






 文章讨论了Elasticsearch集群中单一主节点故障的解决方案,建议配置多个候选主节点以提高高可用性。同时,针对数据拷贝导致的问题,提出独立安装和配置,以及自定义ID与系统生成ID的权衡。
文章讨论了Elasticsearch集群中单一主节点故障的解决方案,建议配置多个候选主节点以提高高可用性。同时,针对数据拷贝导致的问题,提出独立安装和配置,以及自定义ID与系统生成ID的权衡。
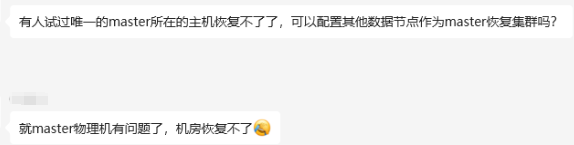
1、主节点设置1个,但是宕机了,集群咋办?
有人试过唯一的 master 所在的主机恢复不了了,可以配置其他数据节点作为 master 恢复集群吗?

1.1 问题描述
多节点集群,但只设置一个候选主节点,但这个主节点所在的物理机出故障了,怎么办?
1.2 问题拆解分析
第一直觉——这里的关键在于:咱们得有多个候选主节点。如果没有,这个没法再次选主。
在 Elasticsearch 中,集群的稳健性和高可用性是通过多个主节点候选(eligible master nodes)实现的,而不是依赖单个主节点候选。如果你的集群只配置了一个候选主节点,且该节点所在的物理机出现故障,这确实会导致问题,因为没有其他节点可以接替成为新的主节点。
问题提及的多节点集群中单一主节点候选的问题包含但不限于:
问题1:单点故障;
问题2:集群不可用;
问题3:数据完整性风险。
上述三个问题一脉相承,“一损俱损”。
1.3 解决方案探讨
1.3.1 配置其他数据节点作为主节点
在 Elasticsearch 集群中,任何节点理论上都可以被配置为主节点候选。如果集群当前只有一个主节点候选,并且该节点发生故障,可以尝试通过以下步骤恢复集群(这个得试验后给出具体结论)。
步骤1:更新配置——在其他数据节点的配置文件中(通常是 elasticsearch.yml),修改相关设置以使这些节点成为主节点候选。
步骤2:重启节点——对配置进行更改后,需要重启这些节点以应用新配置。
步骤3:监控和验证——重启节点后,监控集群状态,确保新的主节点被正确选举且集群恢复正常运行。
步骤2、步骤3的时间因数据量、集群规模而异,有可能非常长!
1.3.2 马后炮方案——配置多个候选主节点
集群规模足够大,也就是节点足够多时(比如大于6个),需要配置多个主节点候选主节点。
一般咱们建议至少配置三个符合主节点条件的节点。这样,即使一个节点发生故障,其他节点仍然可以参与主节点选举,确保集群的持续运行和数据的一致性。
从 Elasticsearch 7 开始,当主节点失效时,集群会自动进行新的主节点选举。如果有多个候选主节点,这个过程将更加顺利和迅速。
参见:
https://www.elastic.co/cn/blog/a-new-era-for-cluster-coordination-in-elasticsearch
1.4 集群的高可用性非小事
像类似上述问题,当然配置多个候选主节点是关键中的关键。与之同等重要的是,确保集群的高可用性,就是咱们的数据即便出现硬件配置故障,也不丢!
为保障集群的高可用性,咱们之前也讲过快照备份策略机制、定时快照SLM机制。我们要确保集群有恰当的故障转移和恢复策略,例如,定期快照和备份可以帮助在发生故障时快速恢复数据。
1.5 小结
总之,为了确保 Elasticsearch 集群的高可用性和稳定性,强烈推荐配置多个主节点候选,并且定期进行备份和快照。这样即使某个节点发生故障,集群也可以继续运行,减少了单点故障的风险。
2、拷贝一时爽,出问题难倒英雄汉!
2.1 一台机器两个集群,直接拷贝,启动报错!
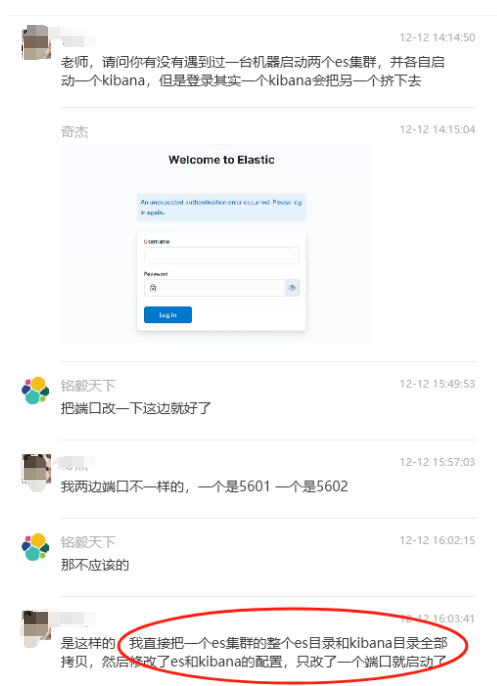
老师,请问你有没有遇到过一台机器启动两个 es 集群,并各自启动一个 kibana,但是登录其实一个 kibana 会把另一个挤下去。
是这样的,我直接把一个 es 集群的整个 es 目录和 kibana 目录全部拷贝,然后修改了 es 和 kibana 的配置,只改了一个端口就启动了。

