







disruptor—master源码分析
目录
整体结构
disruptor—master源码:https://github.com/fsaintjacques/disruptor–/tree/master
disruptor—master/
├── acinclude.m4
├── configure.ac
├── disruptor
│ ├── batch_descriptor.h
│ ├── claim_strategy.h
│ ├── event_processor.h
│ ├── event_publisher.h
│ ├── exception_handler.h
│ ├── exceptions.h
│ ├── interface.h
│ ├── ring_buffer.h
│ ├── sequence_barrier.h
│ ├── sequence.h
│ ├── sequencer.h
│ ├── utils.h
│ └── wait_strategy.h
├── Makefile.am
├── perf
│ ├── Makefile.am
│ ├── one_publisher_to_one_unicast_throughput_test.cc
│ └── one_publisher_to_three_pipeline_throughput_test.cc
├── README
├── test
│ ├── Makefile.am
│ ├── ring_buffer_test.cc
│ ├── sequencer_test.cc
│ └── support
│ ├── long_event.h
│ └── stub_event.h
└── TODO
disruptor源码文件主要可以分为四部分:
- publisher相关部分:event_publisher、sequencer、claim_strategy、batch_descriptor
- Consumer相关部分:event_processor、sequence_barrier、wait_strategy
- 公共部分:ring_buffer、sequence
- 辅助部分:exceptions、exception_handler、utils、interface
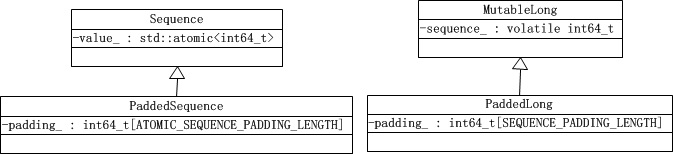
Sequence
#define ATOMIC_SEQUENCE_PADDING_LENGTH \
(CACHE_LINE_SIZE_IN_BYTES - sizeof(std::atomic<int64_t>))/8- class Sequence : a sequence counter that can be tracked across threads.
- class PaddedSequence : Cache line padded sequence counter.
#define SEQUENCE_PADDING_LENGTH \
(CACHE_LINE_SIZE_IN_BYTES - sizeof(int64_t))/8- class MutableLong : Non-atomic sequence counter.
- class PaddedSequence : Cache line padded non-atomic sequence counter.
总结:class Sequence 和 class MutableLong 都只是对一个计数值的封装,前者使用 atomic 实现线程安全地读写,后者不是线程安全的。class PaddedSequence 和 class PaddedSequence 都只是为了对前两者实现缓存行填充。
Sequencer
- class Sequencer : Coordinator for claiming sequences for access to a data structures while tracking dependent Sequences.
class Sequencer {
public:
Sequencer(int buffer_size,
ClaimStrategyOption claim_strategy_option,
WaitStrategyOption wait_strategy_option);
~Sequencer();
void set_gating_sequences(const std::vector<Sequence*>& sequences);
ProcessingSequenceBarrier* NewBarrier(const std::vector<Sequence*>& sequences_to_track);
BatchDescriptor* NewBatchDescriptor(const int& size);
int buffer_size();
int64_t GetCursor();
bool HasAvalaibleCapacity();
int64_t Next();
BatchDescriptor* Next(BatchDescriptor* batch_descriptor);
int64_t Claim(const int64_t& sequence);
void Publish(const int64_t& sequence);
void Publish(const BatchDescriptor& batch_descriptor);
void ForcePublish(const int64_t& sequence);
Sequence* GetSequencePtr();
private:
// Helpers
void Publish(const int64_t& sequence, const int64_t& batch_size);
// Members
const int buffer_size_;
PaddedSequence cursor_; // sequence points to the write position.
std::vector<Sequence*> gating_sequences_; // sequences point to all consumers' position.
