







1. 项目背景与意义
随着车辆保有量的不断增加,车牌识别技术成为了智能交通管理和车主身份认证的重要工具。车牌识别系统在交通监控、停车管理、道路收费等多个领域得到了广泛应用。由于不同地区车牌的样式、字体、颜色等差异,车牌识别的技术难度较大。因此,如何提高车牌识别的准确性与稳定性成为了技术研究的重点。
本项目基于 Python 的 Tkinter 和 OpenCV 库,设计并实现了一个简单的中国车牌识别系统。该系统可以实现车牌定位、字符分割、字符识别等功能,帮助用户快速识别车牌信息。
2. 项目目标
本项目的目标是通过简单的图形界面和算法实现车牌识别功能,帮助用户实现以下任务:
- 车牌定位:通过边缘检测和车牌颜色的定位方法,准确找到车牌所在区域。
- 车牌字符识别:利用 OpenCV 中的 SVM 算法对车牌字符进行识别,识别车牌上的字符。
- 简单界面展示:使用 Tkinter 实现简单的图形界面,方便用户操作和查看识别结果。
3. 技术栈
本项目使用了以下技术栈:
- Python 3.7:作为开发语言。
- OpenCV:图像处理库,用于车牌定位和字符识别。
- NumPy:用于图像处理中的数学计算。
- PIL (Pillow):用于图像加载与处理。
- Tkinter:用于开发图形界面,方便用户交互。
4. 算法设计与实现
该车牌识别系统的核心部分是车牌定位与字符识别。
- 车牌定位:首先通过边缘检测和车牌颜色定位车牌区域。车牌定位方法在
predict函数中实现,主要通过图像的边缘检测与色彩特征来识别车牌。 - 字符识别:车牌字符识别部分使用 OpenCV 提供的 SVM (支持向量机) 算法。SVM 是一种用于分类的监督学习算法,在此项目中,SVM 用于识别车牌中的每一个字符。训练数据来自 GitHub 上 EasyPR 项目的 C++ 版本,训练样本存储在
train文件夹下。由于训练数据有限,识别的准确性可能会受到影响,特别是对于第一个中文字符,误识别的概率较大。
5. 设计思路与流程
- 图像输入:通过 Tkinter 提供文件选择功能,用户可以加载车牌图像。
- 车牌定位:使用图像边缘检测和车牌颜色定位技术,确定车牌所在区域。
- 字符分割与识别:将车牌区域中的字符进行分割,并利用 SVM 进行识别。
- 输出结果:在界面上显示识别的车牌号码。
6. 项目实施计划
- 阶段一:项目需求分析与设计
- 完成项目需求的分析,确定功能模块,设计整体架构。
- 阶段二:算法实现与测试
- 实现车牌定位和字符识别算法,并在本地进行测试,调整参数以确保识别准确性。
- 阶段三:界面设计与开发
- 使用 Tkinter 设计简单的图形用户界面,使得用户可以方便地加载图像,查看识别结果。
- 阶段四:项目优化与文档撰写
- 完成系统的优化工作,提高识别精度,并撰写开发文档和开题报告。
开发文档
1. 项目概述
本项目实现了一个基于 OpenCV 和 Tkinter 的车牌识别系统。该系统使用图像处理技术来定位车牌,并通过支持向量机(SVM)算法对车牌上的字符进行识别。项目的目标是通过简单的图形界面和高效的算法实现车牌识别功能。
2. 技术栈
- Python 3.7:作为开发语言。
- OpenCV:用于图像处理,进行车牌定位与字符识别。
- NumPy:用于处理图像的数学计算。
- Pillow (PIL):用于图像的加载和处理。
- Tkinter:用于创建图形用户界面,供用户上传车牌图片并展示识别结果。
- SVM (支持向量机):用于车牌字符识别,基于 OpenCV 的 SVM 实现。
3. 项目结构
├── surface.py # 界面代码,使用 Tkinter 创建用户界面 ├── predict.py # 算法代码,负责车牌定位和字符识别 ├── config.js # 配置文件,包含车牌定位参数 ├── train/ # 存储训练数据集 │ ├── chars2.7z # 训练数据集压缩包 │ ├── charsChinese.7z # 训练数据集压缩包 │ └── svm.dat # 训练后的 SVM 模型数据 ├── test/ # 测试数据集 ├── img/ # 图片文件夹,包含测试用的车牌图像 ├── Screenshots/ # 项目界面截图 └── README.md # 项目说明文档
4. 环境配置与依赖
4.1 安装 Python 依赖
在项目开始之前,需要安装以下 Python 库:
pip install opencv-python numpy pillow