2.2 问题拆解
直接拷贝整个Elasticsearch和Kibana目录然后仅修改端口配置确实可能是问题的根源。
这种做法可能导致了几个潜在的问题:
潜在问题1——配置文件的重复。
仅仅修改端口可能不足以完全隔离两个集群。Elasticsearch 和 Kibana 的配置文件中包含多个设置项,不仅仅是端口。
例如,Elasticsearch的集群名称、节点名称、路径设置等,Kibana的 Elasticsearch 连接设置、安全设置等,都需要根据第二个集群的特定需求进行调整。
潜在问题2——数据和状态文件的冲突。
如果直接复制了整个目录,那么其中的一些数据和状态文件也会被复制。
这可能导致两个集群之间的数据冲突,特别是如果这些文件包含了特定于集群的信息(如集群状态、节点ID、日志文件等)。
潜在问题3:安全和会话设置的冲突。
Kibana的安全设置(如加密密钥)在两个实例之间可能会发生冲突,特别是如果它们都使用默认设置的话。
这可能解释了为什么登录一个Kibana实例会影响另一个实例。产生问题所说的现象。
2.3 解决方案探讨
要说明一下,我直接直播录课的视频中两个节点、三个节点也都是1台云服务器部署两个或三个节点,但没有出现上面的问题。
核心在于:从第一个节点拷贝到第二个、第三个节点的时候,直接清空了 data 路径下的一切文件,是狠狠的 rm -rf,然后修改的配置。这样能确保万无一失。
当然,为了解决这个问题,可以采取以下步骤:
独立安装:而不是复制现有的目录,最好是从头开始为第二个集群独立安装Elasticsearch和Kibana。这样可以确保所有配置都是独立和清晰的。
仔细检查配置文件:确保两个集群的所有配置文件都已经根据各自的需求进行了适当的修改。这包括但不限于端口号,还有集群名称、节点名称、路径设置等。
区分数据目录:确保两个Elasticsearch集群的数据目录是分开的,以避免数据冲突。
单独的会话和安全设置:对于Kibana,确保每个实例有自己的会话和安全设置,这可能包括server.basePath、xpack.security.encryptionKey等。
浏览器会话共享:当你在同一浏览器中登录两个不同的Kibana实例时,可能会发生会话共享问题。这是因为Kibana默认使用相同的会话cookie,所以登录一个实例可能会覆盖或干扰另一个实例的会话。解决方法是使用不同的浏览器或浏览器的隐身/无痕模式来访问不同的Kibana实例,或者更改Kibana的会话cookie设置。这种概率也存在,不妨也尝试一下。
资源竞争:在同一台机器上运行两个集群可能导致资源竞争(CPU、内存等)。确保机器有足够的资源来同时运行两个集群。这种硬件配置的确认是大前提。
相信采取这些措施后,两个集群应该能够独立运行,互不干扰。
3、数据冲突问题:全量刷新索引丢失数据
3.1 问题背景描述
定时任务全量刷新索引部分数据丢失,使用 api bluk 方式批量写入,返回成功条数与写入条数一致。但是在索引里查询不到这条数据。
刷新频率:默认1秒。
bluk大小:1000条数据。
问题现象:周五 周六 周日 三天定时任务观察,都会丢失固定的“品”(解释一下:这里指存储的数据),不是随机丢失,观察日志没有报错。