ClaimStrategyInterface* claim_strategy_;
WaitStrategyInterface* wait_strategy_;
DISALLOW_COPY_AND_ASSIGN(Sequencer);
};Sequencer 定义了 publisher 应该怎样往 Ring Buffer 中写入数据。其中 cursor_ 指向当前写入到的位置,初始值为-1。gating_sequences_ 包含了这个 Ring Buffer 所有的 Consumer 的当前的读取位置。 取名 gating sequences,有点守门员的意思,让 publisher 不要越过 Consumers 当前读取位置。
Claim Strategy
// 定义 publisher 按照哪种策略来写数据
// Optimised strategy can be used when there is a single publisher thread
// claiming {@link AbstractEvent}s.
class SingleThreadedStrategy : public ClaimStrategyInterface {
public:
SingleThreadedStrategy(const int& buffer_size) :
buffer_size_(buffer_size),
sequence_(kInitialCursorValue),
min_gating_sequence_(kInitialCursorValue) {}
virtual int64_t IncrementAndGet(
const std::vector<Sequence*>& dependent_sequences) {
int64_t next_sequence = sequence_.IncrementAndGet(1L);
WaitForFreeSlotAt(next_sequence, dependent_sequences);
return next_sequence;
}
virtual int64_t IncrementAndGet(const int& delta,
const std::vector<Sequence*>& dependent_sequences) {
int64_t next_sequence = sequence_.IncrementAndGet(delta);
WaitForFreeSlotAt(next_sequence, dependent_sequences);
return next_sequence;
}
virtual bool HasAvalaibleCapacity(
const std::vector<Sequence*>& dependent_sequences) {
int64_t wrap_point = sequence_.sequence() + 1L - buffer_size_;
if (wrap_point > min_gating_sequence_.sequence()) {
int64_t min_sequence = GetMinimumSequence(dependent_sequences);
min_gating_sequence_.set_sequence(min_sequence);
if (wrap_point > min_sequence)
return false;
}
return true;
}
virtual void SetSequence(const int64_t& sequence,
const std::vector<Sequence*>& dependent_sequences) {
sequence_.set_sequence(sequence);
WaitForFreeSlotAt(sequence, dependent_sequences);
}
virtual void SerialisePublishing(const int64_t& sequence,
const Sequence& cursor,
const int64_t& batch_size) {}
private:
SingleThreadedStrategy();
/* 重点:
* $sequence: 下一个写入的位置,不断累加的值。
* $dependent_sequences: class Sequencer 中定义的 gating_sequences_。
* 函数在这里循环等待,直到发现 $sequence 这个位置可以允许写入数据了。
* GetMinimumSequence(dependent_sequences) 返回 dependent_sequences 中 sequence 最小的值。
* 已知 min_gating_sequence_ 初始值为 -1, 假设 buffer_size_=2,publisher 开始调用该函数:
* 1st:sequence=0,wrap_point=0-2=-2, -2<=-1, return.
* 2nd: sequence=1,wrap_point=1-2=-1, -1<=-1, return.
* 3rd: sequence=2,wrap_point=2-2=0, 0>-1, judge:
* 假设此时 GetMinimumSequence(dependent_sequences) 返回 0,即
* consumer 只消费了 buffer 中一个数据,Then:
* wrap_point==0 <= 0, return.
* 4th: sequence=3,wrap_point=3-2=1, 1>-1, judge:
* 假设此时 GetMinimumSequence(dependent_sequences) 依然返回 0
* wrap_point==1 > 0, this_thread::yield(),
* 即等待 Consumer 消费后修改了它的 sequence 后 publisher 才能继续写。
*/
void WaitForFreeSlotAt(const int64_t& sequence,
const std::vector<Sequence*>& dependent_sequences) {
int64_t wrap_point = sequence - buffer_size_;
if (wrap_point > min_gating_sequence_.sequence()) {
int64_t min_sequence;
while (wrap_point > (min_sequence = GetMinimumSequence(dependent_sequences))) {
std::this_thread::yield();
}
}
}
const int buffer_size_;
PaddedLong sequence_;
PaddedLong min_gating_sequence_;
DISALLOW_COPY_AND_ASSIGN(SingleThreadedStrategy);
};Sequence Barrier
// EventProcessor(即 Consumer)的辅助类,目的是返回接下来哪些位置上的数据是可以用了。
class ProcessingSequenceBarrier : SequenceBarrierInterface {
public:
ProcessingSequenceBarrier(WaitStrategyInterface* wait_strategy,
Sequence* sequence,
const std::vector<Sequence*>& sequences);
/* 重点: 等待位置 $sequence 是否可用。
* @return the sequence that is available which may be greater than the
* requested sequence.
