







转载:http://blog.csdn.net/churximi/article/details/50917322
备注:python 2.7.9,32位
有些网站需要登录后才能爬取所需要的信息,此时可以设计爬虫进行模拟登录,原理是利用浏览器cookie。
一、浏览器访问服务器的过程:
(1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request);
(2)Web服务器收到请求,发回响应信息(Http Response);
(3)浏览器解析内容呈现给用户。
二、利用Fiddler查看浏览器行为信息:
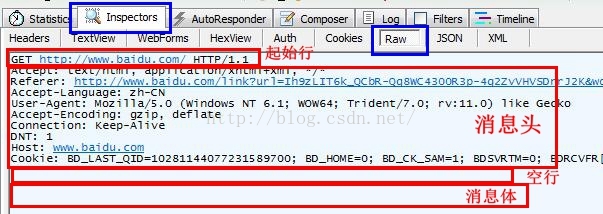
Http请求消息:
(1)起始行:包括请求方法、请求的资源、HTTP协议的版本号
这里GET请求没有消息主体,因此消息头后的空白行中没有其他数据。
(2)消息头:包含各种属性
(3)消息头结束后的空白行
(4)可选的消息体:包含数据
Http响应消息:
(1)起始行:包括HTTP协议版本,http状态码和状态
(2)消息头:包含各种属性(3)消息体:包含数据
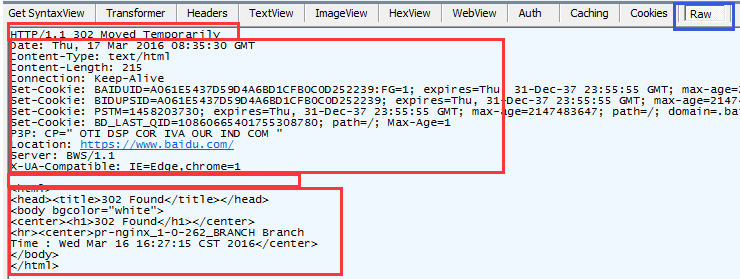
从上面可见,cookie在Http请求和Http响应的头消息中是很重要的属性。
三、什么是cookie:
当用户通过浏览器首次访问一个域名时,访问的Web服务器会给客户端发送数据,以保持Web服务器与客户端之间的状态,这些数据就是Cookie。
它是站点创建的,为了辨别用户身份而储存在用户本地终端上的数据,其中的信息一般都是经过加密的,存在缓存或硬盘中,在硬盘中是一些小文本文件。
当访问该网站时,就会读取对应网站的Cookie信息。
作用:记录不同用户的访问状态。
四、操作过程:
在知乎登录界面输入用户名和密码,然后登录。
利用Fiddler来查看这期间浏览器和知乎服务器之间的信息交互。
(1)浏览器给服务器发送了一个POST,携带帐号和密码等信息;
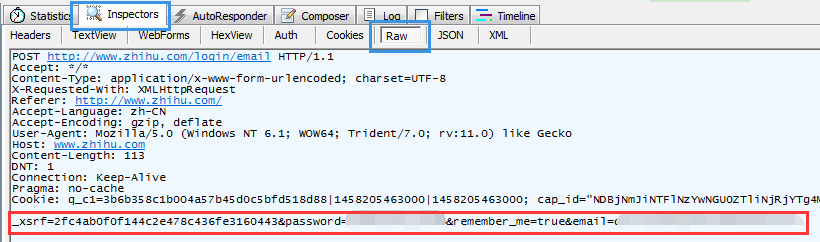
从起始行可见,POST是发送给http://www.zhihu.com/login/email这个网址,内容在最下面消息体里,
也可以在Fiddler的Webforms标签下查看POST的内容,如下:
可以发现,信息里不仅有帐号(email)和密码(password),其实还有_xsrf(具体作用往后看)和remember_me(登录界面的“记住我”)两个值。
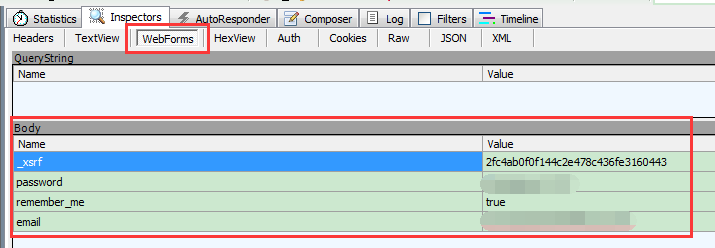
那么,在python爬虫中将这些信息同样发送,就可以模拟登录。
在发送的信息里出现了一个项:_xsrf,值为2fc4ab0f0f144c2e478c436fe3160443
这个项其实是在访问知乎登录网页https://www.zhihu.com/#signin时,网页发送过来的信息,在浏览器源码中可见:
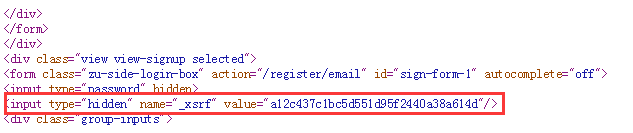
所以需要先从登录网址https://www.zhihu.com/#signin获取这个_xsrf的值,
并连同帐号、密码等信息再POST到真正接收请求的http://www.zhihu.com/login/email网址。
(2)获取_xsrf的值:
爬取登录网址https://www.zhihu.com/#signin,从内容中获取_xsrf的值。
正则表达式。
(3)发送请求:
xsrf = 获取的_xsrf的值
data = {“email”:”xxx”,”password”:”xxx”,”_xsrf”:xsrf}
login = s.post(loginURL, data = data, headers = headers)
loginURL:是真正POST到的网址,不一定等同于登录页面的网址;
(4)爬取登录后的网页:
response = s.get(getURL, cookies = login.cookies, headers = headers)
getURL:要爬取的登陆后的网页;
login.cookies:登陆时获取的cookie信息,存储在login中。
(5)输出内容:
print response.content
五、具体代码:
- # -- coding:utf-8 --
- # author:Simon
- # updatetime:2016年3月17日 17:35:35
- # 功能:爬虫之模拟登录,urllib和requests都用了…
- import urllib
- import urllib2