3.2 问题拆解
这个我与球友做过多次交流,大致根据最终结果:“数据不一致”猜测可能的原因。
现象在于:数据 bulk 写入了,写入过程也没有报错,但是结果却查询不到。
大致猜测问题可能出在:
写入失败,中间环节可能报错,需要打印 bulk 写入结果响应日志排查。
刷新频率的问题,是不是不是默认的 1s,待核查确认。
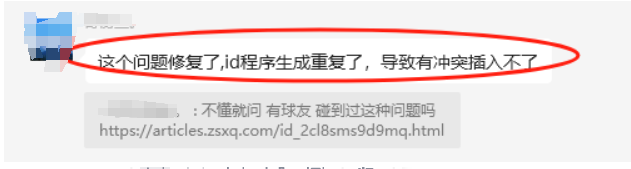
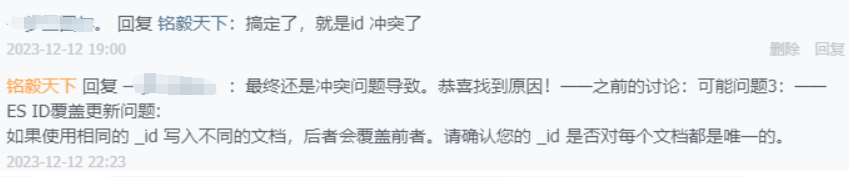
数据更新问题,相同 id 导致后面写入的覆盖前面的数据(Elasticsearch 更新机制决定)。
3.3 问题解决
3.4 为什么系统自带id 比咱们自己定义的 id 要好呢?
在处理 Elasticsearch 集群时,选择如何生成文档的唯一标识符(ID)是一个重要的设计决策。虽然有时可能会考虑使用自定义程序生成的ID,但通常推荐使用 Elasticsearch 自己生成的ID。
以下是几个主要原因:
第一,从性能优化层面来讲,Elasticsearch 自动生成的ID经过了专门的优化,旨在减少数据插入时的性能开销。
这些ID根据特定的规则设计,以最小化新文档插入对索引结构的影响。这意味着,使用 Elasticsearch 生成的ID可以更高效地管理数据索引,从而提高整体性能。
第二:分布式环境中的唯一性保证。
在分布式系统中,确保ID全局唯一是一个技术挑战。Elasticsearch 的内部机制可以保证在分布式环境下生成的ID是全局唯一的,避免了需要实现复杂逻辑来防止ID冲突的必要。
我不止一次收到过类似自定义 ID 重复的问题,当然本文提及的问题本质也是 ID 重复所致。
第三:减少索引碎片化
Elasticsearch 使用的ID生成机制有助于减少索引碎片化。
如果自定义ID不是随机的,可能导致数据在分片之间分布不均,某些分片可能承载更多数据,进而影响查询和存储性能。
第四:简化应用程序设计 采用 Elasticsearch 自动生成的ID可以简化应用程序的设计。不需要额外考虑ID生成的逻辑,开发者可以将更多的精力集中在核心业务逻辑上,从而提高开发效率和减少错误。
第五:避免文档重复插入 使用 Elasticsearch 自动生成的 ID 有助于避免文档的重复插入。因为即使内容相同,不同的文档也会被分配不同的ID,除非显式指定。这样就减少了数据冗余和混淆的可能性。
然而,“不能一杆子打死”,也有一些场景下自定义ID是有意义的:
场景一:业务需求。
如果业务逻辑需要根据特定的ID访问或关联数据,例如,如果文档的ID与其他系统中的实体ID相对应。。
场景二:数据去重。
如果需要防止相同数据的重复插入,可以使用自定义ID来实现。这在数据同步或集成场景中尤其常见。
例如,咱们之前文章多次提及过的 MySQL 等数据库同步 Elasticsearch 场景。
3.5 小结
综上所述,在决定是否使用自定义ID之前,需要考虑上述因素,并根据具体的应用场景和需求来做出决定是否使用自定义的 ID。使用 Elasticsearch 自动生成的ID不仅有助于提升性能,还能确保数据的一致性和唯一性,同时简化系统的设计和维护。这些优点使得在大多数情况下,使用系统生成的ID成为了一个更明智的选择。
推荐阅读

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!


















 1923
1923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