*/
virtual int64_t WaitFor(const int64_t& sequence);
/* 同上,增加一个等待超时时间。
*/
virtual int64_t WaitFor(const int64_t& sequence,
const int64_t& timeout_micros);
virtual int64_t GetCursor() const;
virtual bool IsAlerted() const;
virtual void Alert();
virtual void ClearAlert();
virtual void CheckAlert() const;
private:
WaitStrategyInterface* wait_strategy_;
Sequence* cursor_; // class Sequencer 中的 cursor_
/* 由构造函数参数 $sequences 赋值。
* 这里的 dependent_sequences_ 与 Claim Strategy 定义的 dependent_sequences 不同,
* 后者是 class Sequencer 中的 gating_sequences_ 的含义,前者指的是该对象辅助的
* EventProcessor 依赖的一些 Sequence。这些 Sequence 有可能是其它
* EventProcessor 的 Sequence,即这个 EventProcessor 依赖于其它的 EventProcessor。
*/
std::vector<Sequence*> dependent_sequences_;
std::atomic<bool> alerted_;
};Wait Strategy
// 为 Sequence Barrier 定义具体的等待策略。
// Blocking strategy that uses a lock and condition variable for
// {@link Consumer}s waiting on a barrier.
// This strategy should be used when performance and low-latency are not as
// important as CPU resource.
class BlockingStrategy : public WaitStrategyInterface {
public:
BlockingStrategy() {}
virtual int64_t WaitFor(const std::vector<Sequence*>& dependents,
const Sequence& cursor,
const SequenceBarrierInterface& barrier,
const int64_t& sequence) {
int64_t available_sequence = 0;
// We need to wait.
if ((available_sequence = cursor.sequence()) < sequence) {
// acquire lock
std::unique_lock<std::recursive_mutex> ulock(mutex_);
while ((available_sequence = cursor.sequence()) < sequence) {
barrier.CheckAlert();
consumer_notify_condition_.wait(ulock);
}
} // unlock happens here, on ulock destruction.
if (0 != dependents.size()) {
while ((available_sequence = GetMinimumSequence(dependents)) < \
sequence) {
barrier.CheckAlert();
}
}
return available_sequence;
}
virtual int64_t WaitFor(const std::vector<Sequence*>& dependents,
const Sequence& cursor,
const SequenceBarrierInterface& barrier,
const int64_t& sequence,
const int64_t& timeout_micros) {
int64_t available_sequence = 0;
// We have to wait
if ((available_sequence = cursor.sequence()) < sequence) {
std::unique_lock<std::recursive_mutex> ulock(mutex_);
while ((available_sequence = cursor.sequence()) < sequence) {
barrier.CheckAlert();
if (std::cv_status::timeout == consumer_notify_condition_.wait_for(ulock,
std::chrono::microseconds(timeout_micros)))
break;
}
} // unlock happens here, on ulock destruction
if (0 != dependents.size()) {
while ((available_sequence = GetMinimumSequence(dependents)) \
< sequence) {
barrier.CheckAlert();
}
}
return available_sequence;
}
virtual void SignalAllWhenBlocking() {
std::unique_lock<std::recursive_mutex> ulock(mutex_);
consumer_notify_condition_.notify_all();
}
private:
std::recursive_mutex mutex_;
std::condition_variable_any consumer_notify_condition_;
DISALLOW_COPY_AND_ASSIGN(BlockingStrategy);
};Event Processor
template <typename T>
class BatchEventProcessor : public EventProcessorInterface<T> {
public:
BatchEventProcessor(RingBuffer<T>* ring_buffer,
SequenceBarrierInterface* sequence_barrier,
EventHandlerInterface<T>* event_handler,
ExceptionHandlerInterface<T>* exception_handler) :
running_(false),
ring_buffer_(ring_buffer),
sequence_barrier_(sequence_barrier),
event_handler_(event_handler),