- import requests
- import re
- headers = {’User-Agent’:‘Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11’}
- def get_xsrf():
- firstURL = ”http://www.zhihu.com/#signin”
- request = urllib2.Request(firstURL,headers = headers)
- response = urllib2.urlopen(request)
- content = response.read()
- pattern = re.compile(r’name=”_xsrf” value=”(.?)”/>’,re.S)
- _xsrf = re.findall(pattern,content)
- return _xsrf[0]
- def login(par1):
- s = requests.session()
- afterURL = ”https://www.zhihu.com/explore” # 想要爬取的登录后的页面
- loginURL = ”http://www.zhihu.com/login/email” # POST发送到的网址
- login = s.post(loginURL, data = par1, headers = headers) # 发送登录信息,返回响应信息(包含cookie)
- response = s.get(afterURL, cookies = login.cookies, headers = headers) # 获得登陆后的响应信息,使用之前的cookie
- return response.content
- xsrf = get_xsrf()
- print “_xsrf的值是:” + xsrf
- data = {”email”:“xxx”,“password”:“xxx”,“_xsrf”:xsrf}
- print login(data)
# -- coding:utf-8 -*-author:Simon
updatetime:2016年3月17日 17:35:35
功能:爬虫之模拟登录,urllib和requests都用了...
import urllib
import urllib2
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'}
def get_xsrf():
firstURL = "http://www.zhihu.com/#signin"
request = urllib2.Request(firstURL,headers = headers)
response = urllib2.urlopen(request)
content = response.read()
pattern = re.compile(r'name="_xsrf" value="(.*?)"/>',re.S)
_xsrf = re.findall(pattern,content)
return _xsrf[0]
def login(par1):
s = requests.session()
afterURL = "https://www.zhihu.com/explore" # 想要爬取的登录后的页面
loginURL = "http://www.zhihu.com/login/email" # POST发送到的网址
login = s.post(loginURL, data = par1, headers = headers) # 发送登录信息,返回响应信息(包含cookie)
response = s.get(afterURL, cookies = login.cookies, headers = headers) # 获得登陆后的响应信息,使用之前的cookie
return response.content
xsrf = get_xsrf()
print "_xsrf的值是:" + xsrf
data = {"email":"xxx","password":"xxx","_xsrf":xsrf}
print login(data)
六、补充:
用知乎网做完试验,发现这里好像并不需要发送_xsrf这个值。
不过有的网站在登陆时确实需要发送类似这样的一个值,可以用上述方法。















 1606
1606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









