:6379> zrem salary xiaoli
(integer) 1
127.0.0.1:6379> zrange salary 0 -1
1) "xiaobai"
2) "xiaoming"
#查看集合中有多少元素 zcard
127.0.0.1:6379> zcard salary
(integer) 2
127.0.0.1:6379>
#查看集合中某一区间内有多少元素 zcount
127.0.0.1:6379> zrevrange salary 0 -1 withscores
1) "xiaoming"
2) "2500"
3) "xiaobai"
4) "2000"
5) "xiaohei"
6) "1500"
127.0.0.1:6379> zcount salary 1000 2000 #1000表示区间起始位置,2000表示区间结束位置
(integer) 2
#对集合进行排序 zrangebyscore
#zrangebyscore key min max 从min到max由小到大排序
127.0.0.1:6379> zadd salary 2500 xiaoming 2000 xiaobai 1500 xiaoli
(integer) 3
127.0.0.1:6379> zrangebyscore salary -inf +inf #-inf 和 +inf表示负无穷-正无穷升序排序.
1) "xiaoli" #可以任意添加范围
2) "xiaobai"
3) "xiaoming"
127.0.0.1:6379> zrange salary 0 -1 #zrange也可以将salary中的元素从小到大排序!
1) "xiaoli"
2) "xiaobai"
3) "xiaoming"
127.0.0.1:6379> zrangebyscore salary -inf 2000 withscores #排序查询时带有score的值
1) "xiaoli"
2) "1500"
3) "xiaobai"
4) "2000"
#zrevrange key 0 -1 #从大到小排序
127.0.0.1:6379> zrange salary 0 -1 withscores
1) "xiaohei"
2) "1500"
3) "xiaobai"
4) "2000"
5) "xiaoming"
6) "2500"
127.0.0.1:6379> zrevrange salary 0 -1 withscores
1) "xiaoming"
2) "2500"
3) "xiaobai"
4) "2000"
5) "xiaohei"
6) "1500"
二、底层结构
在redis3.0之前,Zset底层使用的是压缩列表和跳表,之后使用的是跳表和listpack。
1.跳表
(1)结构设计
链表在查找元素的时候,需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表,这样的好处是能快读定位数据。
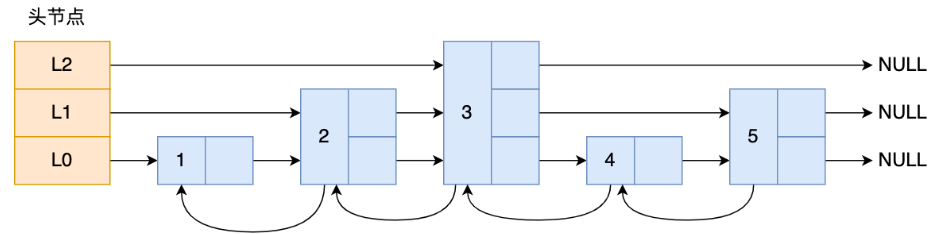
这是一个层级为3的跳表,其中:
- L0 层级共有 5 个节点,分别是节点1、2、3、4、5;
- L1 层级共有 3 个节点,分别是节点 2、3、5;
- L2 层级只有 1 个节点,也就是节点 3 。
当查找元素时就是在多个层级上跳来跳去,最后定位到元素。数据量很大时,跳表的查找复杂度就是 O(logN)。
跳表由zskiplistNode和zskiplist两个结构定义,其中zskiplistNode结构用于表示跳跃表节点,而zskiplist结构则用于保存跳跃表节点的相关信息,比如节点的数量,以及指向表头节点和表 尾节点的指针等等。
zskiplistNode:
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后向指针保存的是该节点的前一个节点,是为了方便从跳表的尾节点开始访问节点
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针(下一个节点)和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
//span为跨度,跨度用来记录两个节点之间的距离
unsigned long span;
} level[];
} zskiplistNode;
level 数组中的每一个元素代表跳表的一层,也就是由 zskiplistLevel 结构体表示,比如 leve[0] 就表示第一层。

zskiplist:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
其中包含了:
- 跳表的头尾节点,便于在O(1)时间复杂度内访问跳表的头节点和尾节点;
- 跳表的长度,便于在O(1)时间复杂度获取跳表节点的数量;
- 跳表的最大层数,便于在O(1)时间复杂度获取跳表中层高最大的那个节点的层数量;
(2)查询过程
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
- 如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
- 如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
eg.
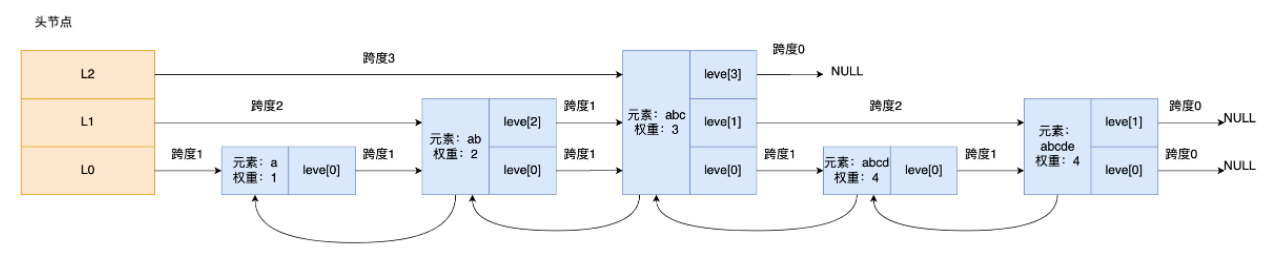
如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
-
先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
-
但是该层上的下一个节点是空节点,于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
-
「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
-
「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
(3)跳表节点层数设置
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)。
但是redis中,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况,而是靠生成随机数来实现的。
跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。
相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。
2.listpack
listpack的目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
(1)结构设计

listpack 头包含两个属性,分别记录了 listpack 总字节数和元素数量。
每个 listpack 节点结构如下:

- encoding,定义该元素的编码类型,会对不同长度的整数和字符串进行编码;
- data,实际存放的数据;
- len,encoding+data的总长度;
listpack中没有了prevlen记录前一个节点的长度,而是用len记录当前节点长度,从而避免连锁更新的问题。















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









