







I.JVM进程的生命周期
-
JVM实例的生命周期和java程序的生命周期保持一致,即一个新的程序启动则产生一个新的JVM进程实例,程序结束则JVM进程实例伴随着消失。那么程序启动和程序终止就是JVM实例生命周期的两个边界,两个边界点可以这么理解:一个拥有程序入口(main函数)的class在执行main方法时,相应的JVM就被创建了(即JVM生命周期的起点),当由此main函数启动的所有非守护线程都终止时,JVM即退出(JVM实例生命周期的终点)。举个实例来描述一下JVM实例的生命周期:
(1) JVMInstance.java
public class JVMInstance { public static void main(String[] args) { System.out.println("hello world!"); } }(2) javac JVMInstance.java 编译源码生成class文件
(3) java JVMInstance
在用java 命令执行编译好的字节码文件时,java命令会调用java launcher来创建JVM实例,而java.exe的源代码在jdk/src/share/bin/java.c定义(可以在openJDK中看到其中的源代码)。 java.c中主要包含了两个主要的函数:int main(int argc, char ** argv); int JNICALLJavaMain(void * _args);其中主要完成的功能是新建JVM实例进程,实例化一些守护线程,包括监视器线程(WatcherThread),编译器线程(Compiler Thread),GC线程(GC Thread)。(具体源代码可以细扣一下,有现成的研究大家也分享一下) //TODO ps:学习一下java.c 源代码
II.JVM内存模型
在内存结构上每个JVM实例都有自己的一套内存模型(即:堆,方法区,方法栈,本地方法栈,程序技术器),当JVM实例创建时内存模型也随之创建,没猜错的话java.c的这段代码就是用来分配JVM实例内存的:
{
int i;
original_argv = (char**)JLI_MemAlloc(sizeof(char*)*(argc+1));
for(i = 0; i < argc+1; i++) {
original_argv[i] = argv[i];
}
}
CreateExecutionEnvironment(&argc, &argv,
jrepath, sizeof(jrepath),
jvmpath, sizeof(jvmpath),
original_argv);
...
JVM实例的内存模型结构入下图(参考《深入理解java虚拟机》):  上图中标出了红框和绿框,其中红框代表在一个JVM进程实例内所有线程共享的内存模型区域,绿框表示线程内存数据隔离的区域,即方法区和堆中的数据JVM进程内线程共享,栈和程序计数器每个线程有自己的一套。(看过一些博客把方法区也画入了堆内存结构中,感觉不是很合理,虽然java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-heap(非堆))。方法区主要存储:类加载的信息,常量,静态变量,即时编译器编译后的代码等数据。堆内存又分为 Yong、Tenured、Perm。虚拟机栈是执行普通方法是需要用的,本地方法栈就是执行本地方法栈的时候用的。程序计数器就是辅助程序执行用的,记录程序指令指针。 JVM执行引擎是JVM实例进程中的一个线程,用来执行字节码指令的。
上图中标出了红框和绿框,其中红框代表在一个JVM进程实例内所有线程共享的内存模型区域,绿框表示线程内存数据隔离的区域,即方法区和堆中的数据JVM进程内线程共享,栈和程序计数器每个线程有自己的一套。(看过一些博客把方法区也画入了堆内存结构中,感觉不是很合理,虽然java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-heap(非堆))。方法区主要存储:类加载的信息,常量,静态变量,即时编译器编译后的代码等数据。堆内存又分为 Yong、Tenured、Perm。虚拟机栈是执行普通方法是需要用的,本地方法栈就是执行本地方法栈的时候用的。程序计数器就是辅助程序执行用的,记录程序指令指针。 JVM执行引擎是JVM实例进程中的一个线程,用来执行字节码指令的。
III.JVM内存垃圾回收机制及常用垃圾回收器
