







优化方法介绍一
基本都是参考文献 1
梯度下降变种
有三种梯度下降变种,区别在于使用多少训练数据
批梯度下降(Batch gradient descent)
使用整个数据进行计算
Vanilla gradient descent, aka batch gradient descent
θ
=
θ
−
η
∗
∇
θ
J
(
θ
)
\theta=\theta-\eta *\nabla_{\theta} J(\theta)
θ=θ−η∗∇θJ(θ)
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
批梯度下降对于凸函数能够收敛到全局最优,非凸函数局部最优
随机梯度下降(Stochastic gradient descent)
随机梯度下降,顾名思义,下降方向不确定,所谓的不确定是指相对于批下降而言,因为样本的随机性,每次更新梯度的方向并不一定是全局最小或者局部最小的方向。
θ
=
θ
−
η
∗
∇
θ
J
(
θ
;
x
(
i
)
;
y
(
i
)
)
\theta =\theta -\eta*\nabla_{\theta} J(\theta;x^{(i)};y^{(i)})
θ=θ−η∗∇θJ(θ;x(i);y(i))
批处理只有计算完全部数据之后才会更新梯度,而随机梯度每一个样本都会更新,所以随机梯度一般会比批梯度收敛快并且可以用于在线更新。然而由于随机梯度的随机性会导致不容易收敛到局部最优所以需要设置learning rate decay。
Mini-batch gradient descent
介于随机梯度和批梯度直接,用的最多
θ
=
θ
−
η
∗
∇
θ
J
(
θ
;
x
(
i
:
i
+
n
)
;
y
(
i
:
(
i
+
n
)
)
)
\theta=\theta - \eta*\nabla_{\theta}J(\theta;x^{(i:i+n)};y^{(i:(i+n))})
θ=θ−η∗∇θJ(θ;x(i:i+n);y(i:(i+n)))
现在的SGD大都是指min-batch 版本的SGD,公式也会把
(
i
:
i
+
n
)
(i:i+n)
(i:i+n)省略
Gradient descent optimization algorithms
主要是解决梯度下降的一些优化方法
动量
主要是引入了一个动量变量
v
t
=
γ
v
t
−
1
+
η
∗
∇
θ
J
(
θ
)
v_{t}=\gamma v_{t-1}+\eta*\nabla_{\theta}J(\theta)
vt=γvt−1+η∗∇θJ(θ)
θ
=
θ
−
v
t
\theta=\theta-v_{t}
θ=θ−vt
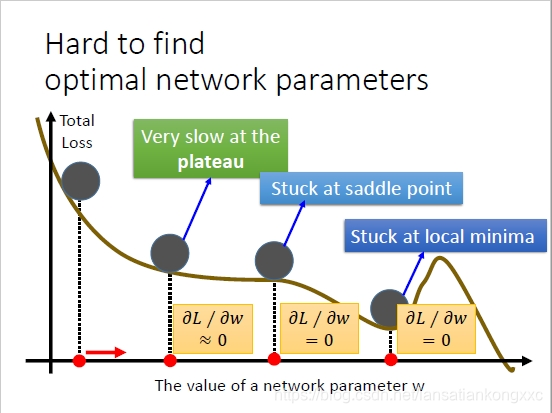
对于一些loss等值线是曲线的函数,很多时候光靠SGD收敛很慢,而且容易陷入局部极小值点。
动量的引入就是为了加快学习过程,特别是对于高曲率、小但一致的梯度,或者噪声比较大的梯度能够很好的加快学习过程。动量的主要思想是积累了之前梯度指数级衰减的移动平均(前面的指数加权平均)1
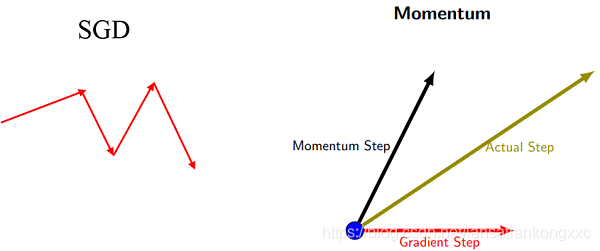
动量的引入就是积累之前的梯度方向,类似将批梯度和随机梯度做了加权平均
Nesterov accelerated gradient
Nesterov梯度加速,Nesterov是个人名。和动量梯度下降非常相似
v
t
=
γ
v
t
−
1
+
η
∗
∇
θ
J
(
θ
−
γ
v
t
−
1
)
v_{t}=\gamma v_{t-1}+\eta*\nabla_{\theta}J(\theta-\gamma v_{t-1})
vt=γvt−1+η∗∇θJ(θ−γvt−1)
θ
=
θ
−
v
t
\theta=\theta-v_{t}
θ=θ−vt
区别在于一个是使用了当前的梯度,一个是使用了历史参数进行更新之后的梯度,相对来说会有一个使用历史参数的结果的修正作用,想当与向前看了一步,动量发只用当前的梯度不会有这种作用














 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