4.2 配置训练数据
训练数据已经包含在 train/ 文件夹中。如果需要重新训练模型,可以解压 chars2.7z 和 charsChinese.7z 文件,并使用 OpenCV 提供的训练方法训练新的 SVM 模型。
5. 算法实现
5.1 车牌定位 (predict.py)
车牌定位是整个识别流程的第一步。车牌定位主要包括边缘检测、颜色定位和轮廓提取。具体步骤如下:
- 图像预处理:
- 使用
cv2.cvtColor将输入的图像转换为灰度图像。 - 使用
cv2.GaussianBlur去除图像中的噪声。
- 边缘检测:
- 使用 Canny 边缘检测算法检测图像中的边缘,获取车牌区域的轮廓。
- 车牌颜色定位:
- 通过车牌的颜色特征,确定车牌的区域。在中国车牌中,车牌的底色通常是蓝色或黄色,因此通过颜色特征来辅助定位。
- 轮廓提取:
- 使用
cv2.findContours提取图像中的轮廓,找到符合车牌区域大小的轮廓。
- 车牌裁剪:
- 根据轮廓的坐标裁剪出车牌区域,方便后续字符识别。
5.2 字符识别
车牌字符识别部分使用了 OpenCV 的 SVM 算法进行字符分类。
- 字符分割:
- 对车牌区域进行二值化处理,将字符区域从背景中分割出来。
- 使用
cv2.findContours提取每个字符区域的轮廓,分割出每个字符。
- 特征提取:
- 对每个分割出的字符图像进行特征提取,通常包括图像的边缘、形状、尺寸等特征。
- SVM 分类:
- 使用训练好的 SVM 模型(
svm.dat和svmchinese.dat)对每个字符进行分类。 - 使用
cv2.ml.SVM_create()创建 SVM 模型,并加载训练好的模型。
- 字符识别:
- 对分割出的每个字符进行识别,输出车牌的号码。
5.3 参数调整
由于车牌图像的分辨率、色偏、车距等因素的影响,车牌定位算法的参数需要根据不同的图像进行调整。在 config.js 中提供了可调整的参数,包括:
- 图像分辨率
- 车牌颜色范围
- Canny 边缘检测的阈值等
6. 代码详解
6.1 surface.py - 图形界面代码
该文件使用 Tkinter 创建了一个简单的图形界面,包含:
- 一个文件选择按钮,允许用户上传图像。
- 显示上传图像并进行车牌识别。
- 显示识别结果。
6.2 predict.py - 算法代码
predict.py 文件实现了车牌定位和字符识别的核心算法。主要功能包括:
predict函数:该函数负责整个车牌识别过程,包括车牌定位、字符分割、字符识别等。- 使用 OpenCV 的
SVM进行字符分类,并通过cv2.findContours对字符进行分割。
6.3 config.js - 配置文件
该文件包含了车牌定位算法的可调参数,如车牌的颜色范围、Canny 边缘检测的阈值等。根据不同图像的特点,用户可以调整这些参数以获得更好的识别效果。
7. 使用说明
7.1 启动程序
- 首先,运行
surface.py文件,启动图形界面:
python surface.py
- 在界面中,点击文件选择按钮上传一张车牌图片。
- 上传成功后,点击“识别”按钮,程序将开始执行车牌识别。
- 程序会输出车牌号码,并显示识别结果。
7.2 调整参数
如果车牌定位或字符识别效果不理想,可以修改 config.js 文件中的参数来调整算法性能。常见的调整包括:
- 调整颜色范围,以适应不同背景色的车牌。
- 调整 Canny 边缘检测的阈值,以获得更精确的边缘信息。
8. 测试与验证
8.1 测试数据集
在 test/ 文件夹中提供了一些车牌图像,用于测试算法的准确性。用户可以通过修改 config.js 中的参数来适应不同类型的车牌图像。
8.2 测试结果
测试过程中,车牌定位与字符识别的准确性受图像分辨率、色偏、车距等因素的影响。通过适当调整参数,能够提高识别的准确性。
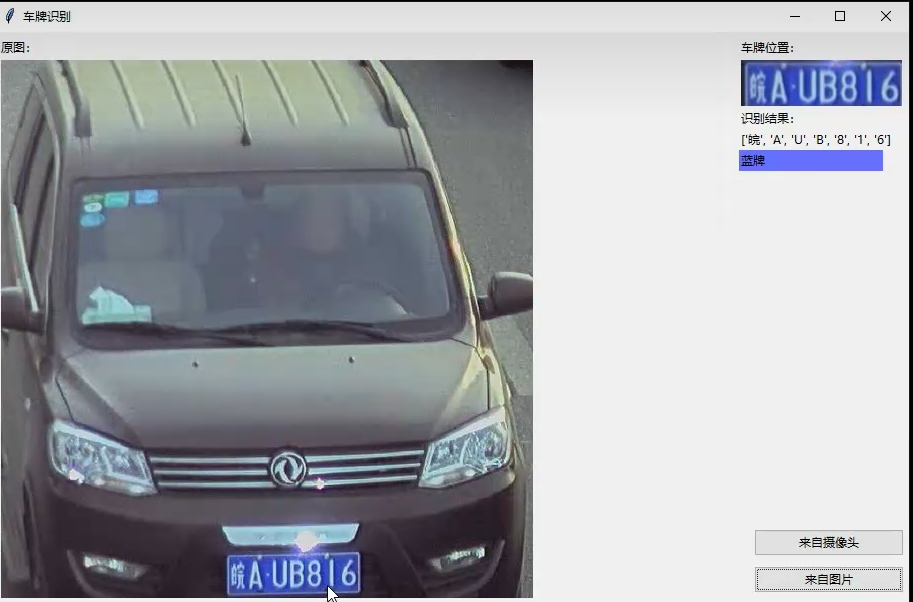
具体项目功能演示效果:
【【人工智能毕设推荐】基于python+opencv的中国车牌智能识别系统s2024085(项目演示+功能精讲)】 【人工智能毕设推荐】基于python+opencv的中国车牌智能识别系统s2024085(项目演示+功能精讲)_哔哩哔哩_bilibili



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