(1)分代回收:在运行的程序中,会创建大量端生命周期的对象和小部分长生命周期的对象。对于短生命周期对象,垃圾回收线程就需要频繁的检测释放,对于长周期的对象垃圾回收检测线程探测频率就可以少一点。为了满足这种需求SUN的JVM内存是分代管理,分代回收的(说白了分代管理就是为了分代回收,哪天如果不需要分代回收了,那分代管理机制也就不需要了,我个人觉得哈)。
(2)常用的垃圾回收算法:
标记清除算法: 概述:回收过程分两个阶段,即先“标记” 再 “清除”,首先GC线程根据根搜索算法以及回收判定策略,判断对象是否需要被回收,将需要被回收的对象全都标记出来,然后统一回收掉。这种算法是比较基础的算法,后续的算法基本是基于这种算法的。 主要缺点:一个是效率问题,标记和清除过程效率都不高;另外一个是空间问题,标记清除之后会产生不连续的内存碎片(如果空间碎片太多,当分配一个大对象的时候,因为找不到一块合适的内存区域,就会提前出发一次GC操作)。
复制算法: 复制算法基本思想就是,将内存分成大小相等的两块,每次只使用其中的一块。当其中一块内存用完了,就将活着的对象按序摆放到另外一块内存中,然后将另一块内存清理掉。 优缺点:优点就是与标记清除算法相比,效率明显提高了,并且不会产生内存碎片。缺点也是显而易见就是内存需求更大了,每次都需要有一块内存闲置。(ps:现在的商业虚拟机都采用这种收集算法回收新生代,例如:SUN JDK1.3.1版本启用的HotSpot虚拟机)
标记整理算法: 标记整理算法主要分为算个阶段,首先将要清理的对象标记出来和标记清除的第一阶段一样,然后将有效的对象向一端移动(类似于我们有win7优化到时整理内存碎片的效果),最后将有效对象边界以外的对象全部回收掉。 优缺点:有点就是和标记清除算法相比减少了内存碎片,和复制算法相比提高内存利用率。 缺点:效率较低。
(3)常用的垃圾收集器:
- Serial收集器:单线程收集器,只会启动一条线程进行内存回收工作,在回收的过程中,必须暂停其他所有的工作线程。serial是一个比较原始的收集器,运行在Server端的JVM已经不再使用Serial,不过对于运行在Client端的JVM是一个很好的选择(单线程嘛,意味着没有线程切换开销)。Serial对于Yong区采用的是复制算法,对于Tenured采用的是标记整理算法。
- ParNew收集器: ParNew收集器是Serial收集器的多线程版本,对于收集算法以及控制参数Serial和ParNew一样,ParNew是运行在Server模式下的JVM的首选的新生代收集器,主要原因是除了ParNew能和Serial配合使用外,只有ParNew能和CMS协同工作。
- Parallel Scavenge收集器:多线程的新生代收集器,采用的复制算法,看上去和ParNew一样,但专注点不同,ParNew专注于在收集过程中缩短用户线程的停顿时间,而它专注于达到一个可控的吞吐量(吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间))。
- Serial Old收集器:Serial的老年代版本,采用的是标记整理算法,现在跑Server端JVM进程实例不经常使用的收集器,比较古老。
- Parallel Old收集器:Parallel Scavenge的老年代版本,使用多线程和标记-整理算法。Paralle Old出现之后就可以和Parallel Scavenge配合使用了。
- CMS收集器:CMS(Concurrent Mark Sweep)收集器是一种以获取最短停顿时间为目标的收集器,目前在市场上使用的占比很大。它是一款老年代收集器,采用的是标记-清除算法。它在清理过程中主要包含4个阶段,分别是初始标记,并发标记,重新标记,并发清除。其中只有初始标记和重新标记需要停顿用户线程,在并发标记和并发清除阶段,用户线程和回收器线程可以共同运行(将整个回收过程分成好多段,以达到减少停顿用户线程的目的)。
- G1收集器是JDK1.7提供的收集器,G1基于标记-整理算法(没有内存碎片),试用于新生代和老年代。它改变了收集的策略,不在针对新生代和老年代整个区域进行收集,而是把新生代或老年代划分成多个单元格,针对每个单元格的使用程度,对每个单元格进行收集,属于算法的优化和突破。
下面这个图不错的表达了各个收集器使用的分代区域: 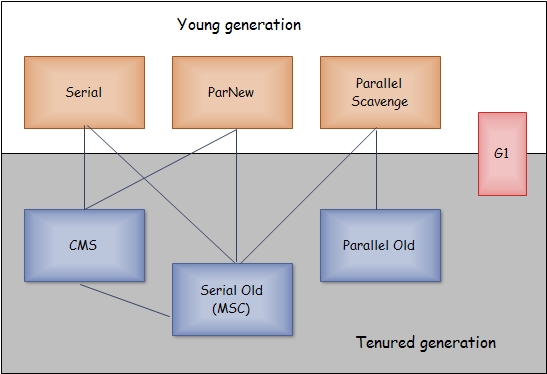
IV.JVM垃圾回收日志结构分析及常用的命令
我们在我们Server的gc log上经常看到下面的这个日志。  总结一下各个字段表达的是什么意思: Young GC:
总结一下各个字段表达的是什么意思: Young GC: 
Full GC: 















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