exception_handler_(exception_handler) {}
virtual Sequence* GetSequence() { return &sequence_; }
virtual void Halt() {
running_.store(false);
sequence_barrier_->Alert();
}
virtual void Run() {
if (running_.load())
throw std::runtime_error("Thread is already running");
running_.store(true);
sequence_barrier_->ClearAlert();
event_handler_->OnStart();
T* event = NULL;
int64_t next_sequence = sequence_.sequence() + 1L;
while (true) {
try {
int64_t avalaible_sequence = \
sequence_barrier_->WaitFor(next_sequence);
while (next_sequence <= avalaible_sequence) {
event = ring_buffer_->Get(next_sequence);
event_handler_->OnEvent(next_sequence,
next_sequence == avalaible_sequence, event);
next_sequence++;
}
sequence_.set_sequence(next_sequence - 1L);
} catch(const AlertException& e) {
if (!running_.load())
break;
} catch(const std::exception& e) {
exception_handler_->Handle(e, next_sequence, event);
sequence_.set_sequence(next_sequence);
next_sequence++;
}
}
event_handler_->OnShutdown();
running_.store(false);
}
void operator()() { Run(); }
private:
std::atomic<bool> running_;
Sequence sequence_; // 该 processor 已经处理完成的位置
RingBuffer<T>* ring_buffer_;
SequenceBarrierInterface* sequence_barrier_;
EventHandlerInterface<T>* event_handler_;
ExceptionHandlerInterface<T>* exception_handler_;
DISALLOW_COPY_AND_ASSIGN(BatchEventProcessor);
};Event Publisher
template<typename T>
class EventPublisher {
public:
EventPublisher(RingBuffer<T>* ring_buffer) : ring_buffer_(ring_buffer) {}
void PublishEvent(EventTranslatorInterface<T>* translator) {
int64_t sequence = ring_buffer_->Next();
translator->TranslateTo(sequence, ring_buffer_->Get(sequence));
ring_buffer_->Publish(sequence);
}
private:
RingBuffer<T>* ring_buffer_;
};Ring Buffer
// Ring based store of reusable entries containing the data representing an
// event beign exchanged between publisher and {@link EventProcessor}s.
//
// @param <T> implementation storing the data for sharing during exchange
// or parallel coordination of an event.
template<typename T>
class RingBuffer : public Sequencer {
public:
// Construct a RingBuffer with the full option set.
//
// @param event_factory to instance new entries for filling the RingBuffer.
// @param buffer_size of the RingBuffer, must be a power of 2.
// @param claim_strategy_option threading strategy for publishers claiming
// entries in the ring.
// @param wait_strategy_option waiting strategy employed by
// processors_to_track waiting in entries becoming available.
RingBuffer(EventFactoryInterface<T>* event_factory,
int buffer_size,
ClaimStrategyOption claim_strategy_option,
WaitStrategyOption wait_strategy_option) :
Sequencer(buffer_size,
claim_strategy_option,
wait_strategy_option),
buffer_size_(buffer_size),
mask_(buffer_size - 1),
events_(event_factory->NewInstance(buffer_size)) {
}
~RingBuffer() {
delete[] events_;
}
// Get the event for a given sequence in the RingBuffer.
//
// @param sequence for the event
// @return event pointer at the specified sequence position.
T* Get(const int64_t& sequence) {
return &events_[sequence & mask_];
}
private:
// Members
int buffer_size_;
int mask_;
T* events_;
DISALLOW_COPY_AND_ASSIGN(RingBuffer);
};















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









